Java面试宝典主要包括:Java基础、Java Web、数据库、Mybatis框架、Spring框架、Spring MVC框架、Saas项目、SpringBoot框架、SpringCloud框架、乐优商城项目、十次方项目。
Java
一.Java基础
1.1 重载和重写的区别(了解)
重载 : 发生在同一个类中,方法名必须相同,参数类型不同,个数不同,顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
重写: 发生在父子类中,方法名,参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为 private 则子类就不能重写该方法。
1.2 String和StringBuffer,StringBuilder 的区别是什么?String
为什么是不可变的?(必会)
可变性 简单的来说:String类中使用 final 关键字字符数组保存字符串,private final char value[] ,所以 String对象是不可变的。
而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder类,在AbstractStringBuilder 中也是使用字符数组保存字符串 char[]value 但是没有用 final 关键字修饰, 所以这两种对象都是可变的。
StringBuilder 与 StringBuffer的构造方法都是调用父类构造方法也就是 AbstractStringBuilder实现的,大家可以自行查阅源码。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
}
线程安全性
String中的对象是不可变的,也就可以理解为常量,线程安全。
AbstractStringBuilder是 StringBuilder 与 StringBuffer 的公共父类,定义 了一些字符串的基本操作,如 expandCapacity.append.insert.indexOf 等公 共 方法。
StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以 是线程安全的。
StringBuilder 并没有对方法进行加同步锁,所以是非线程安全 的。
性能
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
}
每次对 String类型进行改变的时候,都会生成一个新的 String 对象,然 后将指针指向新的 String对象。
StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新 的对象并改变对象引用。相同情况下使用StirngBuilder相比使用 StringBuffer 仅能获得 10 %~ 15 %左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据 => 使用String
- 单线程操作字符串缓冲区下操作大量数据 => 使用StringBuilder
- 多线程操作字符串缓冲区下操作大量数据 => 使用StringBuffer
1.3 自动装箱与拆箱(了解)
装箱: 将基本类型用它们对应的引用类型包装起来;
拆箱: 将包装类型转换为基本数据类型;
1.4 ==与equals(必会)
** == **: 它的作用是判断两个对象的地址是不是相等。即: 判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)。
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况, 如下:
情况 1 :类没有覆盖 equals() 方法。则通过 equals() 比较该类的两 个对象时,等价于通过“==”比较这两个对象。
情况 2 :类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法 来两个对象的内容相等;若它们的内容相等,则返回 true(即,认为这两个对象 相等)。
public class test1 {
public static void main(String[] args) {
String a = new String("ab"); // a 为一个引用
String b = new String("ab"); // b 为另一个引用,对象的内容一样
String aa = "ab"; // 放在常量池中
String bb = "ab"; // 从常量池中查找
if (aa == bb) // true
System.out.println("aa==bb");
if (a == b) // false,非同一对象
System.out.println("a==b");
if (a.equals(b)) // true
System.out.println("aEQb");
if (42 == 42.0) // true
System.out.println("true");
}
}
说明: String中的 equals 方法是被重写过的,因为 object 的 equals 方法是 比较的对象的内存地址,而 String的equals 方法比较的是对象的值。 当创建 String类型的对象时,虚拟机会在常量池中查找有没有已经存在的 值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池 中重新创建一个 String对象。
1.5 关于final关键字的一些总结(必会)
final关键字主要用在三个地方:变量、方法、类。
- 对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其 指向另一个对象。
- 当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。
- 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。 在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过 于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
1.6 Java中的异常处理(了解)
在 Java中,所有的异常都有一个共同的祖先java.lang包中的 Throwable类 。
Throwable: 有两个重要的子类:
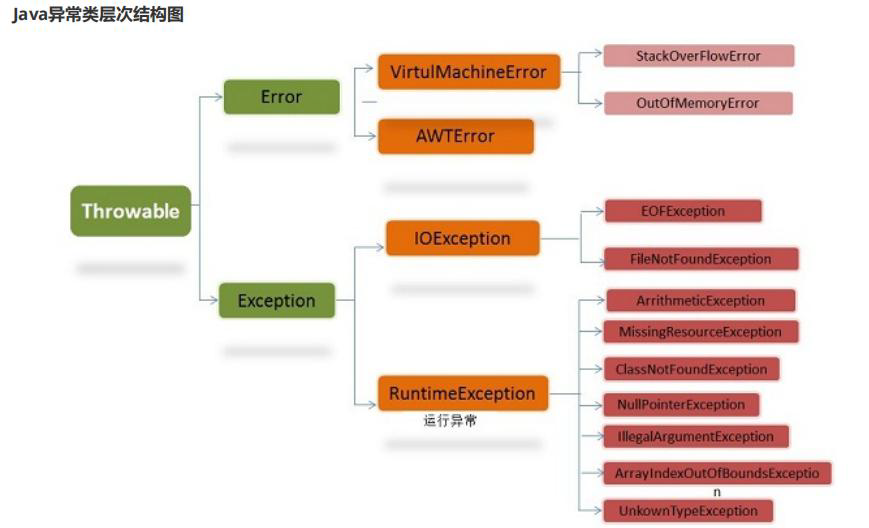
Exception(异常) 和 Error(错误) ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
1.7 error和exception的区别?(了解)
Error 类和 Exception 类的父类都是 Throwable 类,他们的区别如下。
Error 类一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空 间不足,方法调用栈溢出等。对于这类 错误的导致的应用程序中断,仅靠程序 本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
Exception 类表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异 常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。 Exception 类又分为运行时异常(RuntimeException)和受检查的异常 (CheckedException),运行时异常。
1.8 接口和抽象类的区别是什么(必会)
- 接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),抽象类可以有非抽象的方法。
- 接口中的实例变量默认是 final 类型的,而抽象类中则不一定。
- 一个类可以实现多个接口,但最多只能实现一个抽象类。
- 一个类实现接口的话要实现接口的所有方法,而抽象类不一定。
- 接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口 的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
备注: 在JDK 8 中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口,接口中定义了一样的默认方法,必须重写,不然会报错。
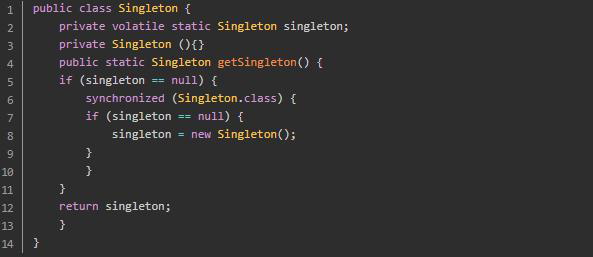
1.9 什么是单例模式?有几种?(必会)
单例模式:某个类的实例在 多线程环境下只会被创建一次出来。
单例模式有饿汉式单例模式、懒汉式单例模式和双检锁单例模式三种。
饿汉式 :线程安全,一开始就初始化。
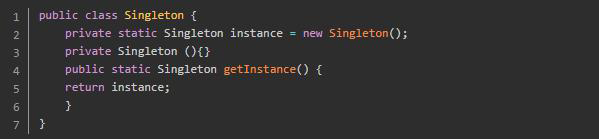
懒汉式 :非线程安全,延迟初始化。
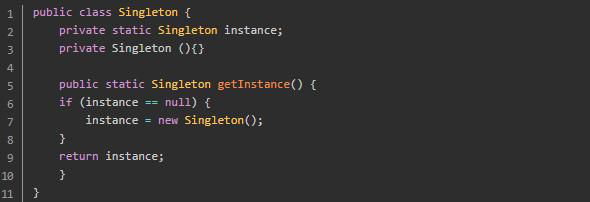
双检锁 :线程安全,延迟初始化。
1.10 手写冒泡排序?(必会)
public class Sort {
public static void sort() {
Scanner input = new Scanner(System.in);
int sort[] = new int[10];
int temp;
System.out.println("请输入10 个排序的数据:");
for (int i = 0; i < sort.length; i++) {
sort[i] = input.nextInt();
}
for (int i = 0; i < sort.length - 1; i++) {
for (int j = 0; j < sort.length - i - 1; j++) {
if (sort[j] < sort[j + 1]) {
temp = sort[j];
sort[j] = sort[j + 1];
sort[j + 1] = temp;
}
}
}
System.out.println("排列后的顺序为:");
for(int i=0;i<sort.length;i++){
System.out.print(sort[i]+"======");
}
}
public static void main(String[] args) {
sort();
}
}
1.11 BIO、NIO、AIO 有什么区别?(了解)
BIO:BlockIO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点 是模式简单使用方便,并发处理能力低。
NIO:NewIO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通 过 Channel(通道)通讯,实现了多路复用。
AIO:AsynchronousIO 是 NIO 的升级,也叫 NIO 2 ,实现了异步非堵 塞 IO ,异步 IO 的操作基于事件和回调机制。
1 12 常见的数据结构有哪些?(了解)
数组:
数组 是最常用的数据结构,数组的特点是 长度固定 , 可以用下标索引,并且所有的元素的类型都是一致的 。
数组常用的场景有:从数据库里读取雇员的信息存储为EmployeeDetail[];把一个字符串转换并存储到一个字节数组中便于操 作和处理等等。
尽量把数组封装在一个类里,防止数据被错误的操作弄乱。另外,这一点也适合其他的数据结构。
列表:
列表 和数组很相似,只不过它的 大小可以改变 。
列表 一般都是 通过一个固定大小的数组 来 实现 的,并且 会 在需要的时候 自动调整大小 。列表里 可以包含重复 的元素 。常用的场景有,添加一行新的项到订单列表里,把所有过期的商品移出商品列表等等。一般会把列表初始化成一个合适的大小,以减少调整大小的次数。
集合:
集合 和列表很相似,不过它 不能放重复的元素。
堆栈:
堆栈 只允许 对最后插入 的 元素进行操作 (也就是 后进先出 ,LastInFirstOut- LIFO)。如果你移除了栈顶的元素,那么你可以操作倒数第二个元素,依次 类推。这种后进先出的方式是通过仅有的 peek(),push()和pop() 这几个方法的强制性 限制达到的。
队列:
**队列** 和堆栈有些相似,不同之处在于在队列里 **第一个插入的
元素也是第一个被删除的元素** (即是 先进先出 )。这种先进先出的结构是通过只提供peek(),offer()和poll()这几个方法来访问数据进行限制来达到的。
例如,排队等待公交车,银行或者超市里的等待列队等等,都是可以用队列来表示。
链表:
链表是一种由 多个节点组成的 数据结构,并且每个节点包含有数据以及指向下一个节点的引用,在双向链表里,还会有一个指向前一个节点的引用。
例如,可以用单向链表和双向链表来实现堆栈和队列,因为链表的两端都是可以进行插入和删除的动作的。当然,也会有在链表的中间频繁插入和删除节点的场景。
Apache的类库里提供了一个TreeList的实现,它是链表的一个很好的替代,因为它只多占用了一点内存,但是性能比链表好很多。也就是说,从这点来看链表其实不是一个很好的选择。
1.13 Java集合体系有什么?(必会)
集合类存放于 Java.util 包中,主要有 3 种:set(集)、list(列表包含 Queue)和 map(映射)。
- Collection:Collection 是集合 List、Set、Queue 的最基本的接口。
- Iterator:迭代器,可以通过迭代器遍历集合中的数据。
- Map:是映射表的基础接口。
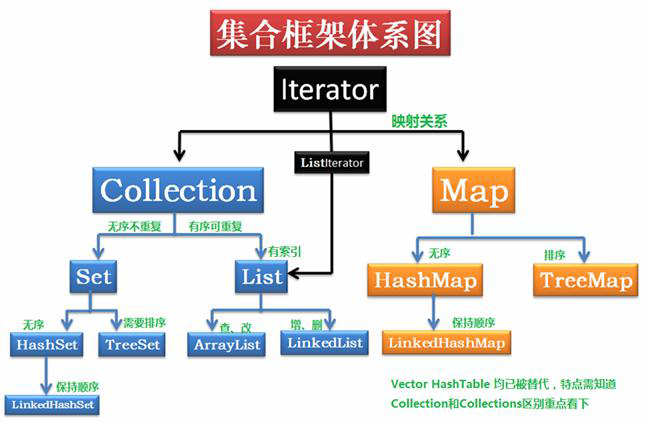
1 .Iterator接口
Iterator 接口是一个用于遍历集合中元素的接口,主要包含 hashNext(),next(),remove() 三种方法。如果实现Iterator接口,那么在遍历集合中元素的时候,只能往后遍历,被遍历后的元素不会在遍历到,通常 无序集合实现的都是这个接口 ,比如HashSet,HashMap
2 .LinkedIterator接口:
LinkedIterator 在 Iterator 的 基 础 上 又 添 加 了add(),previous(),hasPrevious() 三种方法,那些元素 有序的集合 ,实现的 一般都是LinkedIterator接口 ,实现这个接口的集合可以双向遍历,既可以通过next()访问下一个元素 ,又可以通过 previous()访问前一个元素 ,比如ArrayList。
3 .Collection(集合的最大接口)继承关系
List 可以存放重复的内容
Set 不能存放重复的内容,所以的重复内容靠hashCode()和equals()两个方法区分
Queue 队列接口
SortedSet可以对集合中的数据进行排序
Collection定义了集合框架的共性功能:
 add方法的参数类型是Object。以便于接收任意类型对象。
集合中存储的都是对象的引用(地址)。
add方法的参数类型是Object。以便于接收任意类型对象。
集合中存储的都是对象的引用(地址)。
4 .List
凡是可以操作角标的方法都是该体系特有的方法:
 ArrayList 线程不安全,查询速度快
ArrayList 线程不安全,查询速度快
Vector 线程安全,但速度慢,已被ArrayList替代
LinkedList 链表结果,增删速度快
TreeList 树型结构,保证增删复杂度都是O(logn),增删性能远高于 ArrayList和LinkedList,但是稍微占用内存
5 .Set
Set:元素是 无序 (存入和取出的顺序不一定一致),元素 不可以重复 。
HashSet: 底层 数据结构是 哈希表, 是 线程不安全 的, 数据不同步。
HashSet是如何 保证元素唯一性 的呢?
是通过元素的两个方法, hashCode和equals 来完成。
如果元素的HashCode值相同,才会判断equals是否为true。 如果元素的hashcode值不同,不会调用equals。
注意,对于判断元素是否存在,以及删除等操作,依赖的方法是元素的 hashcode和equals方法。
TreeSet: 底层 数据结构是 二叉树 ,存放 有序 :TreeSet 线程不安全 可以对Set集合中的元素进行排序。通过compareTo或者compare方法来保证元素的唯一性。
6 .Map
Correction、Set、List接口都属于单值的操作,而Map中的每个元素都使 用key——>value的形式存储在集合中。
Map集合:该集合存储键值对,是key:value一对一对往里存, 而且要保证
键的唯一性。

Map接口的常用子类
HashMap: 底层 数据结构是 哈希表 ,允许使用 null 值和 null 键,该集合是数据不同步的,将hashtable替代,jdk 1.2.效率高。
TreeMap: 底层 数据结构是 二叉树, 线程不同步,可以用于给map集合中的键进行排序。
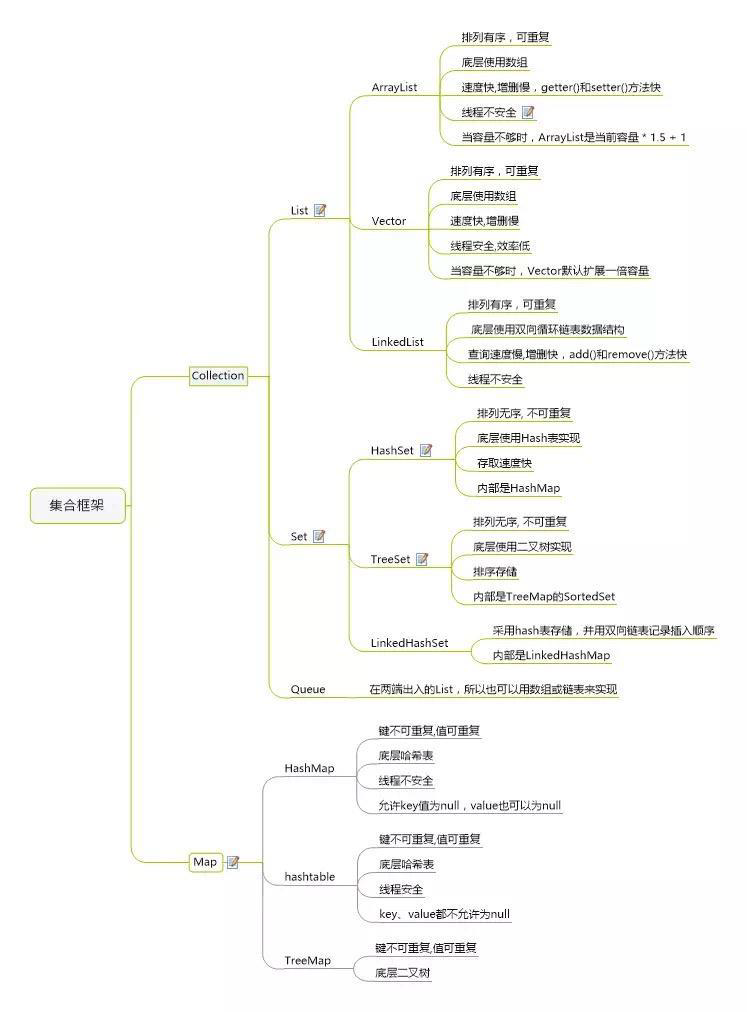
1.14 List的三个子类的特点(必会)
- ArrayList 底层结构是数组,底层查询快,增删慢
- LinkedList 底层结构是链表型的,增删快,查询慢
- Voctor底层结构是数组 线程安全的,增删慢,查询慢
1.15 List和Map、Set的区别(必会)
结构特点:
List 和 Set 是存储单列数据的集合,Map 是存储键和值这样的双列数据的集合;
List 中存储的数据是有顺序,并且允许重复;
Map 中存储的数据是没有顺序的,其键是不能重复的,它的值是可以有重 复的,
Set中存储的数据是无序的,且不允许有重复,但元素在集合中的位置由 元素的 hashcode 决定,位置是固定的(Set 集合根据 hashcode来进行数据的存储,所以位置是固定的,但是位置不是用户可以控制的,所以对于用户来说 set 中的元素还是无序的);
实现类 List 接口 有三个实现类(
LinkedList :基于链表实现,链表内存是散乱的,每一个元素存储本身内存地址的同时还存储下一个元素的地址。链表增删快,查找慢;
ArrayList :基于数组实现,非线程安全的,效率高,便于索引,但不便于插入删除;
Vector :基于数组实现,线程安全的,效率低)。
Map 接口 有三个实现类(
HashMap :基于 hash 表的 Map 接口实现,非线程安全,高效,支持 null 值和 null键;
HashTable :线程安全,低效,不支持 null 值和 null 键;
LinkedHashMap :是 HashMap 的一个子 类,保存了记录的插入顺序;SortMap 接口:TreeMap,能够把它保存的记录根据键排序,默认是键值的升序排序)。
Set 接口 有两个实现类(
HashSet :底层是由 HashMap 实现,不允 许集合中有重复的值,使用该方式时需要重写 equals()和 hashCode()方法;
LinkedHashSet:继承与 HashSet,同时又基于 LinkedHashMap 来进行实 现,底层使用的是 LinkedHashMp)。
1.16 HashMap底层实现原理(必会)
HashMap根据键的hashCode值存储数据,大多数情况下可以直接定位到 它的值.因而具有很快的访问速度,但是遍历顺序却不确定的.HashMap最多只允许一条记录的键为null,允许多条记录的值为null。
HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。
如果需要满足线程安全,可以用Collections的synchronizedMap方法使 HashMap具有线程安全的能力,或者使ConcurrentHashMap,HashTable. 如下详细介绍。
JDK 1. 8 之前 (数组+链表)
最开始存入数据的时候
- JDK 1. 8 之前HashMap底层是数组和链表结合在一起使用,也就是链表散列.数组的长度规定是 2 的幂.数组中存放的对象Entry<key,value>对象 ,不允许有重复的key存在,为什么呢?
- 首先,先判断key存放的位置,HashMap通过key的hashCode经过扰动函 数处理过后得到hash值,然后通过(n- 1 )&hash判断当前元素存放的位置(这里的n指的是数组的长度). 也可以理解:key%数组长度=对应数组的索引下标.然后将value存入到entry对象中。所谓扰动函数知道就是HashMap的hash方法.使用hash方法也就是扰动函数是为了防止一些实现比较差的hashCode()方法,换句话说使用扰动函数之后可以减少碰撞。
- 为什么使用(n- 1 )&length长度呢? ( 1 )保证数组不会越界: 首先我们要知道,在HashMap和ConcurrentHashMap中,数组的长度按规 定一定是 2 的幂( 2 的n次方)因此,数组的长度的二进制形式是: 10000 … 000 , 1 后 面有一堆 0 。那么tab.length- 1 的二进制形式就是 01111 … 111 , 0 后面有一堆 1 。最高位是 0 , 和hash值相"与",结果值一定不会比数组的长度值大,因此也就不会发生数组越界. ( 2 )保证元素尽可能的均匀分布 在操作的时候,链表中的元素越多,效率越低,因为要不停的对链表循环比较. 所以,一定要使哈希均匀分布,尽量减少哈希冲突,提高效率
继续存入数据
继续存入数据,还是要通过第 1 步计算key在数组中的索引位置. 如果当前位置存在元素的话,再通过key的equal()方法判断key是否相同,如果相同value值就会覆盖; 如果key的equals()方法不同,则在数组对应索引位置变为链表存储新的Entry<key,value>。
拉链法
上一步说到的链表是拉链法: 将链表和数组相结合.也就是说创建一个链表
数组,数组中每一格就是一个链表.若约到哈希冲突,则将冲突的值加到链表中即可.
JDK 1. 8 之后(数组+链表+红黑树)
如果链表的长度超过 8 则转为红黑树,当红黑树中的元素小于 6 时又变为链表(有这些变化的原因就是综合时间复杂度以及空间复杂度的考虑)获取时,直接找到key的hash值对应的下标,在进一步用equels方法判断key是否相同,从而找到对应值则返回找不到则返回null。
相比于之前的版本,jdk 1. 8 在解决哈希冲突时有了较大的变化,当链表长度大于阀值(默认为 8 )时,将链表转化为红黑树,以减少搜索时间。
1.17 谈一下 hashMap 中什么时候需要进行扩容,扩容 resize()又是如何实现的?(高薪常问)
调用场景:
- 初始化数组 table
- 当数组 table 的 size 达到阙值时进行扩容 实现过程:
通过判断旧数组的容量是否大于 0 来判断数组是否初始化过。
如果小于 0 :进行初始化,判断是否调用无参构造器。
如果调用了无参构造器: 使用默认的大小和阙值<阈值 12. 阀值=默认大小为 16 乘以负载因子 0. 75 。
如果没有调用无参构造器: 使用构造函数中初始化的容量, 当然这个容 量是经过tableSizefor 计算后的 2 的次幂数) 。
如果大于 0 : 进行扩容,扩容成两倍(小于最大值的情况下),之后在进行将元素重新进行与运算复制到新的散列表中。
概括的讲: 扩容需要重新分配一个新数组,新数组是老数组的 2 倍长,然后遍历整老 结构,把所有的元素挨个重新hash分配到新结构中去。PS:可见底层数据结构用到了数组,到最后会因为容量问题都需要进行扩容操作。
1.18 ConcurrentHashMap特点(高薪常问)
Segment 段
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并 发操作,所以要复杂一些。整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分”或”一段“的意思,所以很多地方都会将其描述为分段锁。
注意,行文中,我很多地方用了“槽”来代表一个segment。
线程安全(Segment 继承 ReentrantLock 加锁)
简单理解就是,ConcurrentHashMap是一个 Segment 数组,Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个segment,这样只要保证每个Segment 是线程安全的,也就实现了全局的线程安全。
并行度(默认 16 )
concurrencyLevel:并行级别、并发数、Segment 数,怎么翻译不重要, 理解它。默认是 16 ,也就是说 ConcurrentHashMap有 16 Segments, 所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
Java 8 实现 (引入了红黑树)
Java 8 对 ConcurrentHashMap进行了比较大的改动,Java 8 也引入了红黑树
1.19 HashTable(了解)
Hashtable 是遗留类,很多映射的常用功能与 HashMap类似,不同的是 它承自 Dictionary 类,并且是线程安全的,任一时间只有一个线程能写 Hashtable,并发性不如 ConcurrentHashMap,因ConcurrentHashMap 引入了分段锁。Hashtable 不建议在新代码中使用,不需要线程安全的场合可以用 HashMap 替换,需要线程安全的场合可以ConcurrentHashMap 替换。
1.20 HashMap 和HashTable有什么区别?(必会)
HashMap 是线程不安全的,HashMap 是一个接口,是 Map 的一个子接 口,是将键映射到值得对象,不允许键值重复,允许空键和空值;由于非线程安 全,HashMap 的效率要较 HashTable 的效率高一些. HashTable 是线程安全的一个集合,不允许 null 值作为一个 key 值或者 Value 值; HashTable 是 sychronize,多个线程访问时不需要自己为它的方法实现同 步,而 HashMap 在被多个线程访问的时候需要自己为它的方法实现同步;
1. 21 HashMap,HashTable,ConcurrentHashMap之间的区别,及性能对比(必会)
性能:
ConcurrentHashMap( 线程安全 )>HashMap>HashTable( 线程安全 )
区别对比一(HashMap和HashTable区别):
- HashMap是非线程安全的,HashTable是线程安全的。
- HashMap的键和值都允许有null值存在,而HashTable则不行。
- 因为线程安全的问题,HashMap效率比HashTable的要高。
- Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。一般现在不建议用HashTable,
①是HashTable是遗留类,内部实现很多没优化和冗余。
②即使在多线程环境下,现在也有同步的ConcurrentHashMap替代,没有必要因为是多线程而用HashTable。
区别对比二(HashTable和ConcurrentHashMap区别):
HashTable使用的是Synchronized关键字修饰,
ConcurrentHashMap 是使用了锁分段技术来保证线程安全的。
Hashtable 中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而 ConcurrentHashMap 中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为 16 个桶,诸如get、putremove 等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有 16 个写线程执行,并发性能的提升是显而易见的。
1. 22 什么是线程?线程和进程的区别?(必会)
线程: 是进程的一个实体,是 cpu 调度和分派的基本单位,是比进程更小的 可以独立运行的基本单位。 进程: 具有一定独立功能的程序关于某个数据集合上的一次运行活动,是操作 系统进行资源分配和调度的一个独立单位。 特点: 线程的划分尺度小于进程,这使多线程程序拥有高并发性,进程在运行 时各自内存单元相互独立,线程之间 内存共享,这使多线程编程可以拥有更好 的性能和用户体验。
注意 :多线程编程对于其它程序是不友好的,占据大量 cpu 资源。
1 23 创建线程有几种方式(必会)…………………………………………………………………………….
1 .继承 Thread 类 Thread 类本质上是实现了 Runnable 接口的一个实例,代表一个线程的 实例。启动线程的唯一方法就是通过 Thread 类的 start()实例方法。 start()方 法是一个 native 方法 ,它将启动一个新线程,并执行 run()方法。
2 .实现Runnable接口 如果自己的类已经 extends 另一个类,就无法直接 extendsThread,此 时,可以实现 一个 Runnable接口。
3 .实现Callable接口 Callabled接口有点儿像是Runnable接口的增强版,它 以call()方法作为 线程执行体 , call()方法比run()方法功能更强大。 call()方法可以有返回值,可以声明抛出异常类 。 获取call()方法里的返回值: 通过FutureTask类(实现Future接口)的实 例对象的get()方法得到,得到结果类型与创建TutureTask类给的泛型一致。 具体代码实现
1 .定义实现Callable接口的实现类,并实现call()方法。注意:Callable 有泛型限制,与返回值类型一致。这里是Integer publicclassThirdThreadimplementsCallable{//重写call()方法} 2 .再创建Callable实现类的实例tt。 ThirdThreadtt=newThirdThread(); 3 .使用FutureTask类包装Callable的实例tt。 FutureTasktask=newFutureTask(tt);//注意:泛型限制与返回结果一 致。
4 .以FutureTask对象(task)作为Thread的target来创建线程,并启 动。 newThread(task,“线程”).start();
5 .调用FutureTask对象(task)的get()方法获得返回值
Integerresult=task.get();//会有异常
4. 通过线程池方法 什么是线程池,如何使用? 线程池就是事先将多个线程对象放到一个容器中,当使用的时候就不用 new 线 程而是直接去池中拿线程即可,节省了开辟子线程的时间,提高的代码执行效率。 在 JDK的 java.util.concurrent.Executors 中提供了生成多种线程池的静态 方法.
然后调用他们的 execute方法即可。 合理利用线程池能够带来三个好处。 第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消 耗。 第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执 行。 第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗 系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监 控. 常用的线程池有哪些? newSingleThreadExecutor: 创建一个单线程的线程池,此线程池保证所有 任务的执行顺序按照任务的提交顺序执行。 newFixedThreadPool: 创建固定大小的线程池,每次提交一个任务就创建一 个线程,直到线程达到线程池的最大大小。 newCachedThreadPool: 创建一个可缓存的线程池,此线程池不会对线程池 大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大 线程大小。 newScheduledThreadPool: 创建一个大小无限的线程池,此线程池支持定时 以及周期性执行任务的需求。
1 24 线程的基本方法有什么?(必会)……………………………………………………………………….
线程相关的基本方法有 wait,notify,notifyAll,sleep,join,yield 等。
1 .线程等待(wait) 调用该方法的线程进入 WAITING 状态,只有等待另外线程的通知或被中 断才会返回,需要注意的是调用 wait()方法后, 会释放对象的锁 。因此,wait 方 法一般用在同步方法或同步代码块中。
2 .线程睡眠(sleep) sleep 导致当前线程休眠,与 wait 方法不同的是 sleep 不会释放当前占 有的锁,sleep(long)会导致线程进入 TIMED-WATING 状态,而 wait()方法 会导致当前线程进入 WATING 状态. 3 .线程让步(yield) yield会使当前线程 让出 CPU 执行时间片 ,与其他线程一起重新竞争 CPU 时间片。一般情况下,优先级高的线程有更大的可能性成功竞争得到 CPU 时间片,但这又不是绝对的,有的操作系统对 线程优先级并不敏感。
4 .线程中断(interrupt) 中断一个线程,其本意是 给这个线程一个通知信号,会影响这个线程内部的 一个中断标识位。这个线程本身并不会因此而改变状态(如阻塞,终止等) 5 .Join 等待其他线程终止 join()方法,等待其他线程终止 ,在当前线程中调用一个线程的 join() 方 法,则当前线程转为阻塞状态,回到另一个线程结束,当前线程再由阻塞状态变 为就绪状态,等待 cpu 的宠幸. 6 .线程唤醒(notify) Object 类中的 notify() 方法, 唤醒在此对象监视器上等待的单个线程 ,如 果所有线程都在此对象上等待,则会选择唤醒其中一个线程,选择是任意的,并 在对实现做出决定时发生,线程通过调用其中一个 wait() 方法,在对象的监视 器上等待, 直到当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程 , 被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争。类 似的方法还有 notifyAll() ,唤醒再次监视器上等待的所有线程。
1 25 在java 中wait和sleep 方法的不同?(必会)……………………………………………
最大的不同是在等待时 wait 会释放锁,而 sleep 一直持有锁。wait 通常 被用于线程间交互,sleep 通常被用于暂停执行。
1 26 线程池原理(高薪常问)……………………………………………………………………………………
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队
列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量 超出数量的
线程排队等候 ,等其它线程执行完毕,再从队列中取出任务来执行。他的主要特
点为: 线程复用;控制最大并发数;管理线程。
线程复用:
每一个 Thread 的类都有一个 start 方法。 当调用 start 启动线程时 Java虚拟机会调用该类的 run 方法。 那么该类的 run() 方法中就是调用了 Runnable对象的 run() 方法。 我们可以继承重写 Thread 类,在其 start 方法中添加不断循环调用传递过来的 Runnable 对象 。 这就是线程池的实现 原理。 循环方法中不断获取 Runnable 是用 Queue实现的 ,在获取下一个 Runnable之前可以是阻塞的。 线程池的组成: 一般的线程池主要分为以下 4 个组成部分:
- 线程池管理器:用于创建并管理线程池
- 工作线程:线程池中的线程
- 任务接口:每个任务必须实现的接口,用于工作线程调度其运行
- 任务队列:用于存放待处理的任务,提供一种缓冲机制 拒绝策略: 线程池中的线程已经用完了,无法继续为新任务服务,同时,等待队列也已 经排满了,再也塞不下新任务了。这时候我们就需要拒绝策略机制合理的处理这 个问题。 JDK内置的拒绝策略如下: 1 .AbortPolicy : 直接抛出异常,阻止系统正常运行。
2 .CallerRunsPolicy : 只要线程池未关闭,该策略直接在调用者线程中, 运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但是,任务提交线程的 性能极有可能会急剧下降。 3 .DiscardOldestPolicy : 丢弃最老的一个请求,也就是即将被执行的一 个任务,并尝试再次提交当前任务。 4 .DiscardPolicy : 该策略默默地丢弃无法处理的任务,不予任何处理。 如果允许任务丢失,这是最好的一种方案 Java线程池工作过程:
1. 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,
就算队列里面有任务,线程池也不会马上执行它们。
- 当调用 execute() 方法添加一个任务时,线程池会做如下判断: a) 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这 个任务; b) 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务 放入队列; c) 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务; d) 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常 RejectExecutionException。
- 当一个线程完成任务时,它会从队列中取下一个任务来执行。
- 当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判 断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以 线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
1 27 线程执行的顺序(高薪常问)…………………………………………………………………………….
1. 当线程数小于核心线程数时,会一直创建线程直到线程数等于核心线程数;
2. 当线程数等于核心线程数时,新加入的任务会被放到任务队列等待执行;
3. 当任务队列已满,又有新的任务时,会创建线程直到线程数量等于最大线程
数;
4. 当线程数等于最大线程数,且任务队列已满时,新加入任务会被拒绝。
1 28 线程池的核心参数有哪些?(高薪常问)…………………………………………………………..
默认参数:
corePoolSize= 1 queueCapacity=Integer.MAX_VALUE maxPoolSize=Integer.MAX_VALUE keepAliveTime= 60 秒 allowCoreThreadTimeout=false rejectedExecutionHandler=AbortPolicy()
具体讲解: 1 .corePoolSize(核心线程数) ( 1 )核心线程会一直存在,即使没有任务执行; ( 2 )当线程数小于核心线程数的时候,即使有空闲线程,也会一直创建线程直 到达到核心线程数; ( 3 )设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时 关闭。 2 .queueCapacity(任务队列容量) 也叫阻塞队列,当核心线程都在运行,此时再有任务进来,会进入任务队列,排 队等待线程执行。 3 .maxPoolSize(最大线程数) ( 1 )线程池里允许存在的最大线程数量;
( 2 )当任务队列已满,且线程数量大于等于核心线程数时,会创建新的线程执
行任务;
( 3 )线程池里允许存在的最大线程数量。当任务队列已满,且线程数量大于等
于核心线程数时,会创建新的线程执行任务。
4 .keepAliveTime(线程空闲时间) ( 1 )当线程空闲时间达到keepAliveTime时,线程会退出(关闭),直到线程 数等于核心线程数; ( 2 )如果设置了allowCoreThreadTimeout=true,则线程会退出直到线程数 等于零。<allowCoreThreadTimeout(允许核心线程超时)> 当线程数量达到最大线程数,且任务队列已满时,会拒绝任务; 调用线程池shutdown()方法后,会等待执行完线程池的任务之后,再 shutdown()。如果在调用了shutdown()方法和线程池真正shutdown()之间提 交任务,会拒绝新任务。
1 29 死锁产生的条件以及如何避免?(高薪常问)…………………………………………………….
死锁产生的四个必要条件:
互斥:一个资源每次只能被一个进程使用(资源独立)。
请求与保持:一个进程因请求资源而阻塞时,对已获得的资源保持不放(不
释放锁)。
不剥夺:进程已获得的资源,在未使用之前,不能强行剥夺(抢夺资源)。
循环等待:若干进程之间形成一种头尾相接的循环等待的资源关闭(死循
环)。
避免死锁:
1. 破坏”互斥”条件:系统里取消互斥、若资源一般不被一个进程独占使用,
那么死锁是肯定不会发生的,但一般“互斥”条件是无法破坏的,因此,在死锁
预防里主要是破坏其他三个必要条件,而不去涉及破坏“互斥”条件。
2. 破坏“请求和保持”条件:
方法 1 :所有的进程在开始运行之前,必须一次性的申请其在整个运行过程
各种所需要的全部资源。
优点:简单易实施且安全。
缺点:因为某项资源不满足,进程无法启动,而其他已经满足了的资源
也不会得到利用,严重降低了资源的利用率,造成资源浪费。
方法 2 :该方法是对第一种方法的改进,允许进程只获得运行初期需要的资
源,便开始运行,在运行过程中逐步释放掉分配到,已经使用完毕的资源,然后
再去请求新的资源。这样的话资源的利用率会得到提高,也会减少进程的饥饿问
题。
3. 破坏“不剥夺”条件:当一个已经持有了一些资源的进程在提出新的资源
请求没有得到满足时,它必须释放已经保持的所有资源,待以后需要使用的时候
再重新申请。这就意味着进程已占有的资源会被短暂的释放或者说被抢占了。
4. 破坏“循环等待”条件:可以通过定义资源类型的线性顺序来预防,可以
将每个资源编号,当一个进程占有编号为i的资源时,那么它下一次申请资源只 能申请编号大于i的资源。
1 30 JVM是什么?JVM的基本结构(高薪常问)……………………………………………………
虚拟机,一种能够运行java字节码的虚拟机。 类加载子系统 加载 .class 文件到内存。 内存结构 运行时的数据区。 执行引擎 执行内存中的.class,输出执行结果(包含GC:垃圾收集器)。 本地方法的接口。 本地方法库。
1 31 JVM内存结构(高薪常问)………………………………………………………………………………..
JDK 1. 7
程序计数器
就是一个指针,指向方法区中的方法字节码(用来存储指向下一个指令
的地址,也即将要执行的指令代码),由执行引擎读取下一条指令,是一个
非常小的内存空间,几乎可以忽略不计。
Java虚拟机栈 Java线程执行方法的内存模型,一个线程对应一个栈,每个方法在执行 的同时都会创建一个栈帧(用于存储局部变量表,操作数栈,动态链接,方法出 口等信息)不存在垃圾回收问题,只要线程一结束该栈就释放,生命周期和线程 一致。 本地方法栈 和栈作用很相似,区别不过是Java栈为JVM执行Java方法服务,而本 地方法栈为JVM执行native方法服务。登记native方法,在ExecutionEngine 执行时加载本地方法库。 堆 Java虚拟机管理的最大的一块内存区域,Java堆是线程共享的,用于存 放对象实例。也就是说对象的出生和回收都是在这个区域进行的。 方法区 线程共享,用于存储已经被虚拟机加载的类信息、常量、静态变量等数 据。 JDK 1. 8
JDK 1. 8 与 1. 7 最大的区别是在 1. 8 中方法区是由元空间(元数据区)来实现。
常量池移到堆中。
1 32 类的加载,类加载器的种类, 类加载机制(高薪常问)……………………………………….
类加载
1 .加载
将.class文件从磁盘读到内存。 2 .连接 2. 1 验证: 验证字节码文件的正确性。 2. 2 准备: 给类的静态变量分配内存,并赋予默认值。 2. 3 解析: 类装载器装入类所引用的其它所有类。 3 .初始化 为类的静态变量赋予正确的初始值,上述的准备阶段为静态变量赋予的是虚 拟机默认的初始值,此处赋予的才是程序编写者为变量分配的真正的初始值,执 行静态代码块。 4 .使用 5 .卸载 类加载器的种类
- 启动类加载器(BootstrapClassLoader) 负责加载JRE的核心类库,如JRE目标下的rt.jar,charsets.jar等。
- 扩展类加载器(ExtensionClassLoader) 负责加载JRE扩展目录ext中jar类包。
- 系统类加载器(ApplicationClassLoader) 负责加载ClassPath路径下的类包。
- 用户自定义加载器(UserClassLoader) 负责加载用户自定义路径下的类包。
类加载机制
全盘负责委托机制
当A类中引用B类,那么除非特别指定B类的类加载器,否则就直接使用
加载A类的类加载器加载B类。
双亲委派机制
指先委托父类加载器寻找目标类,在找不到的情况下再在自己的路径中查找
并载入目标类。
1 33 什么是GC(高薪常问)……………………………………………………………………………………..
内存空间是有限的,那么在程序运行时如何及时的把不再使用的对象清除将内存
释放出来,这就是GC要做的事。
GC的区域在哪里?
JVM中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,
栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理。因此,
我们的内存垃圾回收主要集中于 Java 堆和方法区中,在程序运行期间,这部分 内存的分配和使用都是动态的。 GC的操作对象是什么? 需要进行回收的对象就是已经没有存活的对象,判断一个对象是否存活常用 的有两种办法:引用计数和可达分析。 引用计数:每个对象有一个引用计数属性,新增一个引用时计数加 1 , 引用释放时计数减 1 ,计数为 0 时可以回收。此方法简单,无法解决对 象相互循环引用的问题。 可达性分析(ReachabilityAnalysis):从GCRoots开始向下搜索, 搜索所走过的路径称为引用链。当一个对象到GCRoots没有任何引用 链相连时,则证明此对象是不可用的。不可达对象。 在Java语言中,GCRoots包括: 虚拟机栈中引用的对象。 方法区中类静态属性实体引用的对象。 方法区中常量引用的对象。 本地方法栈中JNI引用的对象。 GC的时机是什么? ( 1 )程序调用System.gc时可以触发。
( 2 )系统自身来决定GC触发的时机(根据Eden区和FromSpace区的内存 大小来决定。当内存大小不足时,则会启动GC线程并停止应用线程)。 GC做了哪些事? 主要做了清理对象,整理内存的工作。 GC常用算法 GC常用算法有:标记-清除算法,标记-压缩算法,复制算法,分代收集算 法。目前主流的JVM(HotSpot)采用的是分代收集算法。 标记-清除算法 为每个对象存储一个标记位,记录对象的状态(活着或是死亡)。分为两个 阶段,一个是标记阶段,这个阶段内,为每个对象更新标记位,检查对象是否死 亡;第二个阶段是清除阶段,该阶段对死亡的对象进行清除,执行 GC 操作。 标记-压缩算法(标记-整理) 标记-压缩法是标记-清除法的一个改进版。同样,在标记阶段,该算法也将 所有对象标记为存活和死亡两种状态;不同的是,在第二个阶段,该算法并没有 直接对死亡的对象进行清理,而是将所有存活的对象整理一下,放到另一处空间, 然后把剩下的所有对象全部清除。这样就达到了标记-整理的目的。 复制算法 该算法将内存平均分成两部分,然后每次只使用其中的一部分,当这部分内 存满的时候,将内存中所有存活的对象复制到另一个内存中,然后将之前的内存 清空,只使用这部分内存,循环下去。 分代收集算法 现在的虚拟机垃圾收集大多采用这种方式,它根据对象的生存周期,将堆分 为新生代(Young)和老年代(Tenure)。在新生代中,由于对象生存期短,每次回 收都会有大量对象死去,那么这时就采用复制算法。老年代里的对象存活率较高, 没有额外的空间进行分配担保,所以可以使用标记-整理 或者 标记-清除。
1 34 JVM调优的工具有哪些?(高薪常问)………………………………………………………………
JDK 自带了很多监控工具,都位于 JDK的 bin 目录下,其中最常用 的是 jconsole和 jvisualvm 这两款视图监控工具。 1 .jconsole:用于对 JVM中的内存、线程和类等进行监控;
2 .jvisualvm:JDK 自带的全能分析工具,可以分析:内存快照、线程 快照、程序死锁、监控内存的变化、gc 变化等。
1 35 常用的JVM调优的参数都有哪些?(高薪常问)……………………………………………..
XX比X的稳定性更差,并且版本更新不会进行通知和说明。
- Xms:s为strating,表示堆内存起始大小。
- Xmx:x为max,表示最大的堆内存(一般来说-Xms和-Xmx的设置 为相同大小,因为当heap自动扩容时,会发生内存抖动,影响程序的稳定性)。
- Xmn:n为new,表示新生代大小(-Xss:规定了每个线程虚拟机栈 (堆栈)的大小)。
- XX:SurvivorRator= 8 表示堆内存中新生代、老年代和永久代的比为 8 : 1 : 1 。
- XX:PretenureSizeThreshold= 3145728 表示当创建(new)的对象大 于 3 M的时候直接进入。
- XX:MaxTenuringThreshold= 15 表示当对象的存活的年龄(minorgc 一次加 1 )大于多少时,进入老年代。
- XX:-DisableExplicirGC表示是否(+表示是,-表示否)打开GC日志。
二.JavaWeb………………………………………………………………………………………………………………………
2 1 JDBC技术………………………………………………………………………………………………………………..
2 1 1 说下原生JDBC操作数据库流程?(了解)…………………………………………………….
第一步:Class.forName()加载数据库连接驱动; 第二步:DriverManager.getConnection()获取数据连接对象; 第三步:根据 SQL 获取 sql 会话对象,有 2 种方式 Statement.PreparedStatement; 第四步:执行 SQL 处理结果集,执行 SQL 前如果有参数值就设置参数值 setXXX(); 第五步:关闭结果集.关闭会话.关闭连接。
2 1 2 说说事务的概念,在JDBC编程中处理事务的步骤。(了解)…………………………..
1. 事务是作为单个逻辑工作单元执行的一系列操作。
2. 一个逻辑工作单元必须有四个属性,称为原子性.一致性.隔离性和持
久性 (ACID) 属性,只有这样才能成为一个事务处理步骤:
3 .conn.setAutoComit(false);设置提交方式为手工提交
4 .conn.commit()提交事务
5. 出现异常,回滚 conn.rollback();
2 1 3 JDBC的脏读是什么?哪种数据库隔离级别能防止脏读?(了解)…………………….
当我们使用事务时,有可能会出现这样的情况,有一行数据刚更新,与此同
时另一个查询读到了这个刚更新的值。这样就导致了脏读,因为更新的数据还没
有进行持久化,更新这行数据的业务可能会进行回滚,这样这个数据就是无效的。
数据库的TRANSACTIONREADCOMMITTED,TRANSACTIONREPEATABL
EREAD和TRANSACTION_SERIALIZABLE隔离级别可以防止脏读。
3 1 网路通讯部分…………………………………………………………………………………………………………..
3 1 1 TCP与UDP区别?(必会)……………………………………………………………………………..
UDP:
a.是面向无连接, 将数据及源的封装成数据包中,不需要建立连接
b.每个数据报的大小在限制 64 k内
c.因无连接,是不可靠协议
d.不需要建立连接,速度快
TCP:
a.建立连接,形成传输数据的通道.
b.在连接中进行大数据量传输,以字节流方式
c.通过三次握手完成连接,是可靠协议
d 必须建立连接效率会稍低.聊天.网络视频会议就是UDP
3 1 2 说一下什么是Http协议?(必会)…………………………………………………………………..
客户端和 服务器端之间数据传输的格式规范,格式简称为“超文本传输协
议”。是一个基于请求与响应模式的.无状态的.应用层的协议,基于TCP的连接
方式。
3 1 3 get与post请求区别?(必会)……………………………………………………………………….
区别 1 :
get重点在从服务器上获取资源,post重点在向服务器发送数据; 区别 2 : get传输数据是通过URL请求,以field(字段)=value的形式,置于URL 后,并用"?“连接,多个请求数据间用”&“连接,如http:// 127. 0. 0. 1 /Test/LogI n.action?name=admin&password=admin,这个过程用户是可见的; post传输数据通过Http的post机制,将字段与对应值封存在请求实体中 发送给服务器,这个过程对用户是不可见的; 区别 3 :
Get传输的数据量小,因为受URL长度限制,但效率较高; Post可以传输大量数据,所以上传文件时只能用Post方式; 区别 4 : Get是不安全的,因为URL是可见的,可能会泄露私密信息,如密码等; Post较get安全性较高; 区别 5 : get方式只能支持ASCII字符,向服务器传的中文字符可能会乱码。 post支持标准字符集,可以正确传递中文字符。
3 1 4 http中重定向和请求转发的区别?(必会)………………………………………………………
本质区别: 转发是服务器行为,重定向是客户端行为。
重定向特点: 两次请求,浏览器地址发生变化,可以访问自己 web 之外的 资源,传输的数据会丢失。 请求转发特点: 一次请求,浏览器地址不变,访问的是自己本身的 web 资 源,传输的数据不会丢失。
4 1 Cookie和Session(必会)……………………………………………………………………………………….
Cookie 是 web 服务器发送给浏览器的一块信息,浏览器会在本地一个文 件中给每个 web 服务器存储 cookie。以后浏览器再给特定的 web服务器发 送请求时,同时会发送所有为该服务器存储的 cookie。 Session 是存储在 web 服务器端的一块信息。session 对象存储特定用户 会话所需的属性及配置信息。当用户在应用程序的 Web 页之间跳转时,存储 在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。 Cookie 和 session 的不同点: 1 .无论客户端做怎样的设置,session 都能够正常工作。当客户端禁用 cookie 时将无法使用 cookie。 2 .在存储的数据量方面:session 能够存储任意的 java 对象,cookie只 能存储 String类型的对象。
5 1 Jsp和Servlet………………………………………………………………………………………………………….
5 1 1 Servlet的执行流程(必会)………………………………………………………………………………
Servlet的执行流程也就是servlet的生命周期,当服务器启动的时候生 命周期开始,然后通过init()《启动顺序根据web.xml里的startup-on-load来 确定加载顺序》方法初始化servlet,再根据不同请求调用doGet或doPost方 法,最后再通过destroy()方法进行销毁。
5 1 2 Jsp和Servlet的区别(必会)…………………………………………………………………………..
你可以将JSP当做一个可扩充的HTML来对待。
虽然在本质上JSP文件会被服务器自动翻译为相应的Servlet来执行。 可以说Servlet是面向Java程序员而JSP是面向HTML程序员的,除此之 外两者功能完全等价。
5 1 3 JSP九大内置对象(了解)…………………………………………………………………………………
pageContext :只对当前jsp页面有效,里面封装了基本的request和 session的对象 Request :对当前请求进行封装 Session :浏览器会话对象,浏览器范围内有效 Application :应用程序对象,对整个web工程都有效 Out :页面打印对象,在jsp页面打印字符串 Response :返回服务器端信息给用户 Config :单个servlet的配置对象,相当于servletConfig对象 Page:当前页面对象,也就是this Exception :错误页面的exception对象,如果指定的是错误页面,这个就 是异常对象
5 1 4 JSP的三大指令(了解)…………………………………………………………………………………….
Page:指令是针对当前页面的指令
Include :用于指定如何包含另一个页面
Taglib:用于定义和指定自定义标签
5 1 5 七大动作(了解)………………………………………………………………………………………………
Forward:执行页面跳转,将请求的处理转发到另一个页面
Param :用于传递参数
Include :用于动态引入一个jsp页面
Plugin :用于下载javaBean或applet到客户端执行
useBean :使用javaBean
setProperty :修改javaBean实例的属性值
getProperty :获取javaBean实例的属性值
6 1 Ajax…………………………………………………………………………………………………………………………
6. 1. 1 谈谈你对 Ajax 的认识?(必会)
Ajax 是一种创建交互式网页应用的的网页开发技术;Asynchronous JavaScriptandXML”的缩写。 Ajax 的优势: 通过异步模式,提升了用户体验。 优化了浏览器和服务器之间的传输,减少不必要的数据往返,减少了带 宽占用。 Ajax 引擎在客户端运行,承担了一部分本来由服务器承担的工作,从而 减少了大用户量下的服务器负载。 Ajax 的最大特点: 可以实现局部刷新,在不更新整个页面的前提下维护数据,提升用户体 验度。
6 1 2 Ajax创建的过程?(了解)………………………………………………………………………….
1 .创建 XMLHttpRequest 对象,也就是创建一个异步调用对象
2 .创建一个新的 HTTP 请求,并指定该 HTTP 请求的方法、URL 及验证信
息
3 .设置响应 HTTP 请求状态变化的函数
4 .发送 HTTP 请求
5 .获取异步调用返回的数据
6 .使用 JavaScript 和 DOM 实现局部刷新
6 1 3 阐述一下异步加载JS?(了解)………………………………………………………………….
1 .异步加载的方案: 动态插入 script 标签
2 .通过 ajax 去获取 js代码,然后通过 eval 执行
3 .script 标签上添加 defer或者 async 属性
4 .创建并插入 iframe,让它异步执行 js
6 1 4 ajax请求时,如何解释json数据?(了解)……………………………………………..
使用 eval() 或者 JSON.parse() 鉴于安全性考虑,推荐使用 JSON.parse() 更靠谱,对数据的安全性更好.
6 1 5 Ajax提交请求默认是异步还是同步,怎么改成同步?(了解)…………………..
控制 ajax 请求参数 async 属性的值可以切换成同步请求或异步请求。 同步请求:(false)同步请求即是当前发出请求后,浏览器什么都不能做,必 须得等到请求完成返回数据之后,才会执行后续的代码,相当于是排队,前一个 人办理完自己的事务,下一个人才能接着办。也就是说,JS 代码加载到当前 AJAX 的时候会把页面里所有的代码停止加载,页面处于一个假死状态,当这个 AJAX 执行完毕后才会继续运行其他代码页面解除假死状态。 异步请求:(true) 异步请求就当发出请求的同时,浏览器可以继续做任何 事,Ajax 发送请求并不会影响页面的加载与用户的操作,相当于是在两条线上, 各走各的,互不影响。 例子:
$.ajax({
url:"url",
type:"post",
async:false,
success:function(){代码}});
6 1 6 如何解决ajax跨域问题?(了解)…………………………………………………………….
跨域问题来源于 JavaScript 的"同源策略”,即只有 协议+主机名+端口号 (如存在)相同,则允许相互访问。也就是说 JavaScript 只能访问和操作自己域 下的资源,不能访问和操作其他域下的资源。跨域问题是针对 JS 和 ajax 的, html 本身没有跨域问题。 跨域问题解决方案 1 .响应头添加 Header 允许访问 跨域资源共享(CORS)Cross-OriginResourceSharing 这个跨域访问的解决方案的安全基础是基于"JavaScript 无法控制该 HTTP 头"它需要通过目标域返回的 HTTP 头来授权是否允许跨域访问 具体如下: response.addHeader(‘Access-Control-Allow-Origin:*’);//允许所有来 源访问 response.addHeader(‘Access-Control-Allow-Method:POST,GET’);// 允许访问的方式 2 、jsonp(只支持 get 请求不支持 post 请求) 用法: ①dataType改为 jsonp ②jsonp:“jsonpCallback”(发送到后端实际例子: http://a.a.com/a/FromServlet?userName= 644064 &jsonpCallback=j Queryxxx)
③后端获取 get 请求中的 jsonpCallback ④构造回调结构 3 、httpClient 内部转发 实现原理例子:若想在 B 站点中通过 Ajax 访问 A 站点获取结果,固然 有 ajax 跨域问题,但在 B 站点中访问 B 站点获取结果,不存在跨域问题, 这种方式实际上是在 B 站点中 ajax 请求访问 B站点的 HttpClient,再通过 HttpClient 转发请求获取 A 站点的数据结果。但这种方式产生了两次请求, 效率低,但内部请求,抓包工具无法分析,安全 4 、使用接口网关——nginx、springcloudzuul(互联网公司常规解决方案)
6 1 7 Ajax 的优势(了解)……………………………………………………………………………………
通过异步模式,提升了用户体验。
优化了浏览器和服务器之间的传输,减少不必要的数据往返,减少了带宽占
用。
Ajax 引擎在客户端运行,承担了一部分本来由服务器承担的工作,从而减 少了大用户量下的服务器负载。
6 1 8 请介绍下Jsonp原理(了解)……………………………………………………………………..
jsonp的最基本的原理是:动态添加一个标签,使用 script 标签 的 src 属性没有跨域的限制的特点实现跨域。首先在客户端注册一个callback, 然后把 callback的名字传给服务器。此时,服务器先生成 json 数据。 然后 以 javascript 语法的方式,生成一个 function,function 名字就是传递上来 的参数 jsonp。最后将 json 数据直接以入参的方式,放置到 function 中,这 样就生成了一段 js 语法的文档,返回给客户端。客户端浏览器,解析 script 标 签,并执行返回的 javascript 文档,此时数据作为参数,传入到了客户端预先 定义好的 callback 函数里。
三.数据库…………………………………………………………………………………………………………………………….
3 1 SQL 之连接查询(必会)…………………………………………………………………………………………
1. 左连接 (左外连接)以左表为基准进行查询,左表数据会全部显示出
来, 右表 如果和左表匹配 的数据则显示相应字段的数据,如果不匹配,则
显示为NULL;
2. 右连接 (右外连接)以右表为基准进行查询,右表数据会全部显示出
来, 右表 如果和左表匹配的数据则显示相应字段的数据,如果不匹配,则
显示为NULL;
3. 全连接 就是先以左表进行左外连接,然后以右表进行右外连接。
内连接 :
显示表之间有连接匹配的所有行。
3 2 SQL 之聚合函数(必会)…………………………………………………………………………………………
聚合函数是对一组值进行计算并返回单一的值的函数,它经常与 select 语句中的 groupby 子句一同使用。 1 ) avg() :返回的是指定组中的平均值,空值被忽略。 2 ) count() :返回的是指定组中的项目个数。 3 ) max() :返回指定数据中的最大值。 4 ) min() :返回指定数据中的最小值。 5 ) sum() :返回指定数据的和,只能用于数字列,空值忽略。 6 ) groupby() :对数据进行分组,对执行完 groupby 之后的组进行聚 合函数的运算,计算每一组的值。最后用 having去掉不符合条件的组,
having 子句中的每一个元素必须出现在 select 列表中(只针对于
mysql)。
3 3 SQL之SQL 注入(必会)………………………………………………………………………………………
举例:
select admin from user where username='admin' or 'a'='a' and
passwd=''or'a'='a'
防止 SQL 注入,使用预编译语句是预防 SQL 注入的最佳方式,如
selectadminfromuserwhereusername=?Andpassword=?
使用预编译的 SQL 语句语义不会发生改变,在 SQL 语句中,变量用问号?
表示。像上面例子中,username 变量传递的'admin'or'a'='a' 参数,也只
会当 作 username 字符串来解释查询,从根本上杜绝了 SQL 注入攻击的
发生。
注意:使用 mybaits时 mapper 中#方式能够很大程度防止 SQL 注入,$
方式 无法防止 SQL 注入.
3 4 SQLSelect语句完整的执行顺序:(必会)………………………………………………………………
查询中用到的关键词主要包含六个,并且他们的顺序依次为
select–from–where–groupby–having–orderby 其中 select 和 from 是必须的,其他关键词是可选的, 这六个关键 词的执行顺序如下: from :需要从哪个数据表检索数据 where : 过滤表中数据的条件 groupby : 如何将上面过滤出的数据分组算结果 orderby : 按照什么样的顺序来查看返回的数据
3 5 存储引擎(高薪常问)……………………………………………………………………………………………
对于MySQL 5. 5 及更高版本,默认的存储引擎是InnoDB。在 5. 5 版本之 前,MySQL的默认存储引擎是MyISAM。
1 、InnoDB存储引擎……………………………………………………………………………………………..
特点:行锁设计、支持外键、支持非锁定读
使用next-key-locking的策略避免幻读现象
提供插入缓冲、二次写、自适应哈希索引、预读
采用聚集的方式存储表中数据
2 、MyISAM存储引擎……………………………………………………………………………………………
不支持事务、表锁设计,支持全文搜索
缓冲池只缓存索引文件,不缓存数据文件
MyISAM存储引擎表由MYD(存放数据文件)和MYI(存放索引文件) 组成.
3 、NDB存储引擎…………………………………………………………………………………………………..
数据全部放在内存中,因此主键查找速度极快
连接操作(JOIN)是在MySQL数据层完成而不是在存储引擎层,意味 着复杂的连接操作需要巨大的网络开销,因此查询速度很慢
4 、Memory存储引擎……………………………………………………………………………………………
表中的数据存放在内存,数据库重启或崩溃表中的数据都会消失
适合存储临时数据的临时表,以及数据仓库的纬度表
默认哈希索引
只支持表锁,并发性能差,不支持TEXT和BLOB列类型
存储变长字段时按照定长字段方式,浪费内存(eBay工程师给出了 patch解决方案)
5 、Archive存储引擎……………………………………………………………………………………………..
只支持INSERT和SELECT操作, 5. 1 版本之后支持索引
适合存储归档数据,如ri’zhi
6 、Federated存储引擎…………………………………………………………………………………………
不存放数据,只是指向一台远程MySQL数据库服务器上的表
7 、Maria存储引擎………………………………………………………………………………………………..
支持缓存数据和索引文件
行锁设计
提供MVCC功能
支持事务和非事务安全的选项
3 6 索引(高薪常问)…………………………………………………………………………………………………..
3 6 1 概念………………………………………………………………………………………………………………
1 .什么是索引?
索引是MySQL数据库中的重要对象之一,用于快速找出某个列中有某一特 定值的行。 2 .为什么要使用索引 索引是 MySQL 中一种十分重要的数据库对象。它是数据库性能调优技术 的基础,常用于实现数据的快速检索。
索引就是根据表中的一列或若干列按照一定顺序建立的列值与记录行之间 的对应关系表,实质上是一张描述索引列的列值与原表中记录行之间一一对应关 系的有序表。 3 .索引的分类 从数据结构角度 1 、B+树索引(O(log(n))):关于B+树索引,这也是大部分索引的数据结 构了.B+树是通过二叉查找树,再由平衡二叉树,B树演化而来. 2 、hash索引: 仅仅能满足"=",“IN"和”<=>“查询,不能使用范围查询 其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需 要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问, 所以 Hash 索引的查询效率要远高于 B-Tree索引 只有Memory存储引擎显示支持hash索引 3 、FULLTEXT索引(现在MyISAM和InnoDB引擎都支持了) 4 、R-Tree索引(用于对GIS数据类型创建SPATIAL索引)
从物理存储角度
1 、聚集索引(clusteredindex) 2 、非聚集索引(non-clusteredindex) 从逻辑角度 1 、主键索引:主键索引是一种特殊的唯一索引,不允许有空值 2 、普通索引或者单列索引 3 、多列索引(复合索引):复合索引指多个字段上创建的索引,只有 在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引 时遵循最左前缀集合 4 、唯一索引或者非唯一索引 5 、全文索引:全文索引是对空间数据类型的字段建立的索引,MYSQL 中的空间数据类型有 4 种,分别是GEOMETRY、POINT、LINESTRING、 POLYGON。
4 .索引的优点 创建唯一性索引,保证数据库表中每一行数据的唯一性 大大加快数据的检索速度,这也是创建索引的最主要的原因 加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意 义。 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组 和排序的时间。 通过使用索引,可以在查询的过程中使用优化隐藏器,提高系统的性能。 5 .索引的缺点 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占 一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护, 降低了数据的维护速度 6. 索引只是提高效率的一个因素,因此在建立索引的时候应该遵循以下原则:
在经常需要搜索的列上建立索引,可以加快搜索的速度。
在作为主键的列上创建索引,强制该列的唯一性,并组织表中数据的排
列结构。
在经常使用表连接的列上创建索引,这些列主要是一些外键,可以加快
表连接的速度。
在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,所
以其指定的范围是连续的。
在经常需要排序的列上创建索引,因为索引已经排序,所以查询时可以
利用索引的排序,加快排序查询。
在经常使用 WHERE子句的列上创建索引,加快条件的判断速度。
3 6 2 常见索引原则………………………………………………………………………………………………..
选择唯一性索引:唯一性索引的值是唯一的,可以更快速的通过该索引
来确定某条记录。
为经常需要排序.分组和联合操作的字段建立索引. 为常作为查询条件的
字段建立索引。
限制索引的数目:越多的索引,会使更新表变得很浪费时间。
尽量使用数据量少的索引:如果索引的值很长,那么查询的速度会受到
影响。尽量使用前缀来索引:如果索引字段的值很长,最好使用值的前缀来索引。
删除不再使用或者很少使用的索引
最左前缀匹配原则,非常重要的原则。
尽量选择区分度高的列作为索引:区分度的公式是表示字段不重复的比
例索引列不能参与计算,保持列“干净”:带函数的查询不参与索引。
尽量的扩展索引,不要新建索引。
3 7 索引原理(了解)……………………………………………………………………………………………………
我们使用索引,就是为了提高查询的效率,如同查书一样,先找到章,
再找到章中对于的小节,再找到具体的页码,再到我们需要的内容。
事实上索引的本质就是不断缩小获取数据的筛选范围,找出我们想要的
结果。同时把随机的事件变成顺序的事件,也就是说有了这种索引机制,我们就
可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有
范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库 应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数 据分成段,然后分段查询呢?最简单的如果 1000 条数据, 1 到 100 分成第一段, 101 到 200 分成第二段, 201 到 300 分成第三段……这样查第 250 条数据,只要找 第三段就可以了,一下子去除了 90 %的无效数据。但如果是 1 千万的记录呢,分 成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有 不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相 同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的, 另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知 道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复 杂的应用场景。
3 7 1 磁盘IO与预读……………………………………………………………………………………………..
磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道
时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需
要的时间,主流磁盘一般在 5 ms以下;旋转延迟就是我们经常听说的磁盘转速, 比如一个磁盘 7200 转,表示每分钟能转 7200 次,也就是说 1 秒钟能转 120 次,旋 转延迟就是 1 / 120 / 2 = 4. 17 ms;传输时间指的是从磁盘读出或将数据写入磁盘 的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁 盘的时间,即一次磁盘IO的时间约等于 5 + 4. 17 = 9 ms左右,听起来还挺不错的, 但要知道一台 500 - MIPS(MillionInstructionsPerSecond)的机器每秒可以 执行 5 亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以 执行约 450 万条指令,数据库动辄十万百万乃至千万级数据,每次 9 毫秒的时间, 显然是个灾难。下图是计算机硬件延迟的对比图,供大家参考:
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化, 当一次IO
时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内 ,
因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻
的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体 一页有多大数据跟操作系统有关,一般为 4 k或 8 k,也就是我们读取一页内的数 据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮 助。
3 7 2 B+树……………………………………………………………………………………………………………..
上面说了磁盘io是很费时间的。当我们想要查询一个数据的时候,应该控制 把磁盘IO控制在一个很小的数量级。而B+数应运而生(B+树是通过二叉查找树, 再由平衡二叉树,B树演化而来)。
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重 点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深 蓝色所示)和指针(黄色所示),如磁盘块 1 包含数据项 17 和 35 ,包含指针P 1 、 P 2 、P 3 ,P 1 表示小于 17 的磁盘块,P 2 表示在 17 和 35 之间的磁盘块,P 3 表示大 于 35 的磁盘块。真实的数据存在于叶子节点即 3 、 5 、 9 、 10 、 13 、 15 、 28 、 29 、 36 、 60 、 75 、 79 、 90 、 99 。非叶子节点只不存储真实的数据,只存储指引搜索 方向的数据项,如 17 、 35 并不真实存在于数据表中。
3 7 3 B+树的查找过程……………………………………………………………………………………………
如图所示,如果要查找数据项 29 ,那么首先会把磁盘块 1 由磁盘加载到内存,
此时发生一次IO,在内存中用二分查找确定 29 在 17 和 35 之间,锁定磁盘块 1 的
P 2 指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块 1
的P 2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存,发生第二次IO, 29 在 26 和
30 之间,锁定磁盘块 3 的P 2 指针,通过指针加载磁盘块 8 到内存,发生第三次IO,
同时内存中做二分查找找到 29 ,结束查询,总计三次IO。真实的情况是, 3 层的
b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高 将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万 次的IO,显然成本非常非常高。
3 7 4 B+树性质………………………………………………………………………………………………………
1 .索引字段要尽量的小 :通过上面的分析,我们知道IO次数取决于b+ 数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m, 则有h=㏒(m+ 1 )N,当数据量N一定的情况下,m越大,h越小;而m= 磁 盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定 的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什 么每个数据项,即索引字段要尽量的小,比如int占 4 字节,要比bigint 8 字节 少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点, 一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于 1 时将会退化成线性表。 2. 索引的最左匹配特性 :当b+树的数据项是复合的数据结构,比如 (name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当
(张三, 20 ,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的 所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但 当( 20 ,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节 点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name 来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树 可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等 于张三的数据都找到,然后再匹配性别是F的数据了,这个是非常重要的性质, 即索引的最左匹配特性。
3 7 5 聚焦索引和辅助索引……………………………………………………………………………………..
在数据库中,B+树的高度一般都在 2 ~ 4 层,这也就是说查找某一个键值
的行记录时最多只需要 2 到 4 次IO,这倒不错。
数据库中的B+树索引可以分为聚集索引(clusteredindex)和辅助索 引(secondaryindex), 聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部 都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。 聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息 1 ) 聚集索引
InnoDB存储引擎表示索引组织表,即表中数据按照主键顺序存放。而聚 集索引(clusteredindex)就是按照每张表的主键构造一棵B+树,同时叶子结 点存放的即为整张表的行记录数据,也将聚集索引的叶子结点称为数据页。聚集 索引的这个特性决定了索引组织表中数据也是索引的一部分。同B+树数据结构 一样,每个数据页都通过一个双向链表来进行链接。 如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空 列(NOTNULL)作为主键,InnoDB使用它作为聚簇索引。 如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字 节,而且是隐藏的,使其作为聚簇索引。 由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一 个聚集索引。在多少情况下,查询优化器倾向于采用聚集索引。因为聚集索引能
够在B+树索引的叶子节点上直接找到数据。此外由于定义了数据的逻辑顺序,
聚集索引能够特别快地访问针对范围值得查询。
聚集索引的好处
它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户
所要查询的数据。如用户需要查找一张表,查询最后的 10 位用户信息,由于B+
树索引是双向链表,所以用户可以快速找到最后一个数据页,并取出 10 条记录
范围查询(rangequery),即如果要查找主键某一范围内的数据,通 过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可 2 ) 辅助索引
表中除了聚集索引外其他索引都是辅助索引(SecondaryIndex,也称 为非聚集索引),与聚集索引的区别是:辅助索引的叶子节点不包含行记录的全 部数据。 叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含一个书 签(bookmark)。该书签用来告诉InnoDB存储引擎去哪里可以找到与索引相 对应的行数据。 由于InnoDB存储引擎是索引组织表,因此InnoDB存储引擎的辅助索引 的书签就是相应行数据的聚集索引键。 辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以 有多个辅助索引,但只能有一个聚集索引。当通过辅助索引来寻找数据时, InnoDB存储引擎会遍历辅助索引并通过叶子级别的指针获得相应的主键索引的 主键,然后再通过主键索引来找到一个完整的行记录。 举例来说,如果在一棵高度为 3 的辅助索引树种查找数据,那需要对这 个辅助索引树遍历 3 次找到指定主键,如果聚集索引树的高度同样为 3 ,那么还 需要对聚集索引树进行 3 次查找,最终找到一个完整的行数据所在的页,因此一 共需要 6 次逻辑IO访问才能得到最终的一个数据页。
3 8 数据库三范式(必会)………………………………………………………………………………………………..
范式是具有最小冗余的表结构。三范式具体如下:
数据库三范式主要是为了设计出高效率、优雅的数据库,否则可能会设计出
错误的数据库.
第一范式( 1 NF),原子性,列或者字段不能再分
1 NF是数据库所具备的最起码的条件,如果数据库设计不能满足第一范式,
就不称为关系型数据库。
如:
省会 城市 详细地址
北京 北京 海定区
广东 深圳 福田区
湖北 武汉 武昌区
第二范式( 2 NF),唯一性,一张表只说一件事
2 NF要满足 1 NF,并且不可以把多种数据保存在同一张表中,即一张表只能
保存“一种”数据,否则可能导致插入数据异常。
如:
学生:Student(学号, 姓名, 年龄); 课程:Course(课程名称, 学分); 选课关系:StudentCourse(学号, 课程名称, 成绩)。 第三范式( 3 NF),直接性,不存在传递依赖 3 NF要在满足 2 NF的条件上,在每一列都和主键直接相关,而不能间接相关。 如: 学生:(学号, 姓名, 年龄, 所在学院); 学院:(学院, 电话)。 反第三范式: 就是不按第三范式来, 要设计出传递依赖的那一列, 就看实际 开发中客户对这一列是否经常查询, 如果经常查询就要设计出来, 这属于拿 空间换时间, 能够提高客户查询效率.
3 9 数据库事务(必会)……………………………………………………………………………………………………
3. 9. 1 事务(TRANSACTION)
是作为单个逻辑工作单元执行的一系列操作,这些操作作为一个整 体一起向系统提交,要么都执行.要么都不执行。事务是一个不可分割的工作逻 辑单元 事务必须具备以下四个属性,简称 ACID 属性: A 原子性(Atomicity) :事务是一个完整的操作。事务的各步操作 是不可分的(原子的);要 么都执行,要么都不执行。 B 一致性(Consistency) :当事务完成时,数据必须处于一致状态。 C 隔离性(Isolation) :对数据进行修改的所有并发事务是彼此隔离 的,这表明事务必须是独 立的,它不应以任何方式依赖于或影响其他事务。 D 永久性(Durability) :事务完成后,它对数据库的修改被永久保持,事务 日志能够保持事务 的永久性。
-
- 2 事务控制语句
BEGIN 或 S TARTTRANSACTION 显式地开启一个事务; COMMIT 也可以使用 COMMITWORK ,不过二者是等价的。 COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的; ROLLBACK 也可以使用 ROLLBACKWORK ,不过二者是等价的。回 滚会结束用户的事务,并撤销正在进行的所有未提交的修改; SAVEPOINTidentifier , SAVEPOINT 允许在事务中创建一个保存 点,一个事务中可以有多个 SAVEPOINT ; RELEASESAVEPOINTidentifier 删除一个事务的保存点,当没有指 定的保存点时,执行该语句会抛出一个异常; ROLLBACKTOidentifier 把事务回滚到标记点; SETTRANSACTION 用来设置事务的隔离级别。
InnoDB 存储引 擎 提 供 事 务 的 隔 离 级 别 有 READ UNCOMMITTED.READCOMMITTED.REPEATABLEREAD 和 SERIALIZABLE 。
3 9 3 MySQL事务处理主要有两种方法:……………………………………………………………..
a) 用 BEGIN,ROLLBACK,COMMIT 来实现
i. BEGIN 开始一个事务
ii. ROLLBACK 事务回滚
iii. COMMIT 事务确认
b) 直接用 SET 来改变 MySQL 的自动提交模式:
i. SETAUTOCOMMIT= 0 禁止自动提交
ii. SETAUTOCOMMIT= 1 开启自动提交
3 9 4 事务的四种隔离级别……………………………………………………………………………………..
1 )Readuncommitted 读未提交,顾名思义,就是一个事务可以读取另一个未提交事务的数据。 2 )Readcommitted 读已提交,顾名思义,就是一个事务要等另一个事务提交后才能读取数 3 )Repeatableread 可重复读,就是在开始读取数据(事务开启)时,不再允许修改操作 4 )Serializable 序列化 Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以 避免脏读.不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库 性能,一般不使用。 在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatableread(可 重复读) ;而在Oracle数据库中,只支持Serializable(串行化)级别和Read committed(读已提交)这两种级别,其中默认的为 Readcommitted 级别。
3 10 存储过程(高薪常问)………………………………………………………………………………………….
一组为了完成特定功能的 SQL 语句集,存储在数据库中,经过第一次编
译后再次调用不需要再次 编译,用户通过指定存储过程的名字并给出参数
(如果该存储过程带有参数)来执行它。存储过 程是数据库中的一个重要对
象。
存储过程优化思路:
1. 尽量利用一些 SQL 语句来替代一些小循环,例如聚合函数,求平均
函数等。
2. 中间结果存放于临时表,加索引。
3. 少使用游标。SQL 是个集合语言,对于集合运算具有较高性能。而
cursors是 过程运算。比 如对一个 100 万行的数据进行查询。游标需要读表 100 万次, 而不 使用游标则只需要少量几次读取。 4. 事务越短越好。SQLserver支持并发操作。如果事务过多过长,或者 隔离级 别过高,都会造 成并发操作的阻塞,死锁。导致查询极慢,cpu 占用率极地。 5. 使用 try-catch 处理错误异常。 6. 查找语句尽量不要放在循环内。
3 11 数据库并发策略(高薪常问)……………………………………………………………………………….
并发控制一般采用三种方法,分别是乐观锁和悲观锁以及时间戳。
3 11 1 乐观锁………………………………………………………………………………………………………….
乐观锁认为一个用户读数据的时候,别人不会去写自己所读的数据;悲观锁
就刚好相反,觉得自 己读数据库的时候,别人可能刚好在写自己刚读的数据,
其实就是持一种比较保守的态度;时间 戳就是不加锁,通过时间戳来控制并
发出现的问题。
3 11 2 悲观锁………………………………………………………………………………………………………..
悲观锁就是在读取数据的时候,为了不让别人修改自己读取的数据,就会先
对自己读取的数据加锁,只有自己把数据读完了,才允许别人修改那部分数据,或
者反过来说,就是自己修改某条数 据的时候,不允许别人读取该数据,只有
等自己的整个事务提交了,才释放自己加上的锁,才允 许其他用户访问那部
分数据。
3. 11. 3 两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一
种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时
候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,
一般会经常产生冲突,这就会导致上层应用会不断的进行 retry,这样反倒是
降低了性能,所以一般多写的场景下用悲观锁就比较合适。
-
- 4 乐观锁常见的两种实现式版本号机制
一般是在数据表中加上一个数据版本号 version字段,表示数据被修改的次
数,当数据被修改时,version 值会加一。当线程A 要更新数据值时,在读取数
据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前
数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。CAS算
法即compareandswap(比较与交换),是一种有名的无锁算法。
无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程
被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking
Synchronization)。CAS 算法涉及到三个操作数
需要读写的内存值
V进行比较的值 A
拟写入的新值 B
当且仅当 V 的值等于 A 时,CAS 通过原子方式用新值 B来更新 V
的值, 否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是
一个自旋操作,即不断的重试。
3 11 5 乐观锁的缺点……………………………………………………………………………………………..
ABA 问 题
如果一个变量 V初次读取的时候是A 值,并且在准备赋值的时候检查到
它仍然是A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是
不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那CAS操
作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 “ABA"问
题。
JDK 1. 5 以后的 AtomicStampedReference 类就提供了此种能力,
其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并
且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的
值设置为给定的更新值。
循环时间长开销大
自旋 CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,
会给 CPU 带来非常大的执行开销。 如果JVM 能支持处理器提供的 pause
指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执
行指令(de-pipeline),使CPU 不会消耗过多的执行资源,延迟的时间取决于
具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候
因内存顺序冲突(memoryorderviolation)而引起 CPU流水线被清空(CPU
pipelineflush),从而提高 CPU 的执行效率。
只能保证一个共享变量的原子操作
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无
效。但是从 JDK 1. 5 开始,提供了AtomicReference 类来保证引用对象之
间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可
以使用锁或者利用 AtomicReference 类把多个共享变量合并成一个共享变
量来操作
CAS 与 synchronized 的使用情景
简单的来说 CAS 适用于写比较少的情况下(多读场景,冲突一般较少),
synchronized适用于写比较多的情况下(多写场景,冲突一般较多)
对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁
进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资
源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因
此可以获得更高的性能。
对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,
从而浪费更多的 CPU 资源,效率低于 synchronized。
补充: Java并发编程这个领域中 synchronized 关键字一直都是元老级的
角色,很久之前很多人都会称它为“重量级锁”。但是,在JavaSE 1. 6 之后进
行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 偏向锁 和
轻量级锁 以及其它各种优化之后变得在某些情况下并不是那么重了。
synchronized的底层实现主要依靠Lock-Free的队列,基本思路是自旋后阻
塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。在线程冲
突较少的情况下,可以获得和CAS 类似的性能;而线程冲突严重的情况下,
性能远高于CAS 。
3 11 6 时间戳………………………………………………………………………………………………………..
时间戳就是在数据库表中单独加一列时间戳,比如“TimeStamp”,每次读
出来的时候,把该字段也读出来,当写回去的时候,把该字段加 1 ,提交之前,跟
数据库的该字段比较一次,如果比数 据库的值大的话,就允许保存,否则不
允许保存,这种处理方法虽然不使用数据库系统提供的锁 机制,但是这种方
法可以大大提高数据库处理的并发量,
以上悲观锁所说的加“锁”,其实分为几种锁,分别是:排它锁(写锁)和共
享锁(读锁)。
3 12 触发器(高薪常问)……………………………………………………………………………………………..
触发器是一段能自动执行的程序,是一种特殊的存储过程,触发器和普通的存储
过程的区别是: 触发器是当对某一个表进行操作时触发。诸如:
update.insert.delete 这些操作的时候,系统 会自动调用执行该表上对应的触
发器。SQLServer 2005 中触发器可以分为两类:DML 触发器和 DDL 触 发器,其中 DDL 触发器它们会影响多种数据定义语言语句而激发,这些语 句有create.alter.drop 语句。
3 13 数据库锁(高薪常问)………………………………………………………………………………………….
数据库锁一般可以分为两类,一个是悲观锁,一个是乐观锁。
悲观锁,从数据开始更改时就将数据锁住,知道更改完成才释放
乐观锁,直到修改完成准备提交所做的的修改到数据库的时候才会
将数据锁住。完成更改后释放。
悲观锁一般就是我们通常说的数据库锁机制,以下讨论都是基于悲观锁。
悲观锁主要表锁、行锁、页锁。在MyISAM中只用到表锁,不会有死锁的 问题,锁的开销也很小,但是相应的并发能力很差。innodb实现了行级锁和表 锁,锁的粒度变小了,并发能力变强,但是相应的锁的开销变大,很有可能出现 死锁。同时inodb需要协调这两种锁,算法也变得复杂。InnoDB行锁是通过 给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用 行级锁,否则,InnoDB将使用表锁。 表锁和行锁都分为共享锁和排他锁(独占锁),而更新锁是为了解决行锁升 级(共享锁升级为独占锁)的死锁问题。 innodb中表锁和行锁一起用,所以为了提高效率才会有意向锁(意向共享 锁和意向排他锁)。
3 14 基于 Redis分布式锁(高薪常问)………………………………………………………………..
- 获取锁的时候,使用 setnx(ETNXkeyval:当且仅当 key 不存 在时, set 一个 key 为 val 的字符串,返回 1 ;若 key 存在,则什么都不 做,返回 0 ) 加锁,锁的 value 值为一个随机生成的 UUID,在释放锁的时 候进行判断。并使用 expire 命令为锁添 加一个超时时间,超过该时间则自动 释放锁。
- 获取锁的时候调用 setnx,如果返回 0 ,则该锁正在被别人使用,返回 1 则成功获取 锁。 还设置一个获取的超时时间,若超过这个时间则放弃获取 锁。
- 释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete 进行锁释放。
3 15 分区分表(高薪常问)………………………………………………………………………………………….
1 .什么是mysql分表和分区………………………………………………………………………………….
什么是分表,从表面意思上看呢,就是把一张表分成N多个小表
什么是分区,分区呢就是把一张表的数据分成N多个区块,这些区块可以在
同一个磁盘上,也可以在不同的磁盘上
2 .mysql分表和分区有什么区别呢………………………………………………………………………….
1 >实现方式上
a)mysql的分表是真正的分表,一张表分成很多表后,每一个小表都 是完正的一张表,都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm 表结构文件。 b)分区不一样,一张大表进行分区后,他还是一张表,不会变成二张 表,但是他存放数据的区块变多了。 2 >数据处理上 a)分表后,数据都是存放在分表里,总表只是一个外壳,存取数据发生 在一个一个的分表里面。看下面的例子:
select*fromalluserwhereid=’ 12 ‘表面上看,是对表alluser进行操 作的,其实不是的。是对alluser里面的分表进行了操作。 b)分区呢,不存在分表的概念,分区只不过把存放数据的文件分成了 许多小块,分区后的表呢,还是一张表。数据处理还是由自己来完成。 3 >提高性能上 a) 分表后,单表的并发能力提高了,磁盘I/O性能也提高了。并发能 力为什么提高了 呢,因为查寻一次所花的时间变短了,如果出现高并 发的话,总表可以根据不同的查询,将并发压力分到不同的小表里面。 磁盘I/O性能怎么搞高了呢,本来一个 非常大的.MYD文件现在也分 摊到各个小表的.MYD中去了。
3 .mysql分表的三种方法………………………………………………………………………………………
1 >做mysql集群, 有人会问mysql集群,和分表有什么关系吗?虽然它不 是实际意义上的分表,但是它起到了分表的作用。 2 >预先估计会出现大数据量并且访问频繁的表,将其分为若干个表 3 >利用merge存储引擎来实现分表 4. 分区类型 range分区:基于一个给定的连续区间范围(区间要求连续并且不能重叠), 把数据分配到不同的分区 list分区:类似于range分区,区别在于list分区是居于枚举出的值列表分 区,range是基于给定的连续区间范围分区 hash分区:基于给定的分区个数,把数据分配到不同的分区 key分区:类似于hash分区
3. 16 应该使用哪一种方式来实施数据库分库分表,这要看 数据库中数据量的瓶颈所在,并综合项目的业务类型进行考 虑。(了解)
如果数据库是因为表太多而造成海量数据,并且项目的各项业务逻辑划分清晰. 低耦合,那么规则简单明了.容易实施的垂直切分必是首选。 而如果数据库中的表并不多,但单表的数据量很大.或数据热度很高,这种情 况 之下就应该选择水平切分,水平切分比垂直切分要复杂一些,它将原本逻辑 上属于一体的数据进行了物理分割,除了在分割时要对分割的粒度做好评估,考虑
数 据平均和负载平均,后期也将对项目人员及应用程序产生额外的数据管理负
担。 在现实项目中,往往是这两种情况兼而有之,这就需要做出权衡,甚至既
需要垂 直切分,又需要水平切分。我们的游戏项目便综合使用了垂直与水平切
分,我们 首先对数据库进行垂直切分,然后,再针对一部分表,通常是用户数
据表,进行 水平切分。
单库多表 :
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度 的时候对 user 表的查询会渐渐的变慢,从而影响整个 DB 的性能。如果使 用 MySQL, 还有一个更严重的问题是,当需要添加一列的时候,MySQL 会 锁表, 期间所有的读写操作只能等待。 可以将 user进行水平的切分,产生两个表结构完全一样的 user_ 0000 ,user_ 0001 等表,user_ 0000 +user_ 0001 + …的数据刚好是一份 完整的数据。 多库多表 : 随着数据量增加也许单台 DB 的存储空间不够,随着查询量的增加单台数 据 库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。 分库分表规则举例: 通过分库分表规则查找到对应的表和库的过程。如分 库分表的规则是 user_id 除以 4 的方式,当用户新注册了一个账号,账号 id 的 123 ,我们可以通过 id 除以 4 的方式确定此账号应该保存到 User_ 0003 表中。当用户 123 登录的时 候,我们通过 123 除以 4 后 确定记录在User_ 0003 中。
3 17 MySQL 读写分离(高薪常问)…………………………………………………………………………..
在实际的应用中,绝大部分情况都是读远大于写。MySQL 提供了读写分离 的机制,所有的写操作都必须对应到 Master,读操作可以在 Master 和 Slave 机 器上进行,Slave 与 Master 的结构完全一样,一个 Master可以有多个 Slave,甚 至 Slave 下还可以挂 Slave,通过此方式可以有效的提高 DB集群的 每秒查询率. 所有的写操作都是先在 Master 上操作,然后同步更新到 Slave 上,所以 从 Master 同步到 Slave机器有一定的延迟,当系统很繁忙的时候, 延迟问题会 更加严重,Slave机器数量的增加也会使这个问题更加严重。此外, 可以看出 Master 是集群的瓶颈,当写操作过多,会严重影响到Master的 稳
定性,如果 Master 挂掉,整个集群都将不能正常工作。 所以,
- 当读压力很大的时候,可以考虑添加 Slave 机器的分式解决,但是当 Slave 机器达到一定的数量就得考虑分库了。
- 当写压力很大的时候,就必须 得进行分库操作。
3 18 MySQL 常用 15 种SQL查询语句优化方法(必会)……………………………………………..
- 应尽量避免在 where子句中使用!=或<>操作符,否则引擎将放弃使 用索引而进行全表扫描。
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在where 及 orderby 涉及的列上建立索引。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致 引擎放弃使用索引而进行全表扫描。如:
selectidfromtwherenumisnull 可以在 num 上设置默认值 0 ,确保表中 num 列没有 null 值,然后这 样查询:
selectidfromtwherenum= 0 4. 尽量避免在 where 子句中使用 or来连接条件,否则将导致引擎放 弃使用索引而进行全表扫描,如:
selectidfromtwherenum= 10 ornum= 20 可以这样查询: selectidfromtwherenum= 10 unionall selectidfromtwherenum= 20 5. 下面的查询也将导致全表扫描:(不能前置百分号)
selectidfromtwherenamelike ‘%c%’
下面走索引
selectidfromtwherenamelike ‘c%’ 若要提高效率,可以考虑全文检索。 6. in 和 notin 也要慎用,否则会导致全表扫描,如:
selectidfromtwherenumin( 1 , 2 , 3 )
对于连续的数值,能用 between 就不要用 in 了:
selectidfromtwherenumbetween 1 and 3
7. 如果在 where子句中使用参数,也会导致全表扫描。因为 SQL 只有
在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须
在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,
因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
selectidfromtwherenum=@num
可以改为强制查询使用索引:
selectidfromtwith(index(索引名))wherenum=@num
8. 应尽量避免在 where子句中对字段进行表达式操作,这将导致引擎放
弃使用索引而进行全表扫描。如:
selectidfromtwherenum/ 2 = 100
应改为:
selectidfromtwherenum= 100 * 2
9. 应尽量避免在 where子句中对字段进行函数操作,这将导致引擎放弃使
用索引而进行全表扫描。如:
selectidfromtwheresubstring(name, 1 , 3 )=’abc’–name 以 abc 开
头的 id
selectidfromtwheredatediff(day,createdate,’ 2005 - 11 - 30 ′)= 0 – ’
2005 - 11 - 30 ′生成的 id
应改为:
selectidfromtwherenamelike ‘abc%’ selectidfromtwherecreatedate>=’ 2005 - 11 - 30 ′ andcreatedate<’ 2005 - 12 - 1 ′ 10. 不要在 where子句中的“=”左边进行函数.算术运算或其他表达式 运算,否则系统将可能无法正确使用索引。 11. 在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用 到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会 被使 用,并且应尽可能的让字段顺序与索引顺序相一致。 12. 不要写一些没有意义的查询,如需要生成一个空表结构: selectcol 1 ,col 2 into#tfromtwhere 1 = 0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: createtable#t(…) 13. 很多时候用 exists 代替 in 是一个好的选择:
selectnumfromawherenumin(selectnumfromb) 用下面的语句替换:
selectnumfromawhereexists(select 1 frombwherenum=a.num) 14. 并不是所有索引对查询都有效,SQL 是根据表中数据来进行查询优化的, 当索引列有大量数据重复时,SQL 查询可能不会去利用索引,如一表中有字段 sex,male.female 几乎各一半,那么即使在sex上建了索引也对查询效率起不 了作用。 15. 索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同 时也降低了 insert 及 update 的效率,因为 insert 或 update 时有 可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引 数较好不要超过 6 个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
3 19 数据库优化方案整理(高薪常问)………………………………………………………………………..
1 )Sql优化主要优化的还是查询, 优化查询的话,索引优化是最有效的方案……………
首先要根据需求写出结构良好的 SQL,然后根据 SQL 在表中建立有效的索
引。但是如果索引太多,不但会影响写入的效率,对查询也有一定的影响。
定位慢 SQL然后并优化
这是最常用.每一个技术人员都应该掌握基本的 SQL 调优手段(包括方法.
工具.辅助系统等)。这里以 MySQL 为例,最常见的方式是,由自带的慢查询日志 或者开源的慢查询系统定位到具体的出问题的 SQL,然后使用explain.profile等 工具来逐步调优,最后经过测试达到效果后上线。 explain+sql语句查询sql执行过程, 通过执行计划,我们能得到哪些信 息: A:哪些步骤花费的成本比较高 B:哪些步骤产生的数据量多,数据量的多少用线条的粗细表示,很直观 C:每一步执行了什么动作 优化索引 ( 1 )索引列务必重复度低 ,where条件字段上需要建立索引 ( 2 )使用索引就不能用OR查询,否则索引不起作用 ( 3 )使用索引,like模糊查询不能以%开头 ( 4 )查询条件务必以索引列开头,否则索引失效 ( 5 )复合索引遵守最左原则. 避免索引失效 A:尽量不要在 where 子句中对字段进行 null 值判断,否则将导致引擎 放弃使用索引而进行全表扫描 B:应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放 弃使用索引而进行全表扫描。 C:应尽量避免在 where 子句中使用 or来连接条件,如果一个字段有索 引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描 D:不做列运算whereage+ 1 = 10 ,任何对列的操作都将导致表扫描,它 包括数据库教程函数.计算表达式等, 都会是索引失效.
E:查询 like,如果是 ‘%aaa’ 也会造成索引失效.
2 )Sql语句调优………………………………………………………………………………………………………
根据业务场景建立覆盖索引只查询业务需要的字段,如果这些字段被索
引覆盖,将极大的提高查询效率.
多表连接的字段上需要建立索引,这样可以极大提高表连接的效率.
where条件字段上需要建立索引, 但Where条件上不要使用运算函数,
以免索引失效.
排序字段上, 分组字段上需要建立索引.
优化insert语句: 批量列插入数据要比单个列插入数据效率高.
优化orderby语句: 在使用orderby语句时, 不要使用select*,
select 后面要查有索引的列, 如果一条sql语句中对多个列进行排
序, 在业务允许情况下, 尽量同时用升序或同时用降序.
优化groupby语句: 在我们对某一个字段进行分组的时候,Mysql
默认就进行了排序, 但是排序并不是我们业务所需的, 额外的排序
会降低效率. 所以在用的时候可以禁止排序, 使用orderbynull禁
用.
selectage,count(*)fromempgroupbyageorderbynull
尽量避免子查询, 可以将子查询优化为join多表连接查询.
3 )合理的数据库设计……………………………………………………………………………………………..
根据数据库三范式来进行表结构的设计。设计表结构时,就需要考虑如何设
计才能更有效的查询, 遵循 数据库三范式:
i. 第一范式 :数据表中每个字段都必须是不可拆分的最小单元,也就是确保 每一列的原子性; ii. 第二范式 :满足一范式后,表中每一列必须有唯一性,都必须依赖 于主键; iii. 第三范式 :满足二范式后,表中的每一列只与主键直接相关而不是 间接相关(外键也是直接相关),字段没有冗余。 注意:没有最好的设计,只有最合适的设计,所以不要过分注重理论。三范式可以 作为一个基本依据,不要生搬硬套。 有时候可以根据场景合理地反规范化:
A:分割表。
B:保留冗余字段。当两个或多个表在查询中经常需要连接时,可以在其
中一个表上增加若干冗余的字段,以 避免表之间的连接过于频繁,一般在冗
余列的数据不经常变动的情况下使用。
C:增加派生列。派生列是由表中的其它多个列的计算所得,增加派生列
可以减少统计运算,在数据汇总时可以大大缩短运算时间, 前提是这个列经常
被用到, 这也就是反第三范式。
4 )分表…………………………………………………………………………………………………………………..
水平分割(按行).垂直分割(按列)
分表场景
A: 根据经验,MySQL 表数据一般达到百万级别,查询效率就会很低。 B:一张表的某些字段值比较大并且很少使用。可以将这些字段隔离成单独 一张表,通过外键关联,例如考试成绩,我们通常关注分数,不关注考试详情。 水平分表策略 C:按时间分表:当数据有很强的实效性,例如微博的数据,可以按月分割。 按区间分表:例如用户表 1 到一百万用一张表,一百万到两百万用一张表。hash 分表:通过一个原始目标 id 或者是名称按照一定的 hash 算法计算出数据存 储的表名。
3 20 oracle和mysql的分页语句?(必会)………………………………………………………………..
3 20 1 oracle………………………………………………………………………………………………………….
select*from(select*from(selects.*,rownumrnfromstudents)
wherern<= 5 )wherern> 0
3 20 2 mysql………………………………………………………………………………………………………….
select*fromtable_namewhere 1 = 1 limit (start,end)
四.Mybatis框架…………………………………………………………………………………………………………………..
4 1 什么是Mybatis?(必会)…………………………………………………………………………………….
( 1 )Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC, 开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动.创建连接. 创建statement等繁杂的过程。程序员直接编写原生态sql,可以严格控制sql 执行性能,灵活度高。 ( 2 )MyBatis可以使用XML 或注解来配置和映射原生信息,将POJO映 射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取 结果集。 ( 3 )通过xml 文件或注解的方式将要执行的各种 statement 配置起来, 并通过java对象和 statement中sql的动态参数进行映射生成最终执行的sql 语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。(从执 行sql到返回result的过程)。
4 2 Mybaits的优点(了解)…………………………………………………………………………………………
( 1 )基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设
计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管 理;提供XML标签,支持编写动态SQL语句,并可重用。 ( 2 )与JDBC相比,减少了 50 %以上的代码量,消除了JDBC大量冗余的 代码,不需要手动开关连接; ( 3 )很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库, 所以只要JDBC支持的数据库MyBatis都支持)。 ( 4 )能够与Spring很好的集成; ( 5 )提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象 关系映射标签,支持对象关系组件维护。
4 3 MyBatis与Hibernate有哪些不同?(必会)………………………………………………………..
( 1 )Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis 需要程序员自己编写Sql语句。 ( 2 )Mybatis直接编写原生态SQL,可以严格控制SQL执行性能,灵活 度高,非常适合对关系数据模型要求不高的软件开发,因为这类软件需求变化频
繁,一但需求变化要求迅速输出成果。但是灵活的前提是Mybatis无法做到数 据库无关性,如果需要实现支持多种数据库的软件,则需要自定义多套SQL映 射文件,工作量大。 ( 3 )Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要 求高的软件,如果用Hibernate开发可以节省很多代码,提高效率。
4 4 #{}和${}的区别是什么?(必会)…………………………………………………………………………….
#{}是预编译处理,${}是字符串替换。
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement 的set方法来赋值; Mybatis在处理${}时,就是把${}替换成变量的值。 使用#{}可以有效的防止SQL注入,提高系统安全性。
4 5 Mybatis是如何进行分页的?分页插件的原理是什么?(必会)…………………………….
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执 行的内存分页,而非物理分页。可以在SQL内直接书写带有物理分页的参数来 完成物理分页功能,也可以使用分页插件来完成物理分页。 分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件, 在插件的拦截方法内拦截待执行的SQL,然后重写SQL,根据dialect方言,添 加对应的物理分页语句和物理分页参数。
4 6 Mybatis动态SQL有什么用?执行原理?有哪些动态sql标签?(必会)………………..
Mybatis动态SQL可以在Xml映射文件内,以标签的形式编写动态sql, 执行原理是根据表达式的值 完成逻辑判断并动态拼接sql的功能。 Mybatis提供了 9 种动态sql标签:trim|where|set|foreach|if| choose|when|otherwise|bind。 4. 7 Xml映射文件中,除了select|insert|updae|delete 标签之外,还有哪些标签?(了解) ....,加上 动态sql的 9 个标签,其中为sql片段标签,通过标签引入sql 片段,为不支持自增的主键生成策略标签。
4 8 MyBatis实现一对一有几种方式?具体怎么操作的?(必会)………………………………….
有联合查询和嵌套查询,联合查询是几个表联合查询,只查询一次,通过在
resultMap里面配置association节点配置一对一的类就可以完成; 嵌套查询是先查一个表,根据这个表里面的结果的 外键id,去再另外一个 表里面查询数据,也是通过association配置,但另外一个表的查询通过select 属性配置。
4 9 Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?(必会)………………
Mybatis仅支持association关联对象和collection关联集合对象的延迟加 载,association指的就是一对一,collection指的就是一对多查询。在Mybatis 配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。 它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时, 进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现 a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把 B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成 a.getB().getName()方法的调用。这就是延迟加载的基本原理。
4 10 Mybatis的一级.二级缓存(必会)………………………………………………………………………..
1 )一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作 用域为 Session,当 Sessionflush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存且不能关闭。 2 )二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache, HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自 定义存储源,如 Ehcache。默认不打开二级缓存,要手动开启二级缓存,使用 二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在 它的映射文件中配置。
3 )对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存 Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存 将被 clear。
五.Spring框架……………………………………………………………………………………………………………………
5 1 Spring是什么?(了解)…………………………………………………………………………………………….
Spring是一个轻量级的IoC和AOP容器框架。是为Java应用程序提供基 础性服务的一套框架,目的是用于简化企业应用程序的开发,它使得开发者只需 要关心业务需求。常见的配置方式有三种:基于XML的配置.基于注解的配置. 基于Java的配置。 主要由以下几个模块组成: SpringCore:核心类库,提供IOC服务; SpringContext:提供框架式的Bean访问方式,以及企业级功能(JNDI. 定时任务等); SpringAOP:AOP服务; SpringDAO:对JDBC的抽象,简化了数据访问异常的处理; SpringORM:对现有的ORM框架的支持; SpringWeb:提供了基本的面向Web的综合特性,例如多方文件上传; SpringMVC:提供面向Web应用的Model-View-Controller实现。
5 2 Spring的AOP理解?(必会)………………………………………………………………………………
OOP面向对象,允许开发者定义纵向的关系,但并适用于定义横向的关系,
导致了大量代码的重复,而不利于各个模块的重用。
AOP,一般称为面向切面,作为面向对象的一种补充,用于将那些与业务
无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的
模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低 了模块间的耦合度,同时提高了系统的可维护性。可用于权限认证.日志.事务处 理。
AOP实现的关键在于代理模式,AOP代理主要分为静态代理和动态代理。
静态代理的代表为AspectJ;动态代理则以SpringAOP为代表。 ( 1 )AspectJ是静态代理的增强,所谓静态代理,就是AOP框架会在编 译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切 面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。 ( 2 )SpringAOP使用的动态代理,所谓的动态代理就是说AOP框架不会 去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个 AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回 调原对象的方法。 SpringAOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态 代理: ( 1 )JDK动态代理只提供接口代理,不支持类代理,核心InvocationHandler 接口和Proxy类,InvocationHandler通过invoke()方法反射来调用目标类中 的代码,动态地将横切逻辑和业务编织在一起,Proxy利用 InvocationHandler 动态创建一个符合某一接口的的实例, 生成目标类的代理对象。 ( 2 )如果代理类没有实现 InvocationHandler 接口,那么SpringAOP会 选择使用CGLIB来动态代理目标类。CGLIB(CodeGenerationLibrary),是 一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖 其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的 动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代 理的。 ( 3 )静态代理与动态代理区别在于生成AOP代理对象的时机不同,相对 来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译 器进行处理,而SpringAOP则无需特定的编译器处理。 InvocationHandlerinvoke(Object proxy,Method method,Object[] args):proxy是最终生成的代理实例; method 是被代理目标实例的某个具体 方法;args是被代理目标实例某个方法的具体入参, 在方法反射调用时使用。
5 3 Spring的IOC理解?(必会)………………………………………………………………………………..
( 1 )IOC就是控制反转,是指创建对象的控制权的转移,以前创建对象的
主动权和时机是由自己把控的,而现在这种权力转移到Spring容器中,并由容 器根据配置文件去创建实例和管理各个实例之间的依赖关系,对象与对象之间松
散耦合,也利于功能的复用。DI依赖注入,和控制反转是同一个概念的不同角
度的描述,即 应用程序在运行时依赖IoC容器来动态注入对象需要的外部资源。 ( 2 )最直观的表达就是,IOC让对象的创建不用去new了,可以由spring 自动生产,使用java的反射机制,根据配置文件在运行时动态的去创建对象以 及管理对象,并调用对象的方法的。 ( 3 )Spring的IOC有三种注入方式 :构造器注入,setter方法注入, 根据 注解注入。 IOC让相互协作的组件保持松散的耦合,而AOP编程允许你把遍布于应用 各层的功能分离出来形成可重用的功能组件。
5 4 BeanFactory和ApplicationContext有什么区别?(了解)…………………………………
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以 当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。 ( 1 )BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定 义,读取bean配置文档,管理bean的加载.实例化,控制bean的生命周期, 维护bean之间的依赖关系。ApplicationContext接口作为BeanFactory的派 生。 ( 2 )BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用 到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们 就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入, BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。 ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这 样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检 查所依赖属性是否注入。ApplicationContext启动后预载入所有的单实例 Bean,通过预载入单实例bean,确保当你需要的时候,你就不用等待,因为它 们已经创建好了。 相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存 空间。当应用程序配置Bean较多时,程序启动较慢。 ( 3 )BeanFactory通常以编程的方式被创建,ApplicationContext还能 以声明的方式创建,如使用ContextLoader。
( 4 )BeanFactory和ApplicationContext都支持。 BeanPostProcessor.BeanFactoryPostProcessor的使用,但两者之间的区别 是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
5 5 请解释SpringBean的生命周期?(必会)…………………………………………………………..
首先说一下Servlet的生命周期:实例化,初始init,接收请求service, 销毁destroy; Spring上下文中的Bean生命周期也类似,如下: ( 1 )实例化Bean: 对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时, 或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用 createBean进行实例化。对于ApplicationContext容器,当容器启动结束后, 通过获取BeanDefinition对象中的信息,实例化所有的bean。 ( 2 )设置对象属性(依赖注入): 实例化后的对象被封装在BeanWrapper对象中,紧接着,Spring根据 BeanDefinition中的信息 以及 通过BeanWrapper提供的设置属性的接口完 成依赖注入。 ( 3 )处理Aware接口: 接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的 xxxAware实例注入给Bean: 如果这个Bean已经实现了BeanNameAware接口,会调用它实现的 setBeanName(StringbeanId)方法,此处传递的就是Spring配置文件中Bean 的id值; 如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的 setBeanFactory()方法,传递的是Spring工厂自身。 如果这个Bean已经实现了ApplicationContextAware接口,会调用 setApplicationContext(ApplicationContext)方法,传入Spring上下文; ( 4 )BeanPostProcessor: 如果想对Bean进行一些自定义的处理,那么可以让Bean实现了 BeanPostProcessor接口,那将会调用 postProcessBeforeInitialization(Objectobj,Strings)方法。由于这个方法是 在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术; ( 5 )InitializingBean与init-method:
如果Bean在Spring配置文件中配置了 init-method属性,则会自动调 用其配置的初始化方法。 ( 6 )如果这个Bean实现了BeanPostProcessor接口,将会调用 postProcessAfterInitialization(Objectobj,Strings)方法; 以上几个步骤完成后,Bean就已经被正确创建了,之后就可以使用这个 Bean了。 ( 7 )DisposableBean: 当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean 这个接口,会调用其实现的destroy()方法; ( 8 )destroy-method: 最后,如果这个Bean的Spring配置中配置了destroy-method属性,会 自动调用其配置的销毁方法。
5 6 解释Spring支持的几种bean的作用域。(必会)……………………………………………….
Spring容器中的bean可以分为 5 个范围: ( 1 )singleton:默认,每个容器中只有一个bean的实例,单例的模式由 BeanFactory自身来维护。 ( 2 )prototype:为每一个bean请求提供一个实例。 ( 3 )request:为每一个网络请求创建一个实例,在请求完成以后,bean 会失效并被垃圾回收器回收。 ( 4 )session:与request范围类似,确保每个session中有一个bean的 实例,在session过期后,bean会随之失效。 ( 5 )global-session:全局作用域,global-session和Portlet应用相关。 当你的应用部署在Portlet容器中工作时,它包含很多portlet。如果你想要声 明让所有的portlet共用全局的存储变量的话,那么这全局变量需要存储在 global-session中。全局作用域与Servlet中的session作用域效果相同。
5 7 spring常见的注解(必会)…………………………………………………………………………………….
@Configuration把一个类作为一个IoC容器,它的某个方法头上如果注册了 @Bean,就会作为这个Spring容器中的Bean。 @Scope注解 作用域 @Lazy(true) 表示延迟初始化 @Service用于标注业务层组件.
@Controller用于标注控制层组件(如struts中的action) @Repository用于标注数据访问组件,即DAO组件。 @Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行 标注。 @Scope用于指定scope作用域的(用在类上) @PostConstruct用于指定初始化方法(用在方法上) @PreDestory用于指定销毁方法(用在方法上) @Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。 @DependsOn:定义Bean初始化及销毁时的顺序 @Primary:自动装配时当出现多个Bean候选者时,被注解为@Primary的 Bean将作为首选者,否则将抛出异常 @Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。 @Autowired 默认按类型装配,如果我们想使用按名称装配,可以结合 @Qualifier注解一起使用。如下:@Autowired@Qualifier(“personDaoBean”) 存在多个实例配合使用
5 8 Spring框架中的单例Beans是线程安全的么?(了解)………………………………………..
Spring框架并没有对单例bean进行任何多线程的封装处理。关于单例 bean的线程安全和并发问题需要开发者自行去搞定。但实际上,大部分的 Springbean并没有可变的状态(比如Serview类和DAO类),所以在某种程度 上说Spring的单例bean是线程安全的。如果你的bean有多种状态的话(比 如 ViewModel 对象),就需要自行保证线程安全。最浅显的解决办法就是将 多态bean的作用域由“singleton”变更为“prototype”。
5 9 Spring如何处理线程并发问题?(必会)……………………………………………………………….
在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring 中,绝大部分Bean都可以声明为singleton作用域,因为Spring对一些Bean 中非线程安全状态采用ThreadLocal进行处理,解决线程安全问题。 ThreadLocal和线程同步机制都是为了解决多线程中相同变量的访问冲突 问题。同步机制采用了“时间换空间”的方式,仅提供一份变量,不同的线程在 访问前需要获取锁,没获得锁的线程则需要排队。而ThreadLocal采用了“空 间换时间”的方式。
ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线 程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必 要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线 程代码时,可以把不安全的变量封装进ThreadLocal。
5 10 Spring基于xml注入bean的几种方式(必会)………………………………………………….
( 1 )Set方法注入;……………………………………………………………………………………………..
( 2 )构造器注入:………………………………………………………………………………………………..
1 .通过index设置参数的位置;
2 .通过type设置参数类型;
3 .通过name注入;
( 3 )静态工厂注入;…………………………………………………………………………………………….
( 4 )实例工厂;……………………………………………………………………………………………………
5 11 Spring框架中都用到了哪些设计模式?(高薪必问)………………………………………….
( 1 )工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的 实例; ( 2 )单例模式:Bean默认为单例模式。 ( 3 )代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节 码生成技术; ( 4 )模板方法:用来解决代码重复的问题。 比如.RestTemplate,JmsTemplate,JpaTemplate。 ( 5 )观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态 发生改变时,所有依赖于它的对象都会得到通知被制动更新,如Spring中 listener的实现–ApplicationListener。
5 12 Spring事务的实现方式和实现原理(高薪必问)………………………………………………….
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持, spring是无法提供事务功能的。真正的数据库层的事务提交和回滚是通过 binlog或者redolog实现的。
( 1 )Spring事务的种类:…………………………………………………………………………………….
spring支持编程式事务管理和声明式事务管理两种方式: A.编程式事务管理使用TransactionTemplate。 B.声明式事务管理建立在AOP之上的。其本质是通过AOP功能,对方法前 后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之 前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。 声明式事务最大的优点就是不需要在业务逻辑代码中掺杂事务管理的代码, 只需在配置文件中做相关的事务规则声明或通过@Transactional注解的方式, 便可以将事务规则应用到业务逻辑中。 声明式事务管理要优于编程式事务管理,这正是spring倡导的非侵入式的 开发方式,使业务代码不受污染,只要加上注解就可以获得完全的事务支持。唯 一不足地方是,最细粒度只能作用到方法级别,无法做到像编程式事务那样可以 作用到代码块级别。
( 2 )Spring的事务传播行为:……………………………………………………………………………..
Spring事务的传播行为说的是,当多个事务同时存在的时候,Spring如何 处理这些事务的行为。 ① PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务, 如果当前存在事务,就加入该事务,该设置是最常用的设置。 ② PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就 加入该事务,如果当前不存在事务,就以非事务执行。‘ ③ PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务, 就加入该事务,如果当前不存在事务,就抛出异常。 ④ PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事 务,都创建新事务。 ⑤ PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当 前存在事务,就把当前事务挂起。 ⑥ PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则 抛出异常。 ⑦ PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。 如果当前没有事务,则按REQUIRED属性执行。
( 3 )Spring中的隔离级别:…………………………………………………………………………………
①ISOLATION_DEFAULT:这是个PlatfromTransactionManager默认的 隔离级别,使用数据库默认的事务隔离级别。
②ISOLATION_READ_UNCOMMITTED:读未提交,允许另外一个事务可
以看到这个事务未提交的数据。
③ISOLATION_READ_COMMITTED:读已提交,保证一个事务修改的数
据提交后才能被另一事务读取,而且能看到该事务对已有记录的更新。
④ISOLATION_REPEATABLE_READ:可重复读,保证一个事务修改的数据
提交后才能被另一事务读取,但是不能看到该事务对已有记录的更新。
⑤ISOLATION_SERIALIZABLE:一个事务在执行的过程中完全看不到其他
事务对数据库所做的更新。
5 13 解释一下SpringAOP里面的几个名词(了解)…………………………………………………..
( 1 )切面(Aspect):被抽取的公共模块,可能会横切多个对象。在Spring AOP中,切面可以使用通用类(基于模式的风格)或者在普通类中 以@AspectJ注解来实现。 ( 2 )连接点(Joinpoint):指方法,在SpringAOP中,一个连接点总 是代表一个方法的执行。 ( 3 )通知(Advice):在切面的某个特定的连接点(Joinpoint)上执行 的动作。通知有各种类型,其中包括“around”.“before”和“after”等通知。 许多AOP框架,包括Spring,都是以拦截器做通知模型,并维护一个以连接 点为中心的拦截器链。 ( 4 )切入点(Pointcut):切入点是指 我们要对哪些Joinpoint进行拦截 的定义。通过切入点表达式,指定拦截的方法,比如指定拦截add*.search*。 ( 5 )引入(Introduction):(也被称为内部类型声明(inter-type declaration))。声明额外的方法或者某个类型的字段。Spring允许引入新的 接口(以及一个对应的实现)到任何被代理的对象。例如,你可以使用一个引入 来使bean实现IsModified接口,以便简化缓存机制。 ( 6 )目标对象(TargetObject):被一个或者多个切面(aspect)所通 知(advise)的对象。也有人把它叫做被通知(adviced)对象。既然Spring AOP是通过运行时代理实现的,这个对象永远是一个被代理(proxied)对象。 ( 7 )织入(Weaving):指把增强应用到目标对象来创建新的代理对象的 过程。Spring是在运行时完成织入。
切入点(pointcut)和连接点(joinpoint)匹配的概念是AOP的关键,这 使得AOP不同于其它仅仅提供拦截功能的旧技术。切入点使得定位通知 (advice)可独立于OO层次。例如,一个提供声明式事务管理的around通 知可以被应用到一组横跨多个对象中的方法上(例如服务层的所有业务操作)。
5 14 Spring通知有哪些类型?(了解)……………………………………………………………………….
( 1 )前置通知(Beforeadvice):在某连接点(joinpoint)之前执行的 通知,但这个通知不能阻止连接点前的执行(除非它抛出一个异常)。 ( 2 )返回后通知(Afterreturningadvice):在某连接点(joinpoint) 正常完成后执行的通知:例如,一个方法没有抛出任何异常,正常返回。 ( 3 )抛出异常后通知(Afterthrowingadvice):在方法抛出异常退出时 执行的通知。 ( 4 )后通知(After(finally)advice):当某连接点退出的时候执行的通知 (不论是正常返回还是异常退出)。 ( 5 )环绕通知(AroundAdvice):包围一个连接点(joinpoint)的通知, 如方法调用。这是最强大的一种通知类型。环绕通知可以在方法调用前后完成 自定义的行为。它也会选择是否继续执行连接点或直接返回它们自己的返回值或 抛出异常来结束执行。环绕通知是最常用的一种通知类型。大部分基于拦截的 AOP框架,例如Nanning和JBoss 4 ,都只提供环绕通知。
六.SpringMVC框架……………………………………………………………………………………………………………
6 1 什么是SpringMVC?简单介绍下你对SpringMVC的理解?(了解)…………………..
SpringMVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻 量级Web框架,通过把Model,View,Controller分离,将web层进行职责 解耦,把复杂的web应用分成逻辑清晰的几部分,简化开发,减少出错,方便 组内开发人员之间的配合。
6 2 SpringMVC的流程?(必会)………………………………………………………………………………..
( 1 )用户发送请求至前端控制器DispatcherServlet; ( 2 ) DispatcherServlet收到请求后,调用HandlerMapping处理器映 射器,请求获取Handle; ( 3 )处理器映射器根据请求url找到具体的处理器,生成处理器对象及处 理器拦截器(如果有则生成)一并返回给DispatcherServlet; ( 4 )DispatcherServlet 调用 HandlerAdapter处理器适配器; ( 5 )HandlerAdapter 经过适配调用 具体处理器(Handler,也叫后端控 制器);
( 6 )Handler执行完成返回ModelAndView; ( 7 )HandlerAdapter将Handler执行结果ModelAndView返回给 DispatcherServlet; ( 8 )DispatcherServlet将ModelAndView传给ViewResolver视图解析 器进行解析; ( 9 )ViewResolver解析后返回具体View; ( 10 )DispatcherServlet对View进行渲染视图(即将模型数据填充至视 图中) ( 11 )DispatcherServlet响应用户。
6 3 SpringMVC的主要组件?(必会)…………………………………………………………………………
( 1 )前端控制器DispatcherServlet(不需要程序员开发)…………………………………
作用:接收请求.响应结果,相当于转发器,有了DispatcherServlet 就减少了 其它组件之间的耦合度。
( 2 )处理器映射器HandlerMapping(不需要程序员开发)……………………………….
作用:根据请求的URL来查找Handler
( 3 )处理器适配器HandlerAdapter…………………………………………………………………….
注意:在编写Handler的时候要按照HandlerAdapter要求的规则去编写,这 样适配器HandlerAdapter才可以正确的去执行Handler。
( 4 )处理器Handler(需要程序员开发)…………………………………………………………….
( 5 )视图解析器ViewResolver(不需要程序员开发)………………………………………..
作用:进行视图的解析,根据视图逻辑名解析成真正的视图(view)
( 6 )视图View(需要程序员开发jsp)………………………………………………………………..
View是一个接口, 它的实现类支持不同的视图类型(jsp,freemarker,pdf 等等)
6 4 SpringMVC和Struts 2 的区别有哪些?(必问)……………………………………………………..
( 1 )SpringMVC的入口是一个servlet即前端控制器(DispatchServlet), 而struts 2 入口是一个filter过虑器(StrutsPrepareAndExecuteFilter)。 ( 2 )SpringMVC是基于方法开发(一个url对应一个方法),请求参数传递 到方法的形参,可以设计为单例或多例(建议单例),struts 2 是基于类开发,传 递参数是通过类的属性,只能设计为多例。 ( 3 )Struts采用值栈存储请求和响应的数据,通过OGNL存取数据,
SpringMVC通过参数解析器是将request请求内容解析,并给方法形参赋值, 将数据和视图封装成ModelAndView对象,最后又将ModelAndView中的模 型数据通过reques域传输到页面。Jsp视图解析器默认使用jstl。
6 5 SpringMVC怎么和Ajax相互调用的?(必会)…………………………………………………….
通过Jackson框架就可以把Java里面的对象直接转化成Js可以识别的Json 对象。具体步骤如下 : ( 1 )加入Jackson.jar ( 2 )在配置文件中配置json的映射 ( 3 )在接受Ajax方法里面可以直接返回Object,List等,但方法前面要加上 @ResponseBody注解。
6 6 如何解决Post请求中文乱码问题,Get的又如何处理呢?(了解)………………………
( 1 )解决post请求乱码问题:…………………………………………………………………………….
在web.xml中配置一个CharacterEncodingFilter过滤器,设置成utf- 8 ;
<<ffiilltteerr>-name>CharacterEncodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<p<ainraitm-p-anraamme>>encoding</param-name>
<<p/ianriat-mp-avraalmue>>utf- 8 </param-value>
</filter>
<fi<ltfeirlt-emr-anpapmineg>>CharacterEncodingFilter</filter-name>
</<filuterlr--pmaattpeprnin>g/>*</url-pattern>
( 2 )get请求中文参数出现乱码解决方法有两个:……………………………………………….
修改tomcat配置文件添加编码与工程编码一致,如下: <ConnectorURIEncoding=“utf- 8 “connectionTimeout=” 20000 “port =” 8080 “protocol=“HTTP/ 1. 1 “redirectPort=” 8443 “/> 另外一种方法对参数进行重新编码:
StringuserName=newString(request.getParamter(“userName”).get Bytes(“ISO 8859 - 1 “),“utf- 8 “) ISO 8859 - 1 是tomcat默认编码,需要将tomcat编码后的内容按utf- 8 编 码。
6 7 SpringMVC常用的注解有哪些?(必问)………………………………………………………………
@RequestMapping:用于处理请求 url 映射的注解,可用于类或方法上。 用于类上,则表示类中的所有响应请求的方法都是以该地址作为父路径。
@RequestBody:注解实现接收http请求的json数据,将json转换为java 对象。
@ResponseBody:注解实现将conreoller方法返回对象转化为json对象 响应给客户。
6 8 SpringMVC里面拦截器是怎么写的?(了解)……………………………………………………….
有两种写法,一种是实现HandlerInterceptor接口,另外一种是继承适配器 类,接着在接口方法当中,实现处理逻辑;然后在SpringMVC的配置文件中配 置拦截器即可:
<beanid=“myInterceptor” class=“com.zwp.action.MyHandlerInterceptor”>
mvc:interceptor mvc:mappingpath="/modelMap.do"/ <beanclass=“com.zwp.action.MyHandlerInterceptorAdapter”/> </mvc:interceptor> </mvc:interceptors>
七.Saas项目……………………………………………………………………………………………………………………….
7 1 介绍话术…………………………………………………………………………………………………………………
我做的是一个XXX的国际货运平台, 满足国际货运企业的基础数据管理、
业务过程管理、辅助决策、财务管理等要求(包括模块海运、空运、海空联
运);实现接受委托、进仓通知、订仓、报关、费用结算等一系列流程的高
度集成,多界面数据共享,对同一票货数据基本可以在同一屏幕内完成,无
需频繁切换画面,操作方便,大大提高效率。系统模块主要包含:
基础信息管理,系统管理,货运管理,报表管理,统计分析,财务管理,业
务处理,调度管理等。 我们项目前端主要使用adminLTE+Ztree技术,后
端使用ssm集成框架。安全框架我们使用shiro框架基于RBAC的设计思想
进行实现权限管理。出货单,购销合同的导入导出我们使用POI技术进行实
现。为了降低项目耦合度,便于后期扩展,我们这里引入SOA思想,使用
了Dubbo服务中间件。
7 2 名词与概念……………………………………………………………………………………………………………..
SaaS(Software-as-a-Service),即软件即服务。提供给消费者完
整的软件解决方案,你可以从软件服务商处以租用或购买等方式获取软件应
用,组织用户即可通过 Internet 连接到该应用(通常使用 Web 浏览器)。
所有基础结构.中间件.应用软件和应用数据都位于服务提供商的数据中心
内。服务提供商负责管理硬件和软件,并根据适当的服务协议确保应用和数
据的可用性和安全性。SaaS 让组织能够通过最低前期成本的应用快速建成
投产。
SaaS 软件就适用对象而言,可以划分为针对个人的与针对企业的面
向个人的 SaaS 产品:在线文档,账务管理,文件管理,日程计划.照片管 理.联系人管理,等等云类型的服务。而面向企业的 SaaS 产品主要包括: CRM(客户关系管理).ERP(企业资源计划管理).线上视频或者与群组通 话会议.HRM(人力资源管理).OA(办公系统).外勤管理.财务管理.审批管理 等。 SaaS与传统软件相比,a.能够降低企业成本:按需购买,即租即用, 无需关注软件的开发维护。b.软件更新迭代快速:和传统软件相比,由于 saas部署在云端,使得软件的更新迭代速度加快。c.支持远程办公:将数据 存储到云后,用户即可通过任何连接到 Internet 的计算机或移动设备访问 其信息。 PaaS(Platform-as-a-Service),即平台即服务。提供给消费者的 服务是把客户采用提供的开发语言和工具(例如 Java,python,.Net 等) 开发的或收购的应用程序部署到供应商的云计算基础设施上去。客户不需要 管理或控制底层的云基础设施,包括网络.服务器.操作系统.存储等,但客户 能控制部署的应用程序,也可能控制运行应用程序的托管环境配置。 IaaS(InfrastructureasaService),即基础设施即服务。提供给 消费者的服务是对所有计算基础设施的利用,包括处理 CPU.内存.存储.网络 和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应 用程序。消费者不管理或控制任何云计算基础设施,但能控制操作系统的选 择.存储空间.部署的应用,也有可能获得有限制的网络组件(例如路由器.防 火墙.负载均衡器等)的控制。
7 3 货运管理业务讲解:……………………………………………………………………………………………….
我们项目中负责的业务逻辑不多,就是一些基本技术的使用。主要复杂的地
方就是货运管理。这个模块主要包含:购销合同,出货表,合同管理,出口报运,
装箱管理,委托管理,发票管理,财务管理等(说不全也行,但是标黑的一定要
说)。 我简单说说这块的业务:
公司销售和海外客户签订订单(合同),客户订单中的货物,公司就联系这
些(多个)厂家来生产,和生产厂家签订合同,这个合同就叫“购销合同”。购
销合同的内容主要由三部分组成,购销合同的主信息,和多个货物的信息,和多
个附件的信息。(附件实际就是货物) 购销合同打印出后,将每张纸交给对应
生产厂家的销售代表(公司) 购销合同打印要求,可以每页只打印一款货物,
也可以打印两款货物。用户可以自己选择。 如果每页打印两款货物,必须是同
一个生产厂家,如果不是同一个生产厂家,必须另起一页。进行打印的时候我们
可以选择是PDF打印,还是word,Excel打印。在查询购销合同总金额时,就 需要关联加载购销合同下的所有货物,并要加载所有货物下的所有附件,这样可 能实现购销合同总金额查询消耗时间太多,而用户等不起,此时就可以在平时添 加货物时,添加附件时,分别计算出货物总金额,附件总金额 ,再更新购销合 同总金额 ,这样就相当于将一次集中计算的工作 量分散到平时的多次计算过程 中,所以查询购销合同总金额时速度就会很快。 购销合同涉及的表有:购销合同表,购销合同货物表,购销合同附件,报运 单,生产厂家等表。购销合同(一)和购销合同货物(多)表是一对多的关系。购销 合同货物和合同附件也是一对多的关系。 货物(多)和厂家(一)是多对一的关系, 货物和附件是一对多的关系。
项目中不错的设计技巧:
因为货运管理涉及的表关系比较多,多表联查容易造成一些冗余数据,同时
会降低查询效率。在做报运这块我们采取的两个策略,针对于一对一我们采取的
是共享主键(多个表共用一个主键,主键相同),一个是一对多,我们采取打断设
计(在表和表一的一方创建一个id列表)来实现跳跃查询的方式来进行处理。 版本二: 我们项目中负责的业务逻辑不多,就是一些基本技术的使用。主要复杂的地 方就是货运管理。这个模块主要包含:购销合同,出货表,合同管理,出口报运, 装箱管理,委托管理,发票管理,财务管理等(说不全也行,但是标黑的一定要 说)。这边先确认买卖方是否签订了购销合同,购销合同提交后我们这边会生成 合同列表。在合同列表里边我们可以勾选买卖双方确认的合同,然后选择报运, 进行统一集装箱进行发货。发货方会收到委托公司给我我们发的一个委托单,确 认好委托公司及委托产品信息及唛头,发货时间,然后开始发货,当发货后这边 会有一个发票生成,财务会根据发票进行收货方催单进行尾款补缴。 对应的表关系:
购销合同列表展示:
出口报运单:
报运单表:<通过点击报运单的查看,我们可以看到右上方有个导出,
我们可以按照模板进行导出>
在购销合同列表里边我们包含的操作有编辑货物,货物,上传货物。通过点
击货物我们可以进入货物详情页面。上边是一些客户和备注货期等信息,下边显
示的就是这个合同里边包含的具体信息。在货物列表信息的操作里边我们有一个
附件的操作,通过点击,我们可以查看当前货物对接的附件信息,附件主要包含
的是对当前货物的一些包装方式,特殊要求,价格,总价,生产厂家等。当新添
加了附件信息,整体的货物价格都会随着发生改变,我们在附件保存的同时会调
取货物信息列表,进行更新新的数据。
在合同管理里边我们可以通过勾选合同,来添加报运单,在报运单里边确认
好唛(mai)头,收货地址,运输方式等。通过点击保存生成报运单,同时修改合 同的状态。把对应的合同从列表里边移除。
保持出口报运单的流程:
1 .基础信息管理:交通工具(辅助工具)登记、驾驶人员信息、客户信
息、公司职员信息、承运货物信息、仓库信息、计量单位信息等。
2 .系统管理:更改密码、数据备份、数据恢复、清除业务数据、操作员
日志及系统权限。
3 .业务处理:接单登记、运单生成、运费清单、交通工具安排、路线确
认、送货管理、接货管理、业务结算(预收管理、垫付管理、货到付款运费
结算、委托结货款实结确认、回单管理)等内容。
4 .财务管理:应收运费核计、应付运费核计、业务结算审核、内部资金
流转等。
5 .统计分析:单证查询、客户业务记录(金额)统计、运费查询、年度
业务统计等。
7 4 开发环境与技术:…………………………………………………………………………………………………..
后端框架采用 Spring+SpringMVC+Mybatis+Dubbo+七牛云+POI+ 前端框架采用 AdminLTE技术,(AdminLTE是一款建立bootstrap和jquery 之上的开源的模板主题工具,它提供了一系列响应的、可重复使用 的组件,并 内置了多个模板页面;同时自适应多种屏幕分辨率,兼容 PC 和移动端。通过 AdminLTE,我们可以快速 的创建一个响应式的 Html 5 网站。)还采用Ztree 技术(因为他是依靠 jQuery 实现的多功能“树插件”。同时它也是开源免费的, 兼容不同的浏览器<IE、FireFox、Chrome、Opera、Safari>,支持json数据 格式,支持静态和ajax异步加载节点数据。). 我们项目中使用PD(PowerDesigner)建模工具进行建表,方便省事,便于 开发。整个项目中涉及到分页的地方,我们之前使用的pageBean和pageResult 做的(对象中要定义 currentPage,pageSize,count,totalPage,List等属性, 并在 dao 中编写相应的代码查 询出分页结果封装到 PageBean 中。),后来 做了调整,我们使用了mybatis的pageHelper分页插件,直接在pom里边进 行配置就解决了这个分页的问题。 因为做的项目是涉及海外运输的,所以我们要上传照片给海关和客户进行查 看。我们这里采用的是七牛云进行图片上传和图片展示的。确保了信息的安全和 节省开发成本。通过公司进行注册七牛云账号,我们在使用时提供客户端上传所 需要的凭证(空间,域名,accessKey,SecretKey)结合七牛云提供SDK进行操 作。SDK里边有对应的代码,我们直接拷贝就好。
7 5 项目亮点设计………………………………………………………………………………………………………….
多租户管理(多租户是一种架构,目的是为了让多用户环境下使用同一套程
序,且保证用户间数据隔离。那么重点就很浅显易懂了,多租户的重点就是同一
套程序下实现多用户数据的隔离 ) 我们采取的第二种方案,共享数据库、独立
Schema。这样做的好处是为安全性要求较高的租户提供了一定程度的逻辑数据 隔离,并不是完全隔离; 每个数据库可支持更多的租户数量。 我们数据库表设计采用的是PowerDesigner建模工具。使用他的优势是不 用在使用 createtable 等语句创建表结构,数据库设计人员只关注如何进行数 据建模即可,将来的数据库语句, 可以自动生成. 解决多租户数据库设计有 3 中方案: 1 .独立数据库 2 .共享数据库、独立 Schema 3 .共享数据库、共享数据表 基于角色的访问控制的RBAC 的设计思路 (项目中设计的权限管理,SaaS 管理基本所有功能都能操作管理,但是不能对租户的具体业务进行管理。) 关于项目中的权限我们使用的是基于角色的访问控制的RBAC 的设计思路, 前端我们这边做的处理是通过判断用户是否具备对应的权限来动态展示菜单列 表,在有的菜单功能里边我们也会根据不同企业的租户用户来显示细粒度控制的 结果。比如:在同一个页面是否具有修改和删除的功能。 项目中我们日志统计采用的是Spring的Aop,通过在 applicationContext.xml里边进行配置开启注解扫描,通过配置切面类,实现 对指定业务进行日志保存。常用的注解有:@Before :前置通知 @AfterReturning:后置通知 @Around :环绕通知 @AfterThrowing:异常抛 出通知 @After :最终通知。主要用在用户,客户对信息进行操作时,方便进
行查看。
7 6 项目技术与业务………………………………………………………………………………………………………
7 6 1 分页查询业务………………………………………………………………………………………………..
7. 6. 1. 1 传统分页 我们之前分页是使用一个 PageBean 对象封装分页数据的。对象中要定义 currentPage,pageSize,count,totalPage,List等属性,并在 dao中编写相 应的代码查询出分页结果封装到 PageBean 中。 7. 6. 1. 2 PageHelper PageHelper是国内非常优秀的一款开源的 mybatis分页插件,它支持基 本主流与常用的数据库,例如 MySQL.oracle.mariaDB.DB 2 .SQLite.Hsqldb 等。 PageHelper.startPage 静态方法调用:在需要进行分页的 MyBatis查询 方法前调用 PageHelper.startPage静态方法即可,紧跟在这个方法后的第一 个 MyBatis查询方法会被进行分页。 例://获取第 1 页, 10 条内容,默认查询总数 count PageHelper.startPage( 1 , 10 ); //紧跟着的第一个 select 方法会被分页 Listlist=countryMapper.selectIf( 1 );
7 6 2 权限………………………………………………………………………………………………………………
SAAS 平台管理员:负责平台的日常维护和管理,包括用户日志的
管理.租户账号审核.租户状态管理.租户费用的管理,要注意的是平台管理员
不能对租户的具体业务进行管理。
企业租户:指访问 SaaS 平台的用户企业,在 SaaS 平台中各租户
之间信息是独立的。
租户管理员:为租户角色分配权限和相关系统管理.维护。
租户用户:需对租户用户进行角色分配,租户用户只能访问授权的
模块信息。
7 6 3 动态构造菜单………………………………………………………………………………………………..
1. 根据登录用户的用户信息查询模块。
2 .SaaS 管理员,租户企业管理员直接查询即可。
3. 普通用户,通过用户的角色以及角色和模块之间的关联关系查询。
4. 将模块信息保存到 session 中。
5. 页面动态拼接菜单。
7 6 4 Shiro……………………………………………………………………………………………………………..
登录方式
使用步骤
第一步:在maven父工程中的pom.xml中导入坐标; 第二步:配置spring中提供的shiro过滤器 (一当十的过滤器); 第三步:在 spring的配置文件中配置代理方式; 第四步:创建shiro的spring配置文件; 第五步:自定义realm域; 第六步:自定义密码比较器; 第七步:页面使shiro标签,/home/title.jsp主菜单。 (spring+shiro实现路径 https://www.cnblogs.com/jpfss/p/ 8352031 .html) 我们在项目中通过配置shiro的坐标,配置shiro的过滤器(shiro 的 filter必须 在 springmvc 的字符集 filter 之前),然后再创建个application-shiro.xml 的配置文件。在里边配置好密码比较器,配置缓存,配置密码加密算法,配置好 哪些资源是匿名访问(anon)的,哪些资源是需要认证(authc)的。然后通过配置 realm来实现认证和授权功能。然后根据用户的级别,查询当前用户拥有的所有 的角色,根据角色在前端进行页面动态拼接。但是不同的用户除了展菜单不一致 外,还有对应菜单的功能也不一样。比如:如果是货运SaaS的管理员,可以查 看所有功能,如果是租户的员工,那么可能只有查看的功能。这里我们需要进行 细粒度控制,我们可以通过再shiro对应的配置文件里边配置(通过配置匿名和 受保护的,然后配置对应的url路径),也可以使用shiro标签来进行细化功能。 比如:在用户管理页面,通过配置shiro:hasPermissionname="abc" 标签 <拥有权限资源abc>。 比如还有其他标签:
shiro:principal 显示用户身份名称 shiro:authenticated 登录之后 shiro:notAuthenticated不在登录状态时 shiro:guest 用户在没有RememberMe时 shiro:user 用户在RememberMe时 <shiro:hasAnyRolesname=“abc, 123 “> 在有abc或者 123 角色时 shiro:hasRolename="abc" 拥有角色abc shiro:lacksRolename="abc" 没有角色abc shiro:hasPermissionname="abc" 拥有权限资源abc shiro:lacksPermissionname="abc" 没有abc权限资源 shiro:principalproperty="username"/ 显示用户身份中的属性值 认证的流程是:
1 、创建token令牌,token中有用
户提交的认证信息即账号和密码
2 、执行subject.login(token),最
终Au由thseenctuicraittyoMra进n行ag认e证r通过
3 、 Authenticator的实现
ModularRealmAuthenticator调用
r账ea号lm和密从码in,i这配里置使文用件的取是用I户ni真Re实a的lm
(shiro自带)
4 、 IniRealm先根据token中的账
号给去Moindiu中la找rR该ea账lm号A,u如th果en找tic不a到to则r
返配回密码nu成ll功,则如认果证找通到过则。匹配密码,匹
授权的流程是:
Shiro的缓存 为了提高认证和授权访问的效率,我们这边加入了shiro自带的Ehcache。 shiro每次授权都会通过realm获取权限信息,为了提高访问速度需要添加缓存, 第一次从realm中读取权限数据,之后不再读取,这里Shiro和Ehcache整合。 引入shiro的core和ehcacheJar包。在shiro的xml配置文件里边引入 缓存 的配置。我们在项目中配置的是shiro-ehcache.xml。里边主要配置了一些固定 参数,还配置了缓存持久化的目录(序列化地址)。<如果配置了缓存,那么在用 户修改权限后,我们这边一般都要写一个清除缓存的方法。>
1 、执行
sauteb"j)ect.isPermitted("user:cre
过Modu^2 l、arsReecaulrmitAyMutahnoargizeerr通进
行授权
3 、
Mreoadlmula获rR取e权al限m信Au息thorizer调用
4 、
ModularRealmAuthorizer再通
过限字pe符rm串i,ss校io验nR是es否o匹lve配r解析权
7 7 Dubbo…………………………………………………………………………………………………………………..
7 7 1 Dubbo的项目架构……………………………………………………………………………………..
1 ) 表现层拆分成一个单独的war包 2 ) 服务层拆分成一个单独的war包 3 )web层和service服务层通过dubbox服务治理中间件远程调用 1 .rpc 远程调用 hessain 2 二进制序列化 2 .nio异步通信 netty 4 )Dubbo服务治理特性描述 透明远程调用就像调用本地方法一样调用远程方法;只需简单配置,没 有任何API侵入; 负载均衡机制 Client端LB,可在内网替代F 5 等硬件负载均衡器; 容错重试机制 服务Mock数据,重试次数、超时机制等; 自动注册发现 注册中心基于接口名查询服务提供者的IP地址,并且能 够平滑添加或删除服务提供者; 性能日志监控Monitor统计服务的调用次调和调用时间的监控中心; 服务治理中心路由规则,动态配置,服务降级,访问控制,权重调整, 负载均衡,等手动配置。 自动治理中心无,比如:熔断限流机制、自动权重调整等; 5 ) <dubbo:protocolname=“dubbo"port=” 20881 “></dubbo:protocol>
dubbo:applicationname="pyg-manager-service"/
<dubbo:registryaddress=“zookeeper:// 192. 168. 25. 128 : 2181 “/>
dubbo:annotationpackage="com.pyg.manager.service.impl"/ 6 )默认使用Dubbo协议 连接个数:单连接 连接方式:长连接 传输协议:TCP 传输方式:NIO异步传输 序列化:Hessian二进制序列化 适用范围:传入传出参数数据包较小(建议小于 100 K),消费者比提 供者个数多,单一消费者无法压满提供者,尽量不要使用dubbo协议传输大文 件或超大字符串 使用场景:常规远程服务方法调用 从上面的适用范围总结,dubbo适合小数据量大并发的服务调用,以及消 费者机器远大于生产者机器数的情况,不适合传输大数据量的服务比如文件、视 频等,除非请求量很低。
7 7 2 什么是dubbo?…………………………………………………………………………………………..
工作在soa面向服务分布式框架中的服务管理中间件。Dubbo是一个分布 式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA
服务治理方案。
它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解
耦合(或者最大限度地松耦合)。从服务模型的角度来看,Dubbo采用的是一 种非常简单的模型,要么是提供方提供服务,要么是消费方消费服务,所以基于 这一点可以抽象出服务提供方(Provider)和服务消费方(Consumer)两个角 色。关于注册中心、协议支持、服务监控等内容。 Dubbo使用的是缺省协议, 采用长连接和nio异步通信, 适合小数据量 大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。 反之,dubbo缺省协议不适合传送大数据量的服务,比如传文件,传视频等, 除非请求量很低。
7 7 3 Dubbo的实现原理图如下…………………………………………………………………………..
7 7 4 节点角色说明………………………………………………………………………………………………
Provider: 暴露服务的服务提供方。
Consumer:调用远程服务的服务消费方。
Registry: 服务注册与发现的注册中心。
Monitor:统计服务的调用次调和调用时间的监控中心。
Container: 服务运行容器。
7 7 5 调用关系说明………………………………………………………………………………………………
1. 服务容器负责启动,加载,运行服务提供者。
2. 服务提供者在启动时,向注册中心注册自己提供的服务。
3. 服务消费者在启动时,向注册中心订阅自己所需的服务。
4. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将
基于长连接推送变更数据给消费者。
5. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供
者进行调用,如果调用失败,再选另一台调用。
6. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟
发送一次统计数据到监控中心。
7 7 6 在实际开发的场景中应该如何选择RPC框架………………………………………………
1. SpringCloud : Spring全家桶,用起来很舒服,只有你想不到,没有
它做不到。可惜因为发布的比较晚,国内还没出现比较成功的案例,大部
分都是试水,不过毕竟有Spring作背景,还是比较看好。
2. Dubbox: 相对于Dubbo支持了REST,估计是很多公司选择Dubbox
的一个重要原因之一,但如果使用Dubbo的RPC调用方式,服务间仍
然会存在API强依赖,各有利弊,懂的取舍吧。
- Thrift: 如果你比较高冷,完全可以基于Thrift自己搞一套抽象的自定 义框架吧。
- Hessian: 如果是初创公司或系统数量还没有超过 5 个,推荐选择这个, 毕竟在开发速度.运维成本.上手难度等都是比较轻量.简单的,即使在以后 迁移至SOA,也是无缝迁移。 rpcx/gRPC: 在服务没有出现严重性能的问题下,或技术栈没有变更的情况 下,可能一直不会引入,即使引入也只是小部分模块优化使用。
7 7 7 Dubbo面试问题汇总:………………………………………………………………………………
7. 7. 7. 1 什么是缺省协议?
缺省协议基于netty和hessina交互,传输方式是nio,序列化是hissian 二进制序列化,传说协议tcp,连接方式长连接。连接个数单链接。适用范围, 传入传出参数数据包较小(官方建议小与 100 K),消费者比提供者个数多,使 用场景,常规的远程服务方法调用。
7. 7. 7. 2 为什么不能传大包
因dubbo协议采用单一长连接,如果每次请求的数据包大小为 500 KByte,假 设网络为千兆网卡( 1024 Mbit= 128 MByte),每条连接最大 7 MByte(不同的环境 可能不一样,供参考),
单个服务提供者的TPS(每秒处理事务数)最大为:
128 MByte/ 500 KByte= 262 。
单个消费者调用单个服务提供者的TPS(每秒处理事务数)最大为:
7 MByte/ 500 KByte= 14 。
如果能接受,可以考虑使用,否则网络将成为瓶颈。
7. 7. 7. 3 Dubbo中的zookeeper做注册中心,如果注册中心集群都 挂掉,发布者和订阅者还能通信吗?
可以通信,启动dubbo时,消费者会从zk拉去注册的生产者的地址接口等 数据,缓存在本地,每次调用时,按照本地储存的地址进行调用。 注册中心对等集群,任意一台宕机后,将会切到另一台, 注册中心全部宕 机后, 服务的提供者和消费者仍能够通过本地缓存通讯, 服务提供者无状态, 任意一台宕机后,不影响使用,服务提供者全部宕机,服务消费者会无法使用并 且无限次重连等待服务者回复, 挂掉不是要紧的,但前提是你没有增加新的服 务,如果要调用新的服务,则是不能办到的
7. 7. 7. 4 dubbo服务的负载均衡策略?
A. RandomloadBalcance 随机按权重设置随机概率。在一个界面上碰
撞的概率高,单条用量越大分布越均匀,而且按概率使用权重后也比较均匀
有利于动态调整提供权重者。
B.roundRobinLoadBalance轮循,按公约后的权重设置轮训比率,存
在慢的提供者累积去请求问题.
例如,第二台机器很慢但是没挂。每当请求调用到第二台时就卡在那,久而
久之,所有的请求都卡在调到第二台上
C. leastActiveLoadBalance 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差,使慢的机 器收到更少,因为越慢的提供者的调用前后计数差会越大 例如,每个服务维护一个活跃数计数器。当A机器开始处理请求,该计数器 加 1 ,此时A还未处理完成(若处理完毕则计数器减 1 )。而B机器接受到请求后 很快处理完毕。那么A,B的活跃数分别是 1 , 0 。当又产生了一个新的请求,则 选择B机器去执行(B活跃数最小),这样使慢的机器A收到少的请求。 D.一致性hash 相同参数的请求总是发送到同一个提供者, 当某一台提供者挂了,原本发 往该提供者的请求,基于虚拟节点,平摊到其他提供者 不会引起剧烈变动。缺 省值对第一个参数hash, 如果要修改请配置: <dubbo:parameterkey=”hash.arguments” value” 0 , 1 ”/> 缺省用 160 份虚拟节点 。 如果要修改 请配置 <dubbo:parameterkey=”hash.nodes” value=” 320 ”>
7. 7. 7. 5 Dubbo 在安全机制方面是如何解决的?
Dubbo通过token令牌防止用户绕过注册中心直连。然后再注册中心上管 理授权,dubbo还提供服务黑白名单, 来控制服务所允许的调用方。
7. 7. 7. 6 dubbo链接注册中心和直连有什么区别?
在开发级测试环境下,经常需要绕过注册中心,只测试制定服务提供者, 这时候可能需要点对点直连。 点对点直连方式 :将以服务接口为单位,忽略注册中心出的提供者列表。 注册中心:动态的注册和发现服务,使服务的位置透明,并通过在消费方获取 服务提供方地址列表,实现软负载均衡和failover。注册中心返回服务提供者地 址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进 行调用,如果调用失败,再选另一台调用,注册中心负责服务地址的注册于查 找,相当于目录服务, 服务提供者和消费者只在启动时与注册中心进行交互, 注册中心不转发请求,服务消费者向注册中心获取服务提供者地址列表, 并根 据软负载算法直接调用提供者.注册中心,服务提供者,服务消费者三者之间均 为长连接。 监控中心除外,注册中心通过长连接感知服务提供者的存在,服务 提供者宕机,注册中心将立即推送事件通知消费者,注册中心和监控中心全部宕 机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
7. 7. 7. 7 dubbo服务集群的容错模式
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover重试。 可以自行扩展集群容错策略 1 .FailoverCluster(默认) 失败自动切换,当出现失败,重试其它服务器。(缺省)通常用于读操作,
但重试会带来更长延迟。可通过retries=” 2 “来设置重试次数(不含第一次)。 <dubbo:serviceretries=” 2 “cluster=“failover”/>或: <dubbo:referenceretries=” 2 “cluster=“failover”/> cluster=“failover"可以不用写,因为默认就是failover 2 .FailfastCluster 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操 作,比如新增记录。 dubbo:servicecluster=“failfast”/> 或:dubbo:referencecluster="failfast"/ cluster=“failfast"和 把 cluster=“failover”、retries=” 0 “是一样的效果,retries=” 0 “就是不重试 3 .失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。 dubbo:servicecluster="failsafe"/ 或:dubbo:referencecluster="failsafe"/ 4 .失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。 dubbo:servicecluster="failback"/ 或: dubbo:referencecluster="failback"/ 5 .并行调用多个服务器 只要有一个成功即返回, 通常用于实时性要求较 高的读操作,但需要浪费更多服务器资源,通过forks=“ 2 ”来设置最大 并行数。 6 .广播调用所有提供者 ,逐个调用,任意一台报错则报错( 2. 1. 0 开始支 持), 通常用于通知所有提供者更新缓存或日志等本地资源信息。
在项目开发中,我们项目框架已经由我们项目经理搭建好了,我们在使用
中只用在服务方和消费方配置好需要暴露的接口,在消费用通过
@Reference 注解进行引入服务。
7 8 Zookeeper…………………………………………………………………………………………………………….
ZooKeeper是一种为分布式应用所设计的高可用.高性能且一致的开源协调 服务,它提供了一项基本服务: 分布式锁服务 。由于ZooKeeper的开源特性, 后来我们的开发者在分布式锁的基础上,摸索了出了其他的使用方法: 配置维护. 组服务.分布式消息队列.分布式通知/协调 等。 在我们的项目中Zookeeper作为服务注册中心,他的主要任务是负责地址 的注册以及查找,相当于一个服务目录,服务的提供者与服务的消费者只在启动 时与注册中心进行交互,注册中心也不会转发请求,所以相对而言压力较小。 Zookeeper诞生的背景:
调用关系 1 说. 明服:务容器负责启动,加载,
运行服务 2 提. 供服者务。提供者在启动时,向注
册中心注册自己提供的服务。
册中心订^3 .阅自服己务所消需费的者服在务启。动时,向注
址列表给^4 .消费注者册,中如心果返有回变服更务,提注供册者中地心
将基于长连接推送变更数据给消费者。
列表中,^5 基. 于服软务负消载费均者衡,算从法提,供选者一地台址提
供者进行 6 .调用台,调如用果。调服用务失消败费,再者选和另提一供
者,在内存中累计调用次数和调用时间,
定心时。每分钟发送一次统计数据到监控中
其实除了Zookeeper实现了分布式锁以外还有Google的Chubby也是分 布式锁的实现者,Chubby是Googele的闭源程序,所以我们用不了,而 Zookeeper是雅虎模仿Chubby开发出来并捐献给Apache的,所以才可以使 用到这么优秀的开源程序去构建我们的分布式系统。
7 8 1 Zookeeper是如何实现配置维护.组服务.分布式消息队列等等服务的呢?…..
首先Zookeeper在实现这些服务之前,他设计了一种新的数据结构-Znode, 然后在这个数据结构的基础之上定义了一些对数据结构操作的方法,另外 Zookeeper还设计了一种通知机制-Watcher机制。通过新的数据结构-Znode
- 操作Znode的方法 +Watcher机制实现了上述我们所看到的服务。
7 8 2 简述一下你对Znode的理解………………………………………………………………………
首先跟你说一下Znode的结构跟我们日常中的Window环境中的文件目录 结构很像,下面放张截图
是不是很相似,Zookeeper中的每一个节点( )被称为Znode。 虽然他们很相似,但是他们也有 不同之处。 ( 1 )引用方式: Znode通过路径进行引用,就像Linux中的文件路径。并且路径都是绝 对路径,因此他们都必须用“/”来开头,除此以外他们都必须是唯一的,也就 是每一个路径都只有一种表示,并且这些路径不可以改变。在Zookeeper中, 这些路径是有Unicode字符串组成,加入一些限制,比如:字符串“/zookeeper” 就用以保存管理信息(关键配额信息等) ( 2 )Znode结构 Znode结构兼具了文件和目录两种特点,既可以保存数据.维护数据,又 可以向目录一样作为路径表示的一部分。Znode主要是由 3 个部分组成: 1 Stat:这个表示状态信息,用于描述这个Znode的版本.权限等信 息 2 Data:这个表示与当前Znode相关联的数据 3 Children:这个表示当前Znode下的子节点
( 3 )数据访问
ZooKeeper中的每个节点存储的数据要被原子性的操作。也就是说读操 作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每 一个节点都拥有自己的 ACL(访问控制列表) ,这个列表规定了用户的权限,即限 定了特定用户对目标节点可以执行的操作。 ( 4 )节点类型 ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型 在创建时即被确定,并且不能改变。
(^1) 临时节点:临时节点的生命周期依赖于创建它们的会话。一旦会 话(Session)结束,临时节点将被自动删除,当然也可以手动删除。虽然 每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端 还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。 2 永久节点:永久节点的生命周期不依赖于会话,并且只有在客户 端显示执行删除操作的时候,他们才能被删除。 ( 5 )顺序节点 当创建Znode的时候,用户可以请求在ZooKeeper的路径结尾添加一 个递增的计数。这个计数对于此节点的父节点来说是唯一的,它的格式为 ZooKeeper虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数 据汇存集储位,置相等反等的。是这,些它数用据来的管共理同调特度性数就据是,它比们如都分是布很式小应的用数中据的,配通置常文以件K信B息为.大状小态单信位息。. ZooKeeper的服务器和客户端都被设计为严格检查并限制每个Znode的数据大小至多 1 M,但常规使用中应该远小于此值。
“% 10 d”( 10 位数字,没有数值的数位用 0 补充,例如” 0000000001 “)。当计数 值大于 232 - 1 时,计数器将溢出。 ( 6 )观察 客户端可以在节点上设置watch,我们称之为监视器。当节点状态发生 改变时(Znode的增.删.改)将会触发watch所对应的操作。当watch被触发时, ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次, 这样可以减少网络流量
7 8 3 Zookeeper角色说明…………………………………………………………………………………..
领导者(leader),负责进行投票的发起和决议,更新系统状态 学习者(learner),包括跟随者(follower)和观察者(observer),follower 用于接受客户端请求并想客户端返回结果,在选主过程中参与投票 Observer可以接受客户端连接,将写请求转发给leader,但observer不参 加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读 取速度 客户端(client),请求发起方
7 8 4 角色调用关系说明……………………………………………………………………………………….
7 8 5 Zookeeper的核心是什么?………………………………………………………………………..
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。 实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模 式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入 了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同 步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统 状态。
7 8 6 Zookeeper中的每个Server有几种状态?…………………………………………………
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
7 8 7 Zookeeper的节点数据操作流程…………………………………………………………………
- 在Client向Follwer发出一个写的请求 2 .Follwer把请求发送给Leader 3 .Leader接收到以后开始发起投票并通知Follwer进行投票 4 .Follwer把投票结果发送给Leader 5 .Leader将结果汇总后如果需要写入,则开始写入同时把写入操作通知给 Leader,然后commit; 6 .Follwer把请求结果返回给Client
7 8 8 为什么zookeeper集群的数目,一般为奇数个?……………………………………….
1 .容错
由于在增删改操作中需要半数以上服务器通过,来分析以下情况。
2 台服务器 ,至少 2 台正常运行才行( 2 的半数为 1 ,半数以上最少为 2 ),
正常运行 1 台服务器都不允许挂掉
3 台服务器 ,至少 2 台正常运行才行( 3 的半数为 1. 5 ,半数以上最少为 2 ),
正常运行可以允许 1 台服务器挂掉
4 台服务器 ,至少 3 台正常运行才行( 4 的半数为 2 ,半数以上最少为 3 ),
正常运行可以允许 1 台服务器挂掉
5 台服务器 ,至少 3 台正常运行才行( 5 的半数为 2. 5 ,半数以上最少为 3 ),
正常运行可以允许 2 台服务器挂掉
6 台服务器 ,至少 3 台正常运行才行( 6 的半数为 3 ,半数以上最少为 4 ),
正常运行可以允许 2 台服务器挂掉
通过以上可以发现, 3 台服务器和 4 台服务器都最多允许 1 台服务器挂掉,
5 台服务器和 6 台服务器都最多允许 2 台服务器挂掉
但是明显 4 台服务器成本高于 3 台服务器成本, 6 台服务器成本高于 5 服务
器成本。这是由于半数以上投票通过决定的。
2 .防脑裂
一个zookeeper集群中,可以有多个follower.observer服务器,但是必 需只能有一个leader服务器。 如果leader服务器挂掉了,剩下的服务器集群会通过半数以上投票选出一 个新的leader服务器。
集群互不通讯情况:
一个集群 3 台服务器 ,全部运行正常,但是其中 1 台裂开了,和另外 2 台
无法通讯。 3 台机器里面 2 台正常运行过半票可以选出一个leader。 一个集群 4 台服务器 ,全部运行正常,但是其中 2 台裂开了,和另外 2 台 无法通讯。 4 台机器里面 2 台正常工作没有过半票以上达到 3 ,无法选出leader 正常运行。 一个集群 5 台服务器 ,全部运行正常,但是其中 2 台裂开了,和另外 3 台 无法通讯。 5 台机器里面 3 台正常运行过半票可以选出一个leader。 一个集群 6 台服务器 ,全部运行正常,但是其中 3 台裂开了,和另外 3 台 无法通讯。 6 台机器里面 3 台正常工作没有过半票以上达到 4 ,无法选出leader 正常运行。 通过以上分析可以看出,为什么zookeeper集群数量总是单出现,主要原 因还是在于第 2 点,防脑裂,对于第 1 点,无非是正本控制,但是不影响集群 正常运行。但是出现第 2 种裂的情况,zookeeper集群就无法正常运行了。
7 8 9 经典实例:Zookeeper分布式锁的应用场景………………………………………………
背景:
在分布式锁服务中,有一种最典型应用场景,就是 通过对集群进行Master 选举 , 来解决 分布式系统中的 单点故障 。什么是分布式系统中的单点故障:通常 分布式系统采用主从模式,就是一个主控机连接多个处理节点。主节点负责分发 任务,从节点负责处理任务,当我们的主节点发生故障时,那么整个系统就都瘫 痪了,那么我们把这种故障叫作单点故障。如下图 1. 1 和 1. 2 所示:
1. 1 主从模式分布式系统 1. 2 单点故障
传统解决方案
传统方式是采用一个 备用节点 ,这个备用节点 定期给 当前主节 点发 送 pi ng 包, 主节点收到ping包 以后向备用节 点发 送回复 Ack ,当备用节点收到回复的 时候就会认为当前主节点还活着,让他继续提供服务。如图 1. 3 所示
1. 3 传统解决方案
当主节点挂了,这时候备用节点收不到回复了,然后他就认为主节点挂了接替他
成为主节点如下图 1. 4 所示
1. 4 传统解决方案
但是这种方式就是有一个隐患,就是网络问题,来看一网络问题会造成
什么后果,如下图 1. 5 所示
1. 5 网络故障
传统解决方案总结:
也就是说我们的主节点的并没有挂,只是在回复的时候网络发生故障,这样
我们的备用节点同样收不到回复,就会认为主节点挂了,然后备用节点将他的
Master实例启动起来,这样我们的分布式系统当中就有了两个主节点也就是- 双Master,出现Master以后我们的从节点就会将它所做的事一部分汇报给了 主节点,一部分汇报给了从节点,这样服务就全乱了。 Zookeeper解决方案: Master启动: 在引入了Zookeeper以后我们启动了两个主节点,“主节点-A"和"主节点-B” 他们启动以后,都向ZooKeeper去注册一个节点。我们假设"主节点-A"所注册 地节点是"master- 00001 “,“主节点-B"所注册的节点是"master- 00002 “,注册 完以后进行选举, 编号最小的节点将在选举中获胜 获得 “锁”并且 成为主节点, 也就是我们的"主节点-A"将会获得“锁”成为主节点,然后"主节点-B"将被 阻塞 成为一个 备用节点 。那么,通过这种方式就完成了对两个Master进程的调度。 如图 2. 1 所示
2. 1 ZookeeperMaster选举 (1) Master故障 如果 “主节点-A"挂了 ,这时候 他 所 注册的节点 将被 自动删除 , ZooKeeper会 自动感知节点的变化,然后 再次发出选举 ,这时候 “主节点-B “将 在选举中 获胜 ,替代"主节点-A” 成为主节点。如图 2. 2 所示
2. 2 Master故障 (2) Master恢复 如果 “主节点 - A ” 恢复了 ,他会 再次 向ZooKeeper 注册 一个 节点 ,这 时候他注册的节点将会是” master- 00003 “ , ZooKeeper会 感知节点的变化 再 次发动选举 ,由于 编号最小的节点将在选举中获胜 获得 “锁”并且 成为主节点, 这时候” 主节点-B “在选举中 会再次获胜 继续担任"主节点”, “主节点-A"会 担任 备 用节点 。如图 2. 3 所示:
2. 3 Master恢复
7 9 POI………………………………………………………………………………………………………………………..
7 9 1 POI的介绍…………………………………………………………………………………………………..
POI是用JAVA语言编写的免费的开源的跨平台API,可以对微软的word、
Excel、PPT进行操作。
7. 9. 2 POI项目中的使用,主要用在哪些地方?<项目中主 要使用在出货表打印,合同上传,销售报表等>
7 9 3 Excel报表导出流程:………………………………………………………………………………….
1 .创建工作簿(HSSFWorkbook)<工作簿这块我们需要注意一个问题,普通处理 Excel我们分为Excel 03 (HSSF)版和 07 (XSSF)版本以上,对于大数据处理我们使 用SXSSF,比如一个Excel有 40 多列>
2 .创建工作表(createSheet()) 3 .设置一些参数(sheet.setColumnWidth( 0 , 2 * 256 );)设置列宽,我们一般都会
- 256 ,因为在HSSFWorkbook的底层源码里边对列设置的方法里边,做的处 理是二百五十六分之一( 1 / 256 ),所以我们要设置列宽的时候,乘以 256 就是我 们想要的值。 4 .根据项目需求我们可能要需要设置标题,设置行高(setHeightInPoints()),设 置单元格对象,设置对象里边的内容。还有就是合并单元格,横向合并单元格 (sheet.addMergedRegion)等。 5 .把在后台查询的数据填充到对应Excel表格里边。 6 .实现文件下载,导出到制定路径。 7 ,根据客户提供的模板和要求做样式的调整,比如:大标题,小标题,字体, 居中设置等。 因为不同企业对导出的表格要求不一直,为了便于快速开发,我们在公司一般采 取的是模板打印。具体的实现思路是:在后台查询要导入的数据,制作模版文件 (模版文件的路径)导入(加载)模版文件,从而得到一个工作簿 读取工作表 读取行 读取单元格 读取单元格样式 设置单元格内容 其他单元格就可以使用 读到的样式了 。 针对于Excel的百万级别报表数据导出,我们使用POI提供的SXSSFWork处理 大数据量。但是他不支持模板打印。
7 9 4 百万级数据导出…………………………………………………………………………………………..
针对于大宗贸易我们,涉及的数据量比较大,我们这里采用POI给我们提供
的支持 07 版本的SXSSFWork对象实现导入导出,但是这个也有一个不好的地
方就是不能使用模板打印,不能使用太多的样式。需要在后台根据客户需求进行
设置。为了比较POI里边的XSSFwork和SXSSFwork我们这里可以借助工具 Jvisualvm进行测评在实现大数据量导出的时候,进行系统监控,比如:CPU利 用率,gc监控,堆利用率,内存利用率,类监控,线程监控。 但是在使用SXSSFWork进行导入的时候,因为数据量比较大,经常会造成内存 溢出,我们这里使用 POI 基于事件模式解析案例提供的 Excel 文件 。其实POI 里边提供了两种模式,用户模式(系统默认)和事件模式。 这两个的区别是:用 户模式一次性加载所有内容到内存,然后着个解析。事件模式是一边加载一边解 析。 使用这个进行导入时,我们需要定义两个解析器,一个是Excel解析器,这 个公司直接封装好的,拿过来直接用。还有一个是sheet的解析器。Sheet解析 器是基于SAX解析(SAX提供了一种从XML文档中读取数据的机制。它逐行扫 描文档,一边扫描一边解析。由于应用程序 只是在读取数据时检查数据,因此 不需要将数据存储在内存中,这对于大型文档的解析是个巨大优势 )进行实现 的。我们需要在这个解析器里边定义开始行和结束行,创建解析行的方法,在方 法里边通过switch{case}语句根据要导入的信息确定值,我们这里用的每一列 的表示符(比如:A,B,C等)进行数据处理。
原理分析:主要原理是借助临时存储空间生成 excel 在实例化 SXSSFWork 这 个对象时,可以指定在内存中所产生的 POI 导出相关对象的数量(默认 100 ), 一旦 内存中的对象的个数达到这个指定值时,就将内存中的这些对象的内容写 入到磁盘中(XML 的文件格式),就可以 将这些对象从内存中销毁,以后只
要达到这个值,就会以类似的处理方式处理,直至 Excel 导出完成。
7 10 WebService技术使用…………………………………………………………………………………………
7 10 1 技术描述…………………………………………………………………………………………………..
webService是这项技术指的是在自己网站调用其他网站或者程序。 webService指的是一套规范或者服务,主要是为了便于我们跨应用,跨网站进 行调用。它约定了不同程序之间的规范,基于xml形式进行数据通信。我们在 项目开发中使用的是基于webService的一套框架CXF,Cxf 是基于 SOA 总 线结构,依靠 spring 完成模块的集成,实现 SOA 方式。 灵活的部署: 可以 运行在 Tomcat,Jboss,Jetty(内置),weblogic 上面。 在工作中,经常会遇到不同公司系统之间的远程服务调用。远程调用技术非常 多,如rmi、netty、mina、hessian、dubbo、Motan、springcloud、webservice 等等。但是我个人还是比较喜欢webService的,主要原因有 4 点: 1 .webservice技术是建立在http+xml基础之上的,非常的轻量级。 2 .webservice技术可通过wsdl来定义调用关系,双方系统可根据wsdl快 速的进行开发对接。 3 .webservice是一种标准,有各种语言对它的实现,支持异构系统之间的对 接。 4 .必要情况下,还可以使用httpclient作为客户端进行调用,以降低依赖。
7 10 2 面试问题汇总:………………………………………………………………………………………..
7 10 3 webService的三大规范是什么?………………………………………………………………
分别指的是JAX-WS,JAX-RS,JAX-WS&SAAJ(废弃)
JAX-RS 是一个 Java 编程语言接口,被设计用来简化使用 REST 架构的应用 程序的开发。借助Jax-RS规范提供一些注解和配置方式:快速的搭建一个符合 Restful风格的应用。借助Jax-RS规范提供的工具类,方便的调用符合Jax-RS 的应用。
7 10 4 除了webService,还有什么技术可以实现内部程序调用其他网站服务?…
目前还有Httpclient、Dubbo<主要应用于内部系统访问>、RMI、Scoket。 HttpClient HttpClient 是 ApacheJakartaCommon 下的子项目,用来提供高效的、 最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。主要在调用一些对外的API接口进行使用。 WebService WebService提供的服务是基于web容器的,底层使用http协议,类似一 个远程的服务提供者,比如天气预报服务,对各地客户端提供天气预报,是 一种请求应答的机制,是跨系统跨平台的。就是通过一个servlet,提供服务出 去。 首先客户端从服务器的到WebService的WSDL,同时在客户端声称一个代 理类(ProxyClass) 这个代理类负责与WebService服务器进行Request 和 Response 当一个数据(XML格式的)被封装成SOAP格式的数据流发送到服
务器端的时候,就会生成一个进程对象并且把接收到这个Request的SOAP包 进行解析,然后对事物进行处理,处理结束以后再对这个计算结果进行SOAP 包装,然后把这个包作为一个Response发送给客户端的代理类(ProxyClass), 同样地,这个代理类也对这个SOAP包进行解析处理,继而进行后续操作。这 就是WebService的一个运行过程。 WebService大体上分为 5 个层次: 1 .Http传输信道 2 .XML的数据格式 3 .SOAP封装格式 4 .WSDL的描述方式 从下往上看这个说明书。 5 .UDDI UDDI是一种目录服务,企业可以使用它对Webservices进行注 册和搜索
7 10 5 如何以JAVA的形式启动当前web应用……………………………………………………
1 .创建工厂
2 .制定接口
3 .制定交互对象
4 .配置日志输出
5 .启动服务
7 10 6 远程通信的几种选择(RPC,Webservice,RMI,JMS的区别)……………
RMI(RemoteMethodInvocation)
RMI采用stubs 和 skeletons 来进行远程对象(remoteobject)的通讯。 stub 充当远程对象的客户端代理,有着和远程对象相同的远程接口,远程对象 的调用实际是通过调用该对象的客户端代理对象stub来完成的,通过该机制 RMI就好比它是本地工作,采用tcp/ip协议,客户端直接调用服务端上的一些 方法。优点是强类型,编译期可检查错误,缺点是只能基于JAVA语言,客户机 与服务器紧耦合。 JMS(JavaMessagingService) JMS是Java的消息服务,JMS的客户端之间可以通过JMS服务进行异步的 消息传输。JMS支持两种消息模型:Point-to-Poin(t P 2 P)和Publish/Subscribe (Pub/Sub),即点对点和发布订阅模型。
7 10 7 在项目中常用的注解有哪些?…………………………………………………………………..
@path 注解的值是一个相对的URI路径,这个路径指定了该Java类的位置。 请求方式:@get|@post|@delete|@put @Consumes 注解是用来指定资源能够接受的客户发送的 MIME 媒体类型。 当前请求链接所接受数据的格式 xml/json @Produces注解用来指定资源能够生成并发送给客户端的 MIME 媒体类型, 当前请求链接响应数据的格式 xml/json @xmlRootElement(name=””) 生成xml根节点的名称。
7 10 8 webService的三要素是什么?………………………………………………………………….
SOAP,WSDL,UDDI SOAP: 基于 HTTP 协议,采用 XML 格式,用来传递信息的格式。 WSDL: 用来描述如何访问具体的服务。
UDDI: 用户自己可以按 UDDI标准搭建 UDDI 服务器,用来管理,分发,查
询 WebService。其他用户可以 自己注册发布 WebService 调用。
7 10 9 项目中是如何使用CXF进行外部接口调用的?…………………………………………
1 .创建工程,导入xcf的坐标(百度直接搜索spring+cxf整合的maven的pom 文件就可以找到) 2 .编写配置文件web.xml,在文件里边添加cxf的核心控制器。目的是通过cxf 核心控制器帮我们进行转发,我们在这里一般都会进行指定拦截,比如:/ws/* 3 .编写服务发布类(JAXRSServerFactoryBean) 4 .接口调用(WebClient.create()) 我们在公司写接口是在pom引入xcf坐标,配置好引入路径,直接调取接口就 好了。我们一般按照海关提供的接口文档,根据里边的开发规范进行开发就可以 了。对应的文档里边会给我们提供: 1 .请求的路径和方式。 2 .请求的参数。同时 给我提供了Demo供我们参考。以报运单为例,调用报运单业务执行步骤是: 1. 根据报运单id查询报运单; 2 .根据报运单id查询报运商品; 3 .转为定义好的 Result传递对象的类型; 4 .调用webService进行报运; 5 .查询报运结果; 6 .根 据报运结果更新报运单和报运货物;
7 11 echarts在项目中的应用?…………………………………………………………………………………..
Echarts是百度的前端团队开发的一款开源的基于js报表的组件,兼容IE 8 以上 的版本,Chrome(谷歌),Firefox(火狐),Safari(苹果手机)。我们可以根据我们在 项目中需要展示的图形样式直接在百度API里边拷贝对应的option。我们在项 目中主要应用于生产厂家销售统计,商品销售统计,在线人数统计。
7 12 Quartz的应用……………………………………………………………………………………………………..
1 .项目中的定时任务我们一般使用Quartz或者SpringTask进行实现。我们 项目中使用的是Quartz,是一个完全由 Java 编写的开源任务调度的框架,通 过触发器设置作业定时运行规则,控制 作业的运行时间。其中 quartz 集群通 过故障切换和负载平衡的功能,能给调度器带来高可用性和伸 缩性。主要用来 执行定时任务,如:定时发送信息、定时生成报表等等。 2 .Quartz在项目中的使用。 搭建环境(引入Quartz坐标) 配置一个类,配置定时任务执行的方法 将此类交给spring进行管理 配置Quartz和spring整合 我们在开发中经常为如何准确的定位好时间,我们这里可以使用 cron.qqe 2 .com 在线cron表达式生成。Cron他是按照<秒,分钟,小时,日, 月,周,年>进行算的。
Quartz和SpringTask的区别是什么?
实现,Task注解实现方式,比较简单。Quartz需要手动配置Jobs。 任务执行,Task默认单线程串行执行任务,多任务时若某个任务执行时间过长, 后续任务会无法及时执行。Quartz采用多线程,无这个问题。 调度,Task采用顺序执行,若当前调度占用时间过长,下一个调度无法及时执 行; Quartz采用异步,下一个调度时间到达时,会另一个线程执行调度,不会发生 阻塞问题,但调度过多时可能导致数据处理异常 部署,Quartz可以采用集群方式,分布式部署到多台机器,分配执行定时任务。
7 13 PDF导出……………………………………………………………………………………………………………..
7. 13. 1 常用的pdf技术有哪些? 1 .iTextPDF:iText 是著名的开放项目,是用于生成 PDF 文档的一个 java 类库。通过 iText 不仅可以生成 PDF 或 rtf 的文档,而且可以将 XML、Html 文件转化为 PDF 文件。 Openoffice:openoffice 是开源软件且能在 windows 和 linux 平台下运 行,可以灵活的将 word或者 Excel 转化为 PDF 文档。 JasperReport:是一个强大、灵活的报表生成工具,能够展示丰富的页面内容, 并将之转换成 PDF 。 我们开发中一般选用的是JasperReport技术,这个技术完全由Java写成, 同时还有对应的工具JaspersoftStudio ,在线编辑很方便。支持多种表格的输 出,同时支持多种数据源,通过 JASPER 文件及数据源,JASPER 就能生成最 终用户想要的文档格式。
7. 13. 2 JasperReport 的生命周期是? 设计(Design)阶段、执行(Execution)阶段以及输出(Export)阶段。 设计阶段就是创建模板,模板创建完成我们保存为JRXML 文件(JR 代表 JasperReports),其实就是一个 XML 文件。 执行阶段编译成可执行的二进制文件(即.Jasper文件)结合数据进行执行,进行 数据填充。 输出阶段(Export):数据填充结束,可以指定输出为多种形式的报表。
7. 13. 3 JasperReport 的执行流程是什么? JRXML:报表填充模板,本质是一个 XML. Jasper:由 JRXML 模板编译生成的二进制文件,用于代码填充数据。 Jrprint:当用数据填充完 Jasper后生成的文件,用于输出报表。 Exporter:决定要输出的报表为何种格式,报表输出的管理类。 Jasperreport 可以输出多种格式的报表文件,常见的有 Html,PDF,xls等 7. 13. 4 在项目中PDF导出的使用? 我们在项目中先 1 .导入坐标, 2 .引入模板,把编译好的模板引入到当前工程中。 3 .配置控制器方法( 1 .加载模板文件, 2 .构建文件输入流; 3 .创建 JasperPrint 对 象; 4 .写入 pdf 文档输出 )。导入导出的流程一般都是固定的格式,我自己写 了个文档,当我使用的时候,我会拿出来按照上边的步骤进行操作完成。
1 .引入 jasper文件 2 .构造数据
a.报运单数据 b.报运货物列表(通过 list 集合创建 javaBean 的数据源对象)
7 14 RabbitMQ…………………………………………………………………………………………………………..
7 14 1 什么是RabbitMQ?…………………………………………………………………………………
RabbitMQ是一款开源的,Erlang编写的,基于AMQP协议的,消息中间 件。
7 14 2 为什么要使用RabbitMQ?Rabbit有什么优点?…………………………………….
解耦、异步、削峰。
7 14 3 RabbitMQ有什么缺点?…………………………………………………………………………..
降低了系统的稳定性:本来系统运行好好的,现在你非要加入个消息队列进
去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性会降低。
增加了系统的复杂性:加入了消息队列,要多考虑很多方面的问题,比如:
一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此,
需要考虑的东西更多,复杂性增大。
7 14 4 RabbitMQ的工作模式?…………………………………………………………………………..
7 种 , 1 .简单模式 2 .工作者模式 3 .广播模式 4 .路由模式 5 .通配符模式
6 .RPC 7 .消息确认模式
简单模式
一个生产者,一个消费者。
work模式(常用)
一个生产者,多个消费者,每个消费者获取到的消息唯一。
订阅模式
一个生产者发送的消息会被多个消费者获取。
路由模式
发送消息到交换机并且要指定路由key ,消费者将队列绑定到交换机时需 要指定路由key。 topic模式(常用) 将路由键和某模式进行匹配,此时队列需要绑定在一个模式上,“#”匹配 一个词或多个词,“*”只匹配一个词。
7 14 5 如何保证RabbitMQ高可用?………………………………………………………………….
搭建RabbitMQ集群。一般小型,中型项目搭建 3 台够用了。数据量在 500 万内。
7 14 6 如何保证RabbitMQ消息不被重复消费?………………………………………………..
先说为什么会重复消费:正常情况下,消费者在消费消息的时候,消费完毕
后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将
该消息从消息队列中删除。
但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列
不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
针对以上问题,一个解决思路是:保证消息的唯一性,就算是多次传输,不
要让消息的多次消费带来影响,保证消息等幂性。
比如:在写入消息队列的数据做唯一标示,消费消息时,根据唯一标识判断
是否消费过。
7 14 7 如何保证RabbitMQ消息可靠传输?……………………………………………………….
消息不可靠的情况可能是消息丢失,劫持等原因。丢失又分为:生产者丢失
消息、消息列表丢失消息、消费者丢失消息。
生产者丢失消息
从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm 模式来确保生产者不丢消息。 transaction模式:发送消息前,开启事务(channel.txSelect()),然后发送 消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()), 如果发送成功则提交事务(channel.txCommit())。然而,这种方式有个缺点, 吞吐量下降。 confirm模式:一旦channel进入confirm模式,所有在该信道上发布的消 息都将会被指派一个唯一的ID(从 1 开始),一旦消息被投递到所有匹配的队 列之后。RabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就 使得生产者知道消息已经正确到达目的队列了.如果rabbitMQ没能处理该消 息,则会发送一个Nack消息给你,你可以进行重试操作。 消息队列丢数据 消息持久化。处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。 这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后, 再给生产者发送一个Ack信号。这样,如果消息持久化磁盘之前,rabbitMQ阵
亡了,那么生产者收不到Ack信号,生产者会自动重发。那么如何持久化呢? 这里顺便说一下吧,其实也很容易,就下面两步:
- 将queue的持久化标识durable设置为true,则代表是一个持久的队列。
- 发送消息的时候将deliveryMode= 2 。 这样设置以后,即使rabbitMQ挂了,重启后也能恢复数据。 消费者丢失消息 消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即 可!消费者在收到消息之后,处理消息之前,会自动回复RabbitMQ已收到消 息。如果这时处理消息失败,就会丢失该消息。 解决方案:处理消息成功后,手动回复确认消息。
7 14 8 如何保证RabbitMQ消息的顺序性?……………………………………………………….
单线程消费保证消息的顺序性。对消息进行编号,消费者处理消息是根据编
号处理消息。
7. 14. 9 如何确保消息正确地发送至RabbitMQ?如何确保消息接收 方消费了消息? 发送方确认模式 将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消 息都会被指派一个唯一的ID。一旦消息被投递到目的队列后,或者消息被写入 磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。 如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(not acknowledged,未确认)消息。发送方确认模式是异步的,生产者应用程序在
等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者
应用程序的回调方法就会被触发来处理确认消息。
接收方确认机制
消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同
操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。 这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是 否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer 足够长的时间来处理消息。保证数据的最终一致性。 下面罗列几种特殊情况 如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ会 认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消息重 复消费的隐患,需要去重)。 如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认 为该消费者繁忙,将不会给该消费者分发更多的消息。
7 14 10 RabbitMQ消息堆积处理………………………………………………………………………..
1. 增加消费者的处理能力(例如优化代码),或减少发布频率。
2. 考虑使用队列最大长度限制。
3. 给消息设置年龄,超时就丢弃。
- 默认情况下,rabbitmq消费者为单线程串行消费,设置并发消费两个关 键属性concurrentConsumers和prefetchCountoncurrentConsumers设置 的是对每个listener在初始化的时候设置的并发消费者的个数,prefetchCount
是每次一次性从broker里面取的待消费的消息的个数。 5. 建立新的queue,消费者同时订阅新旧queue,采用订阅模式。 6. 生产者端缓存数据,在mq被消费完后再发送到mq,打破发送循环条 件,设置合适的qos值,当qos值被用光,而新的ack没有被mq接收时,就 可以跳出发送循环,去接收新的消息;消费者主动block接收进程,消费者感受 到接收消息过快时主动block,利用block和unblock方法调节接收速率,当 接收线程被block时,跳出发送循环。
7 14 11 RabbitMQ消息丢失解决方案…………………………………………………………………
消息持久化
Exchange 设置持久化:durable:true。
ueue设置持久化;Message持久化发送。
ACK确认机制
消息发送确认。
息接收手动确认ACK。
7 14 12 RabbitMQ宕机了怎么处理…………………………………………………………………….
RabbitMQ提供了持久化的机制,将内存中的消息持久化到硬盘上,即使重 启RabbitMQ,消息也不会丢失。 持久化队列和非持久化队列的区别是,持久化队列会被保存在磁盘中,固定 并持久的存储,当Rabbit服务重启后,该队列会保持原来的状态在RabbitMQ 中被管理,而非持久化队列不会被保存在磁盘中,Rabbit服务重启后队列就会
消失。
非持久化比持久化的优势就是,由于非持久化不需要保存在磁盘中,所以使
用速度就比持久化队列快。即是非持久化的性能要高于持久化。
而持久化的优点就是会一直存在,不会随服务的重启或服务器的宕机而消
失。
7 14 13 RabbitMQ的集群…………………………………………………………………………………..
Rabbitmq有 3 种模式,但集群模式有 2 中,详情如下: 单一模式 即单机情况不做集群,就单独运行一个rabbitmq而已。 普通模式 默认模式,以两个节点(rabbit 01 、rabbit 02 )为例来进行说明。对于Queue 来说,消息实体只存在于其中一个节点rabbit 01 (或者rabbit 02 ),rabbit 01 和rabbit 02 两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit 01 节点的Queue后,consumer从节点消费时,RabbitMQ会临时在rabbit 01 、 rabbit 02 间进行消息传输,把A中的消息实体取出并经过B发送给consumer。 所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列, 要在多个节点建立物理Queue。否则无论consumer连rabbit 01 或rabbit 02 , 出口总在rabbit 01 ,会产生瓶颈。当rabbit 01 节点故障后,rabbit 02 节点无法 取到rabbit 01 节点中还未消费的消息实体。如果做了消息持久化,那么得等 rabbit 01 节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢 失的现象。
镜像模式
把需要的队列做成镜像队列,存在与多个节点属于RabbitMQ的HA案。 该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会 主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作 用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进 入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求 较高的场合中适用。
7 14 14 如何解决分布式事务问题?……………………………………………………………………..
1. 2 PC:两阶段提交
执行阶段:
当创建订单时,向所有微服务发送消息,可以开始执行了,执行成功后,不直接
提交,而是返回一个消息告诉我,执行成功还是执行失败。
第二阶段:
如果所有人都执行成功,再发一个消息,你们可以提交了;
如果第一阶段有人执行失败,你就告诉所有人都回滚。
缺点:当锁定的表很多时,性能差。
3 .TCC:补偿性事务(一般采用)try-confirm-concel 每个服务执行完后都提交,集中返回给自己,如果都执行成功了那就不管 如果提交失败,就采用失败服务的补偿方法去补偿,但若补偿方法也失败,那你还 需要进行重试写重试方法或者人工介入。 优缺:解决了性能问题,但是业务复杂,写一个事务还需要写补偿方法。
异步确保:利用mq实现分布式事务。
7 14 15 常见的消息中间………………………………………………………………………………………
RocketMQ 阿里系下开源的一款分布式、队列模型的消息中间件,原名Metaq, 3. 0 版 本名称改为RocketMQ,是阿里参照kafka设计思想使用java实现的一套mq。 同时将阿里系内部多款mq产品(Notify、metaq)进行整合,只维护核心功 能,去除了所有其他运行时依赖,保证核心功能最简化,在此基础上配合阿里上 述其他开源产品实现不同场景下mq的架构,目前主要多用于订单交易系统。 RabbitMQ 使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP, XMPP,SMTP,STOMP,也正是如此,使的它变的非常重量级,更适合于企业级 的开发。同时实现了Broker架构,核心思想是生产者不会将消息直接发送给队 列,消息在发送给客户端时先在中心队列排队。对路由(Routing),负载均衡(Load balance)、数据持久化都有很好的支持。多用于进行企业级的ESB整合。 ActiveMQ Apache下的一个子项目。使用Java完全支持JMS 1. 1 和J 2 EE 1. 4 规范的 JMSProvider实现,少量代码就可以高效地实现高级应用场景。可插拔的传输 协议支持,比如:in-VM,TCP,SSL,NIO,UDP,multicast,JGroupsandJXTA transports。RabbitMQ、ZeroMQ、ActiveMQ均支持常用的多种语言客户端 C++、Java、.Net,、Python、 Php、 Ruby等。 Redis
使用C语言开发的一个Key-Value的NoSQL数据库,开发维护很活跃,虽 然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可 以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队 操作,各执行 100 万次,每 10 万次记录一次执行时间。测试数据分为 128 Bytes、 512 Bytes、 1 K和 10 K四个不同大小的数据。实验表明:入队时,当数据比较小 时Redis的性能要高于RabbitMQ,而如果数据大小超过了 10 K,Redis则慢的 无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ 的出队性能则远低于Redis。 Kafka Apache 下的一个子项目,使用 scala实现的一个高性能分布式 Publish/Subscribe消息队列系统。
7 15 面试问题汇总:…………………………………………………………………………………………………..
7 15 1 这个系统UI使用什么框架?都用到jqueryeasyui的哪些组件?……………
系统UI使用JqueryeasyUI,及jquery库。系统框架布局使用layout, 系统标签窗口采用tabs,数据列表采用datagrid,下拉列表combobox,下拉 数据表格combogrid弹出窗口 window消息提示:messager树控件 tree 等。 7. 15. 2 本系统ajax+json具体是怎么做的?action的方法返回的 json是如何实现的? ajax+json:页面采用ajax提交,服务端返回是json,注意:页面提交的是 key/value串。 页面提交统一采用ajaxForm提交方式,引用了一个叫form.js的脚本,其
中使用了jquery提供form组件$("#form 1 “).serialize() ,再加上二次封装, 起到了简化开发的作用。
7 15 3 系统哪些地方使用到了json?………………………………………………………………….
数据列表查询返回json,在页面中使用jqerueasyui的datagrid进行解析。 所有提交类的action方法统一返回json 异常处理器会将异常信息转为json 系统菜单使用json数据表示。 使用json目的:使用json方便客户端页面解析数据。
7 15 4 你是如何将对象转成JSON或是将JSON转成对象?……………………………….
我们采用的解析JSON的工具是现在广泛采用的流行json工具包—-阿里巴 巴的fastJSON. 它提供了toJsonString方法将对象或集合转换为json字符 串 ,parse方法用于将json字符串转换为对象(MAP). parseArray方法用于将json字符串转换为List 集合
7 15 5 这个系统异常处理是怎么做的?……………………………………………………………….
分两个方面:
1 、系统异常类型
自定义了一个系统异常类,继承RuntimeException,该异常类需要编写一个 string类型的参数的的构造方法,构造方法中调用父类的构造方法。该参数为异 常的具体信息。
2 、系统异常的捕获和解析 dao层出现错误抛给biz、biz出现异常抛给action、action捕获异常进行输出。
7 15 6 你如何理解前端验证和后端验证,是如何实现的?…………………………………..
前端验证是在前端所进行的数据校验,主要用于非空验证和常用的格式验
证。我们采用的是easyUI提供的校验控件(validatebox)它对常用的校验规则进 行了封装。 后端验证是在业务逻辑层编写的用于校验数据的逻辑。通常用于重复性验 证、关联数据验证等。 7. 15. 7 如果我要实现某个数据非空验证,是不是写了前端验证就不 用写后端验证了? 对于一些特别重要的数据,最好是前端后端都验证,这样可以“双保险”, 大部分的非法请求通过前端拦截,可以避免后端承载过多的压力。但是前端验证 是“不把握”的,有可能被用户的浏览器所屏蔽,所以对于重要的数据后端验证 也是有必要的。另外比如重复性验证和关联性验证前端也是无法实现的,只能要 给后端来做。 7. 15. 8 你在使用下拉列表数据时,如果下拉列表数据过多( 100 条 以上),你是如何让用户很快找到要选择的数据的呢? 有一种叫做自动补全的解决方案。类似与百度搜索那样的,当用户输入某个 字符后,下拉列表会自动根据输入的数据模糊搜索并展示搜索的结果。 我在ERP中采用的是easyUI的combobox和combogrid 组件,他们有一个属 性是mode 设置为remote,这样用户每次输入字符就会自动向后端action 发送叫q的参数。后端代码就可以根据这个参数值来进行模糊搜索。
7 15 9 本系统配置信息是如何规范的?……………………………………………………………….
本系统使用国际化配置文件方式,将系统中所有异常信息、提示信息全部在
国际化配置文件中进行配置。
Java中对国际化支持: Java国际化主要通过如下 3 个类完成 java.util.ResourceBundle:用于加载一个资源(配置文件) java.util.Locale:对应一个特定的国家/区域、语言环境。 java.text.MessageFormat:用于将消息格式化
7 15 10 系统中都包括哪些系统配置方式?………………………………………………………….
1 .将系统中具有相同类型的配置项统一在数据字典表进行配置。
2 .将系统的运行参数统一配置系统参数配置表中。
3 .对系统所有提示信息(成功、异常)统一配置在message.properties文件中。 4 .对数据的连接参数配置在db.properties中 5 .日志参数配置在log 4 j.properties
6. 系 统 公 开 访 问 地 址 ( 无 需 要 登 录 即 可 访 问 ) 配 置 在
anonymousActions.properties 7 .系统公共访问地址(需要登录但需要授权才可访问)配置在 commonActions.properties
7 15 11 你是如何和测试人员配合工作的?………………………………………………………….
每天定时登录项目管理平台(我们一般使用的禅道),查看有没有自己名下
bug,如果有根据测试人员描述的测试场景进行测试,如果存在bug会及时修 改,修改完成将bug提交。如果根据测试人员描述的测试场景进行测试,bug 不存在,和测试人员沟通一样。 如果遇到bug来回驳回,我去现场和测试人员进行沟通,针对测试场景看 看双方是否一致。
7 15 12 项目中如何进行事务管理的?…………………………………………………………………
这个项目的事务管理是通过spring的声明式事务进行管理的,具体做法是 使用spring提供的事务注解,为Service创建代理对象,由代理对象进行事务 控制。
7 15 13 这个项目开发过程中遇到了哪些问题?…………………………………………………..
遇到的问题很多,有技术方面的,也有非技术方面的:
1 、开发工程师的技术水平参差不齐,有些技术稍差的工程师经常不能按时
完成项目经理分配的任务,还需要其他人帮忙,导致项目进度缓慢。
2 、和测试人员沟通困难,有些时候测试人员会提交一些bug,但在我们开
发看来根本就不是bug 3 、人员不稳定,如果有人离职,新招进来的人不能立即上手,导致项目推 进缓慢
7 15 14 什么是SaaS项目?………………………………………………………………………………..
简单说是在线系统模式。就是通过网络链接进行服务访问。
7 15 15 SaaS项目的优势是什么?……………………………………………………………………….
相对于供应商的优势
1 ) 稳健的运营模式(由原来把主要精力找客户转变为研发服务,满足客
户需求。) 2 ) 降低维护成本(传统的项目是以产品开发为主,维护是一对多的模
式,经常需要运维人员来回奔波在不同客户之间。)
3 ) 转变销售模式
7 15 16 SaaS项目合适什么项目?……………………………………………………………………….
面向个人的 SaaS 产品:在线文档,账务管理,文件管理,日程计划、照片 管理、联系人管理,等等云类型的 服务 面向企业的 SaaS 产品:CRM(客户关系管理)、ERP(企业资源计划管理)、 线上视频或者与群组通 话会议、HRM(人力资源管理)、OA(办公系统)、外勤 管理、财务管理、审批管理等。
八.SpringBoot框架…………………………………………………………………………………………………………….
8 1 SpringBoot是什么?为什么我们选择使SpringBoot开发?(必会)………………………
SpringBoot 被称为搭建程序的脚手架。其最主要作用就是帮我们快速的
构建庞大的spring项目,并且尽可能的减少一切xml配置,做到开箱即用,迅 速上手,让我们关注与业务而非配置。 传统的Java语言开发一直被人认为是臃肿和麻烦的,主要原因是: 复杂的配置 和一个混乱的的依赖管理 。而SpringBoot 简化了基于Spring的应用开发,只 需要“run”就能创建一个独立的、生产级别的Spring应用。SpringBoot为 Spring平台及第三方库提供开箱即用的设置(提供默认设置,存放默认配置的 包就是启动器starter),这样我们就可以简单的开始。多数SpringBoot应用 只需要很少的Spring配置。
8 2 SpringBoot常用的starter有哪些(必会)………………………………………………………….
1 .spring-boot-starter-web(嵌入tomcat和web开发需要servlet与jsp支持) 2 .spring-boot-starter-data-jpa(数据库支持) 3 .spring-boot-starter-data-Redis(Redis数据库支持) 4 .spring-boot-starter-data-solr(solr搜索应用框架支持) 5 .mybatis-spring-boot-starter(第三方的mybatis集成starter)
8 3 SpringBoot自动配置的原理(高薪常问)…………………………………………………………….
1 .@EnableAutoConfiguration这个注释告诉SpringBoot“猜”你将如何 想配置Spring,基于你已经添加jar依赖项。如果spring-boot-starter-web已 经添加Tomcat和SpringMVC,这个注释自动将假设您正在开发一个web应用 程序并添加相应的spring设置。会自动去maven中读取每个starter中的 spring.factories文件 该文件里配置了所有需要被创建spring容器中的bean
2 .使用@SpringBootApplication注解 可以解决根类或者配置类(我自己 的说法,就是main所在类)头上注解过多的问题,一个@SpringBootApplic ation相当于@Configuration,@EnableAutoConfiguration和@Component Scan并具有他们的默认属性值。 Springboot自动装配注解流程如下:
8 4 SpringBoot如何添加【修改代码】自动重启功能(了解)……………………………………
添加开发者工具集=====spring-boot-devtools
8 5 什么是SpringData?(必会)…………………………………………………………………………….
SpringData是一个用于简化数据库访问,并支持云服务的开源框架。 主要目标是使得数据库的访问变得方便快捷,并支持map-reduce框 架和云计算机数据服务。它支持基于关系型数据库的数据服务,如OracleRAC 等。对于拥有海量数据的项目,可以用SpringData来简化项目的开发,就如 SpringFramework对JDBC,ORM的支持一样,SpringData会让数据访问变 得更加方便。
8 6 SpringBoot的核心配置文有哪几个?它们的区别是什么?(了解)…………………….
SpringBoot 的核心配置文件是 application 和 bootstrap 配置文件。 application配置文件 这个容易理解,主要用于 Springboot 项目的自动化配 置。 bootstrap配置文件 有以下几个应用场景。 使用 SpringCloudConfig 配置中心时SpringBoot,这时需要在 bootstrap 配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息; 一些固定的不能被覆盖的属性; 一些加密/解密的场景;
8 7 SpringBoot的配置文件有哪几种格式?它们有什么区别?(必会)………………………
.properties 和 .yml,它们的区别主要是书写格式不同。
1 ).properties
app.user.name=javastack
2 ).yml
app:
user:
name:javastack
另外,.yml 格式不支持 @PropertySource 注解导入配置。
8 8 运行SpringBoot有哪几种方式?(必会)…………………………………………………………..
1 )打包用命令或者放到容器中运行
2 )用 Maven/Gradle插件运行
3 )直接执行main方法运行
8 9 如何在SpringBoot启动的时候运行一些特定的代码?(了解)…………………………
可以实现接口 ApplicationRunner 或者 CommandLineRunner,这两个 接口实现方式一样,它们都只提供了一个run 方法。具体实现如下: 第一种方法实现ApplicationRunner接口,代码如下: pub@licOcvlaesrrsidMeyApplicationRunnerimplementsApplicationRunner{ publicvoidrun(ApplicationArgumentsargs)throwsException{ “); System.out.println(”##################ApplicationRunner############### } }
第二种方法实现CommandLineRunner接口,代码如下:
@Component pu@bliOcvcelarrsisdMeyCommandLineRunnerimplementsCommandLineRunner{ publicvoidrun(String…args)throwsException{ ******”); System.out.println(”*************CommandLineRunner } }
8 10 SpringBoot有哪几种读取配置的方式?(了解)………………………………………………
SpringBoot 获取文件总的来说有三种方式,分别是 @Value 注解 , @ConfigurationProperties注解 和 Environment接口 。这三种注解可以配 合着@PropertySource来使用,@PropertySource主要是用来指定具体的配 置文件。 @PropertySource解析 @Target(ElementType.TYPE)@Retention(RetentionPolicy.RUNTIME)@Documented@Repe atable(ProSpterirntygSnoaumrcee(s).cdleasfasu)pltu"b"l;ic@interfacePropertySource{ String[]value(); bStoroinlegaennicgondoirnegR(e)sdoeufarcueltN"o"t;Found()defaultfalse; } Class<?extendsPropertySourceFactory>factory()defaultPropertySourceFactory.class;
encoding(): 指定编码,因为properties文件的编码默认是ios 8859 - 1 , 读取出来是乱码。 factory(): 自定义解析文件类型,因为该注解默认只会加载properties文 件,如果想要指定yml等其他格式的文件需要自定义实现。
一、@Value注解读取文件…………………………………………………………………………………..
新建两个配置文件config.properties和configs.properties,分别写入如下内 容: zzhhbbiinn..ccoonnffiigg..wweebb–ccoonnffiiggss..nagame=e 2 = 2 Java旅途 zzhhbbiinn..ccoonnffiigg..wweebb–ccoonnffiiggss..nagame=e 1 = 8 Java旅途
新增一个类用来读取配置文件
@Configuration @GePtrPorpoepretrytSieosu{rce(value = {“classpath:config.properties”},encoding=“gbk”)public class @prVivaaltuee(S"t$ri{nzghbnianm.coen;fig.web-configs.name}”) @Value("${zhbin.config.web-configs.age}”) ppruivbalitceSSttrriinngggaegteC;onfig(){ } returnname+”—–"+age; } 如果想要读取yml文件,则我们需要重写DefaultPropertySourceFactory,让 其加载yml文件,然后在注解@PropertySource上自定factory。代码如下: publicclassYmlConfigFactoryextendsDefaultPropertySourceFactory{ @puObvliecrrPidroepertySourcecreatePropertySource(Stringname,EncodedResourceresource) throwsIOESxtrcienpgtisoonur{ceName=name!=null?name:resource.getResource().getFilename(); if(!resource.getResource().exists()){ }reetlusernifn(esowuPrcroepNearmtiee.sePnrdospWerittyhS(o”.uymrcle”()s|o|usrocuerNceaNmaem,nee.ewndPsrWopiethrt(i"e.ysa()m);l”)){ PrerotuprenrtnieeswpPrrooppeerrttieiessFProrompYearmtySlo=ulrocaed(sYomulr(creesNoaumrcee,);propertiesFromYaml); }else{ }returnsuper.createPropertySource(name,resource); }privatePropertiesloadYml(EncodedResourceresource)throwsIOException{ YamlPropertiesFactoryBeanfactory=newYamlPropertiesFactoryBean(); ffaaccttoorryy..saeftteRrePsroouprecretsie(rseSseotu()r;ce.getResource()); } returnfactory.getObject(); } YmlCon@figPFraocpteorrtyy.cSloaussr)ce(value= {“classpath:config.properties”},encoding=“gbk”,factory =
二、Environment读取文件…………………………………………………………………………………
配置文件我们继续用上面的两个,定义一个类去读取配置文件
@Configuration @PropertySource(value = {“classpath:config.properties”},encoding=“gbk”)public class
GetProperties{ @Autowired EpnuvbilriocnSmtreinngtgenevtEirnovnCmoennfitg;(){ SSttrriinnggnagamee==enevnirvoirnomnmenetn.gt.egtePtrPorpoepretyrt(y"z(“hzbhibn.icno.cnofnigfi.gw.ewbe-bc-ocnofnigfisg.asg.nea"m);e”); returnname+”—–"+age; } }
三、@ConfigurationProperties读取配置文件……………………………………………………
@ConfigurationProperties可以将配置文件直接映射成一个实体类,然后我们 可以直接操作实体类来获取配置文件相关数据。 新建一个yml文件,当然properties文件也没问题,如下: zhbinc:onfig: web-ncoanmfeig:sJ:ava旅途 age: 20 新建实体类用来映射该配置: @@CCoomnfpigounreantitonProperties(prefix=“zhbin.config”)@DatapublicclassStudentYml{
/p/riwvaetbeCWonefbigCso务nf必igs与w配e置bC文o件nfi相gs对=应n,ew写W为e驼b峰Co命n名fig方s(式); @Data publicstaticclassWebConfigs{ pprriivvaatteeSSttrriinnggnaagme;e; } } prefix=“zhbin.config"用来指定配置文件前缀 如果需要获取list集合,则做以下修改即可。 zhbin: config: web–connafmiges::Java旅途
age: 20
- agnea:m 2 e 0 : 2 Java旅途 2
@Component @ConfigurationProperties(prefix=“zhbin.config”)@DatapublicclassStudentYml{ privateListwebConfigs=newArrayList<>(); @Data publicstaticclassWebConfigs{ pprriivvaatteeSSttrriinnggnaagme;e; } } 添加日志依赖
假如maven依赖中添加了spring-boot-starter-logging:
级别控制
所有支持的日志记录系统都可以在Spring环境中设置记录级别(例如 在application.properties中) 格式为:’logging.level.*=LEVEL’ logging.level:日志级别控制前缀,*为包名或Logger名 LEVEL:选项TRACE,DEBUG,INFO,WARN,ERROR,FATAL,OFF 举例: logging.level.com.dudu=DEBUG:com.dudu 包下所有 class 以
DEBUG级别输出
logging.level.root=WARN:root日志以WARN级别输出 自定义日志配置 由于日志服务一般都在ApplicationContext创建前就初始化了,它并 不是必须通过Spring的配置文件控制。因此通过系统属性和传统的Spring Boot外部配置文件依然可以很好的支持日志控制和管理。 根据不同的日志系统,你可以按如下规则组织配置文件名,就能被正确 加载: Logback:logback-spring.xml,logback-spring.groovy,logback.xml, logback.groovy Log 4 j:log 4 j-spring.properties,log 4 j-spring.xml,log 4 j.properties, log 4 j.xml Log 4 j 2 :log 4 j 2 - spring.xml,log 4 j 2 .xml JDK(JavaUtilLogging):logging.properties SpringBoot官方推荐优先使用带有-spring的文件名作为你的日志配 置(如使用 logback-spring.xml,而不是 logback.xml),命名为 logback-spring.xml的日志配置文件,springboot可以为它添加一些spring boot特有的配置项(下面会提到)。
8 11 SpringBoot支持哪些日志框架?推荐和默认的日志框架是哪个?(必会)………..
SpringBoot在所有内部日志中使用CommonsLogging,但是默认配置 也提供了对常用日志的支持,如:JavaUtilLogging,Log 4 J,Log 4 J 2 和 Logback。每种Logger都可以通过配置使用控制台或者文件输出日志内容。 默认日志Logback SLF 4 J——SimpleLoggingFacadeForJava,它是一个针对于各类 Java日志框架的统一Facade抽象。Java日志框架众多——常用的有 java.util.logging,log 4 j,logback,commons-logging,Spring框架使用的是 JakartaCommonsLoggingAPI(JCL)。而SLF 4 J定义了统一的日志抽象接口, 而真正的日志实现则是在运行时决定的——它提供了各类日志框架的binding。 Logback是log 4 j框架的作者开发的新一代日志框架,它效率更高、能 够适应诸多的运行环境,同时天然支持SLF 4 J。 默认情况下,SpringBoot会用Logback来记录日志,并用INFO级别 输出到控制台。在运行应用程序和其他例子时,你应该已经看到很多INFO级别 的日志了。
8 12 SpringBoot实现热部署有哪几种方式?(必会)………………………………………………
1 、模板热部署……………………………………………………………………………………………………..
在SpringBoot中,模板引擎的页面默认是开启缓存的,如果修改了页 面的内容,则刷新页面是得不到修改后的页面的,因此我们可以在 application.properties中关闭模版引擎的缓存,如下:
Thymeleaf的配置: spring.thymeleaf.cache=false FreeMarker的配置: spring.freemarker.cache=false Groovy的配置: spring.groovy.template.cache=false Velocity的配置: spring.velocity.cache=false
2 、使用调试模式Debug实现热部署…………………………………………………………………..
此种方式为最简单最快速的一种热部署方式,运行系统时使用Debug 模式,无需装任何插件即可,但是无发对配置文件,方法名称改变,增加类及方 法进行热部署,使用范围有限。
3 、spring-boot-devtools…………………………………………………………………………………..
在SpringBoot 项目中添加 spring-boot-devtools依赖即可实现页面 和代码的热部署。如下: «garrtoiufapcItdId»osrpgr.sinpgri-nbgofroatm-deewvtoorokl.sb<o/oatr<ti/fgarcotIudp>Id> 此种方式的特点是作用范围广,系统的任何变动包括配置文件修改、方 法名称变化都能覆盖,但是后遗症也非常明显,它是采用文件变化后重启的策略 来实现了,主要是节省了我们手动点击重启的时间,提高了实效性,在体验上回 稍差。 spring-boot-devtools 默认关闭了模版缓存,如果使用这种方式不用
单独配置关闭模版缓存。
4 、SpringLoaded……………………………………………………………………………………………….
此种方式与Debug模式类似,适用范围有限,但是不依赖于Debug模 式启动,通过SpringLoaded库文件启动,即可在正常模式下进行实时热部署。 此种需要在 runconfrgration 中进行配置。
5 、JRebel…………………………………………………………………………………………………………….
Jrebel是Java开发最好的热部署工具,对SpringBoot 提供了极佳的 支持,JRebel为收费软件,试用期 14 天。可直接通过插件安装。
8 13 你如何理解SpringBoot配置加载顺序?(了解)…………………………………………….
在 SpringBoot 里面,可以使用以下几种方式来加载配置。 1 )properties文件; 2 )YAML文件; 3 )系统环境变量; 4 )命令行参数; 等等…… 我们可以在 SpringBeans 里面直接使用这些配置文件中加载的值,如: 1 、使用 @Value 注解直接注入对应的值,这能获取到 Spring 中 Environment 的值; 2 、使用 @ConfigurationProperties 注解把对应的值绑定到一个对象; 3 、直接获取注入 Environment 进行获取;
8 14 SpringBoot如何定义多套不同环境配置?(高薪常问)……………………………………
一般情况下,多套不同环境(development、test、production)配置,我们基于 SpringBoot的Profiles来实现。 profile配置方式有两种: ·多profile文件方式:提供多个配置文件,每个代表一种环境。 ·application-dev.properties/yml 开发环境 ·application-test.properties/yml 测试环境 ·application-pro.properties/yml 生产环境 ·yml多文档方式:在yml中使用 — 分隔不同配置 profile激活三种方式: ·配置文件: 再配置文件中配置:spring.profiles.active=dev ·虚拟机参数:在VMoptions 指定:-Dspring.profiles.active=dev ·命令行参数:java–jarxxx.jar–spring.profiles.active=dev 但是考虑到一个问题,生产环境的配置文件的安全性,显然我们不能, 也不应该把生产环境的配置文件放到项目仓库Git中,进行管理。一般我们将生 产环境的配置文件放到生产环境的服务器中,以固定命令执行启动: java -jar myboot.jar
- -spring.config.location=/xx/yy/xx/application-prod.properties。或者,使 用Jenkins在执行打包,配置上mavenprofile功能,使用服务器的配置文件。 最后一种方式,使用配置中心管理配置文件;
8 15 SpringBoot可以兼容老Spring项目吗,如何做?(了解)………………………………
可以兼容,使用 @ImportResource 注解导入老Spring 项目配置文件。
8 16 保护SpringBoot应用有哪些方法?(了解)…………………………………………………….
1 .在生产中使用HTTPS…………………………………………………………………………………………
传输层安全性(TLS)是HTTPS的官方名称,你可能听说过它称为SSL(安
全套接字层),SSL是已弃用的名称,TLS是一种加密协议,可通过计算机网络
提供安全通信。其主要目标是确保计算机应用程序之间的隐私和数据完整性。
过去,TLS/SSL证书很昂贵,而且HTTPS被认为很慢,现在机器变得更
快,已经解决了性能问题,Let’sEncrypt提供免费的TLS证书,这两项发展改变 了游戏,并使TLS成为主流。
2 .使用Snyk检查你的依赖关系…………………………………………………………………………….
你很可能不知道应用程序使用了多少直接依赖项,这通常是正确的,尽管依
赖性构成了整个应用程序的大部分。攻击者越来越多地针对开源依赖项,因为它
们的重用为恶意黑客提供了许多受害者,确保应用程序的整个依赖关系树中没有
已知的漏洞非常重要。
Snyk测试你的应用程序构建包,标记那些已知漏洞的依赖项。它在仪表板 在应用程序中使用的软件包中存在的漏洞列表。 此外,它还将建议升级的版本或提供补丁,并提供针对源代码存储库的拉取 请求来修复您的安全问题。Snyk还确保在你的存储库上提交的任何拉取请求(通 过webhooks)时都是通过自动测试的,以确保它们不会引入新的已知漏洞。
3 .升级到最新版本…………………………………………………………………………………………………
定期升级应用程序中的依赖项有多种原因。安全性是让您有升级动力的最重
要原因之一。该start.spring.io起始页面采用了最新的春季版本的软件包,以及 依赖关系,在可能的情况。 基础架构升级通常不如依赖项升级具有破坏性,因为库作者对向后兼容性和 版本之间的行为更改的敏感性各不相同。话虽如此,当你在配置中发现安全漏洞 时,您有三种选择:升级,修补程序或忽略。
8 17 SpringBoot 2 .X 有什么新特性?与 1 .X有什么区别?(了解)………………………..
SpringBoot 2. 0 需要Java 8 作为最低版本。许多现有的API已经更新, 以利用Java 8 的功能,例如:接口上的默认方法,功能回调和新的API,如 javax.time。如果您当前使用的是Java 7 或更早版本,那么在开发SpringBoot 2. 0 应用程序之前,您需要升级JDK。 SpringBoot 2. 0 也运行良好,并且已经过JDK 9 的测试。我们所有的 jar都在模块系统兼容性的清单中附带自动模块名称条目。
配置变更
在 2 .x 中废除了一些 1 .x 中的配置,并增加了许多新配置, 依赖 JDK 版本升级 2 .x 至少需要 JDK 8 的支持, 2 .x 里面的许多方法应用了 JDK 8 的许多高 级新特性,所以你要升级到 2. 0 版本,先确认你的应用必须兼容 JDK 8 。另外,
2 .x 开始了对 JDK 9 的支持。 第三方类库升级 2 .x 对第三方类库升级了所有能升级的稳定版本,一些值得关注的类库升 级我给列出来了。 1 )SpringFramework 5 + 2 )Tomcat 8. 5 + 3 )Flyway 5 + 4 )Hibernate 5. 2 + 5 )Thymeleaf 3 +
配置属性绑定
在 1 .x 中,配置绑定是通过注解 @ConfigurationProperties来注入 到 Spring环境变量中的。
在 2 .x 中,配置绑定功能有了些的改造,在调整了 1 .x 中许多不一致 地方之外,还提供了独立于注解之外的 API来装配配置属性。并增加了属性来 源,这样你就能知道这些属性是从哪个配置文件中加载进来的。
九.SpringCloud框架………………………………………………………………………………………………………….
9 1 什么是SpringCloud框架?(必会)……………………………………………………………………
SpringCloud 是一系列框架的有序集合,它利用 SpringBoot 的开发便利性 简化了分布式系统的开发,比如服务发现.服务网关.服务路由.链路追踪等。其设
计目的是为了简化 Spring 应用的搭建和开发过程。该框架遵循“约定大于配 置”原则,采用特定的方式进行配置,从而使开发者无需定义大量的 XML配 置 。通过这种方式,SpringBoot 致力于在蓬勃发展的快速应用开发领域成为领 导者。SpringCloud并不重复造轮子,而是将市面上开发得比较好的模块集成 进去,进行封装,从而减少了各模块的开发成本。换句话说:Springcloud 提 供了构建分布式系统所需的“全家桶”。核心组件如下: Eureka :各个服务启动时,EurekaClient都会将服务注册到Eureka Server,并且EurekaClient还可以反过来从EurekaServer拉取注册表, 从而知道其他服务在哪里 Ribbon :服务间发起请求的时候,基于Ribbon做负载均衡,从一个服务 的多台机器中选择一台 Feign :基于Feign的动态代理机制,根据注解和选择的机器,拼接请求 URL地址,发起请求 Hystrix :发起请求是通过Hystrix的线程池来走的,不同的服务走不同的 线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题 Zuul :如果前端.移动端要调用后端系统,统一从Zuul网关进入,由Zuul 网关转发请求给对应的服务
9 2 核心组件讲解:(高薪常问)……………………………………………………………………………….
9 2 1 Eureka(服务中心)(必会)………………………………………………………………………….
作用:实现服务治理(服务注册与发现)
简介:SpringCloudEureka是SpringCloudNetflix项目下的服务治理模 块。 由两个组件组成:Eureka服务端和Eureka客户端。 Eureka服务端用作服务注册中心。支持集群部署。 Eureka客户端是一个java客户端,用来处理服务注册与发现。 在应用启动时,Eureka客户端向服务端注册自己的服务信息,同时将服务 端的服务信息缓存到本地。客户端会和服务端周期性的进行心跳交互,以更新服 务租约和服务信息。
9 2 2 Ribbon(负载均衡工具)(了解)………………………………………………………………….
作用:Ribbon,主要提供客户侧的软件负载均衡算法。 简介:SpringCloudRibbon是一个基于HTTP和TCP的客户端负载均衡 工具,它基于NetflixRibbon实现。通过S的封装,可以让我们轻松地将面向 服务的REST模版请求自动转换成客户端负载均衡的服务调用。 注意看上图,关键点就是将外界的rest调用,根据负载均衡策略转换为微 服务调用。Ribbon有比较多的负载均衡策略,以后专门讲解。
9 2 3 Hystrix(熔断器)(必会)……………………………………………………………………………..
作用:断路器,保护系统,控制故障范围。
简介:为了保证其高可用,单个服务通常会集群部署。由于网络原因或者自
身的原因,服务并不能保证 100 %可用,如果单个服务出现问题,调用这个服务
就会出现线程阻塞,此时若有大量的请求涌入,Servlet容器的线程资源会被消 耗完毕,导致服务瘫痪。服务与服务之间的依赖性,故障会传播,会对整个微服 务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
9 2 4 Zuul(服务网关)(必会)……………………………………………………………………………..
作用:api网关,路由,负载均衡等多种作用 简介:类似nginx,反向代理的功能,不过netflix自己增加了一些配合其 他组件的特性。 在微服务架构中,后端服务往往不直接开放给调用端,而是通过一个API 网关根据请求的url,路由到相应的服务。当添加API网关后,在第三方调用端 和服务提供方之间就创建了一面墙,这面墙直接与调用方通信进行权限控制,后 将请求均衡分发给后台服务端。
9 2 5 Config(配置中心)(了解)………………………………………………………………………….
作用:配置管理
简介:SpringCloudConfig提供服务器端和客户端。服务器存储后端的默 认实现使用git,因此它轻松支持标签版本的配置环境,以及可以访问用于管理 内容的各种工具。 这个还是静态的,得配合SpringCloudBus实现动态的配置更新。
9 2 6 SpringCloud基于业务场景对于各个组件的讲解(了解)…………………………..
先来给大家说一个业务场景,假设咱们现在开发一个电商网站,要实现支付
订单的功能,流程如下:
创建一个订单之后,如果用户立刻支付了这个订单,我们需要将订单状态更
新为“已支付”
扣减相应的商品库存 通知仓储中心,进行发货 给用户的这次购物增加相
应的积分
针对上述流程, 我们需要有订单服务.库存服务.仓储服务.积分服务 。整个流
程的大体思路如下:
用户针对一个订单完成支付之后,就会去找订单服务,更新订单状态
订单服务调用库存服务,完成相应功能
订单服务调用仓储服务,完成相应功能
订单服务调用积分服务,完成相应功能
至此,整个支付订单的业务流程结束
下图这张图,清晰表明了各服务间的调用过程:
好!有了业务场景之后,咱们就一起来看看SpringCloud微服务架构中, 这几个组件如何相互协作,各自发挥的作用以及其背后的原理。 SpringCloud核心组件:Eureka 咱们来考虑第一个问题 :订单服务想要调用库存服务.仓储服务,或者是积 分服务,怎么调用? 订单服务压根儿就不知道人家库存服务在哪台机器上啊!他就算想要发起一 个请求,都不知道发送给谁,有心无力! 这时候,就轮到SpringCloudEureka出场了。Eureka是微服务架构中的 注册中心,专门负责服务的注册与发现。 咱们来看看下面的这张图,结合图来仔细剖析一下整个流程:
如上图所示,库存服务.仓储服务.积分服务中都有一个EurekaClient组件, 这个组件专门负责将这个服务的信息注册到EurekaServer中。说白了,就是告 诉EurekaServer,自己在哪台机器上,监听着哪个端口。而EurekaServer是 一个注册中心,里面有一个注册表,保存了各服务所在的机器和端口号 订单服务里也有一个EurekaClient组件,这个EurekaClient组件会找 EurekaServer问一下:库存服务在哪台机器啊?监听着哪个端口啊?仓储服务
呢?积分服务呢?然后就可以把这些相关信息从EurekaServer的注册表中拉 取到自己本地缓存起来。 这时如果订单服务想要调用库存服务,不就可以找自己本地的Eureka Client问一下库存服务在哪台机器?监听哪个端口吗?收到响应后,紧接着就可 以发送一个请求过去,调用库存服务扣减库存的那个接口!同理,如果订单服务 要调用仓储服务.积分服务,也是如法炮制。 总结一下: EurekaClient: 负责将这个服务的信息注册到EurekaServer中 EurekaServer: 注册中心,里面有一个注册表,保存了各个服务所在的机 器和端口号 SpringCloud核心组件:Feign 现在订单服务确实知道库存服务.积分服务.仓库服务在哪里了,同时也监听 着哪些端口号了。 但是新问题又来了:难道订单服务要自己写一大堆代码,跟其 他服务建立网络连接,然后构造一个复杂的请求,接着发送请求过去,最后对返 回的响应结果再写一大堆代码来处理吗? 这是上述流程翻译的代码片段,咱们一起来看看,体会一下这种绝望而无助 的感受!!! 友情提示,前方高能:
看完上面那一大段代码,有没有感到后背发凉.一身冷汗?实际上你进行服
务间调用时,如果每次都手写代码,代码量比上面那段要多至少几倍,所以这个
事儿压根儿就不是地球人能干的。
既然如此,那怎么办呢?别急,Feign早已为我们提供好了优雅的解决方案。 来看看如果用Feign的话,你的订单服务调用库存服务的代码会变成啥样?
看完上面的代码什么感觉?是不是感觉整个世界都干净了,又找到了活下去
的勇气!没有底层的建立连接.构造请求.解析响应的代码,直接就是用注解定义
一个 FeignClient接口,然后调用那个接口就可以了。人家FeignClient会在 底层根据你的注解,跟你指定的服务建立连接.构造请求.发起靕求.获取响应.解析 响应,等等。这一系列脏活累活,人家Feign全给你干了。 那么问题来了,Feign是如何做到这么神奇的呢?很简单, Feign的一个关 键机制就是使用了动态代理 。咱们一起来看看下面的图,结合图来分析: 首先,如果你对某个接口定义了@FeignClient注解,Feign就会针对这个 接口创建一个动态代理 接着你要是调用那个接口,本质就是会调用Feign创建的动态代理,这是 核心中的核心 Feign的动态代理会根据你在接口上的@RequestMapping等注解,来动 态构造出你要请求的服务的地址 最后针对这个地址,发起请求.解析响应
SpringCloud核心组件:Ribbon 说完了Feign,还没完。现在新的问题又来了,如果人家库存服务部署在了 5 台机器上,如下所示:
192. 168. 169 : 9000
192. 168. 170 : 9000
192. 168. 171 : 9000
192. 168. 172 : 9000
192. 168. 173 : 9000
这下麻烦了!人家Feign怎么知道该请求哪台机器呢? 这时SpringCloudRibbon就派上用场了。Ribbon就是专门解决这个问题 的。它的作用是负载均衡,会帮你在每次请求时选择一台机器,均匀的把请求分 发到各个机器上 Ribbon的负载均衡默认使用的最经典的RoundRobin轮询算法。这是啥? 简单来说,就是如果订单服务对库存服务发起 10 次请求,那就先让你请求第 1 台机器.然后是第 2 台机器.第 3 台机器.第 4 台机器.第 5 台机器,接着再来—个 循环,第 1 台机器.第 2 台机器。。。以此类推。 此外,Ribbon是和Feign以及Eureka紧密协作,完成工作的,具体如 下: 首先Ribbon会从EurekaClient里获取到对应的服务注册表,也就知道了 所有的服务都部署在了哪些机器上,在监听哪些端口号。 然后Ribbon就可以使用默认的RoundRobin算法,从中选择一台机器 Feign就会针对这台机器,构造并发起请求。 对上述整个过程,再来一张图,帮助大家更深刻的理解:
SpringCloud核心组件:Hystrix 在微服务架构里,一个系统会有很多的服务。以本文的业务场景为例:订单 服务在一个业务流程里需要调用三个服务。现在假设订单服务自己最多只有 100 个线程可以处理请求,然后呢,积分服务不幸的挂了,每次订单服务调用积分服 务的时候,都会卡住几秒钟,然后抛出—个超时异常。 咱们一起来分析一下,这样会导致什么问题? 如果系统处于高并发的场景下,大量请求涌过来的时候,订单服务的 100 个线程都会卡在请求积分服务这块。导致订单服务没有一个线程可以处理请求 然后就会导致别人请求订单服务的时候,发现订单服务也挂了,不响应任何 请求了 上面这个,就是 微服务架构中恐怖的服务雪崩问题 ,如下图所示:
如上图,这么多服务互相调用,要是不做任何保护的话,某一个服务挂了,
就会引起连锁反应,导致别的服务也挂。比如积分服务挂了,会导致订单服务的
线程全部卡在请求积分服务这里,没有一个线程可以工作,瞬间导致订单服务也
挂了,别人请求订单服务全部会卡住,无法响应。
但是我们思考一下,就算积分服务挂了,订单服务也可以不用挂啊!为什么?
我们结合业务来看:支付订单的时候,只要把库存扣减了,然后通知仓库发
货就OK了
如果积分服务挂了,大不了等他恢复之后,慢慢人肉手工恢复数据!为啥一
定要因为一个积分服务挂了,就直接导致订单服务也挂了呢?不可以接受!
现在问题分析完了,如何解决?
这时就轮到Hystrix闪亮登场了。Hystrix是隔离.熔断以及降级的一个框架。 啥意思呢?说白了,Hystrix会搞很多个小小的线程池,比如订单服务请求库存 服务是一个线程池,请求仓储服务是一个线程池,请求积分服务是一个线程池。 每个线程池里的线程就仅仅用于请求那个服务。 打个比方:现在很不幸,积分服务挂了,会咋样?
当然会导致订单服务里的那个用来调用积分服务的线程都卡死不能工作了
啊!但是由于订单服务调用库存服务.仓储服务的这两个线程池都是正常工作的,
所以这两个服务不会受到任何影响。
这个时候如果别人请求订单服务,订单服务还是可以正常调用库存服务扣减
库存,调用仓储服务通知发货。只不过调用积分服务的时候,每次都会报错。 但
是如果积分服务都挂了,每次调用都要去卡住几秒钟干啥呢?有意义吗?当然没
有! 所以我们直接对积分服务熔断不就得了,比如在 5 分钟内请求积分服务直接
就返回了,不要去走网络请求卡住几秒钟,这个过程,就是所谓的熔断!
那人家又说,兄弟,积分服务挂了你就熔断,好歹你干点儿什么啊!别啥都
不干就直接返回啊? 没问题,咱们就来个降级:每次调用积分服务,你就在数据
库里记录一条消息,说给某某用户增加了多少积分,因为积分服务挂了,导致没
增加成功!这样等积分服务恢复了,你可以根据这些记录手工加一下积分。这个
过程,就是所谓的降级。
为帮助大家更直观的理解,接下来用一张图,梳理一下Hystrix隔离.熔断和 降级的全流程:
SpringCloud核心组件:Zuul 说完了Hystrix,接着给大家说说最后一个组件:Zuul,也就是微服务网关。 这个组件是负责网络路由的。不懂网络路由?行,那我给你说说,如果没有Zuul 的日常工作会怎样? 假设你后台部署了几百个服务,现在有个前端兄弟,人家请求是直接从浏览 器那儿发过来的。 打个比方 :人家要请求一下库存服务,你难道还让人家记着这 服务的名字叫做inventory-service?部署在 5 台机器上?就算人家肯记住这一 个,你后台可有几百个服务的名称和地址呢?难不成人家请求一个,就得记住一 个?你要这样玩儿,那真是友谊的小船,说翻就翻! 上面这种情况,压根儿是不现实的。所以一般微服务架构中都必然会设计一 个网关在里面,像android.ios.pc前端.微信小程序.H 5 等等,不用去关心后端 有几百个服务,就知道有一个网关,所有请求都往网关走,网关会根据请求中的 一些特征,将请求转发给后端的各个服务。
而且有一个网关之后,还有很多好处,比如可以做统一的降级.限流.认证授
权.安全,等等。
9 3 SpringCloud和Dubbo的区别(必会)………………………………………………………………
SpringCloud:Spring公司开源的微服务框架,SpirngCloud 定位为 微服务架构下的一站式解决方案(微服务生态)。 Dubbo:阿里巴巴开源的RPC框架,Dubbo 是 SOA 时代的产物,它 的关注点主要在于服务的调用,流量分发、流量监控和熔断。
SpringCloud 的功能很明显比 Dubbo 更加强大,涵盖面更广,而且 作为 Spring 的旗舰项目,它也能够与 SpringFramework、SpringBoot、 SpringData、SpringBatch 等其他 Spring 项目完美融合,这些对于微服务 而言是至关重要的。 使用 Dubbo 构建的微服务架构就像组装电脑,各环节选择自由度很 高,但是最终结果很有可能因为一条内存质量不行就点不亮了,总是让人不怎么 放心,但是如果使用者是一名高手,那这些都不是问题。
而 SpringCloud就像品牌机,在 SpringSource 的整合下,做了大 量的兼容性测试,保证了机器拥有更高的稳定性,但是如果要在使用非原装组件 外的东西,就需要对其基础原理有足够的了解。
9 4 使用SpringCloud的优缺点?(必会)………………………………………………………………..
优点:
1 、服务拆分粒度更细,有利于资源重复利用,有利于提高开发效率
2 、可以更精准的制定优化服务方案,提高系统的可维护性
3 、微服务架构采用去中心化思想,服务之间采用Restful等轻量级通讯,比 ESB更轻量 4 、适于互联网时代,产品迭代周期更短 缺点: 1 、微服务过多,治理成本高,不利于维护系统 2 、分布式系统开发的成本高(容错,分布式事务等)对团队挑战大
总的来说优点大过于缺点,目前看来SpringCloud是一套非常完善的分布 式框架,目前很多企业开始用微服务、SpringCloud 的优势是显而易见的。因 此对于想研究微服务架构的同学来说,学习 SpringCloud是一个不错的选择。
9 5 服务注册和发现是什么意思?SpringCloud如何实现?(必会)………………………….
当我们开始一个项目时,我们通常在属性文件中进行所有的配置。随着越来
越多的服务开发和部署,添加和修改这些属性变得更加复杂。有些服务可能会下
降,而某些位置可能会发生变化。手动更改属性可能会产生问题。Eureka服务 注册和发现可以在这种情况下提供帮助。由于所有服务都在Eureka服务器上注 册并通过调用Eureka服务器完成查找,因此无需处理服务地点的任何更改和处 理。
9 6 负载平衡的意义什么?(必会)……………………………………………………………………………
在计算中,负载平衡可以改善跨计算机,计算机集群,网络链接,中央处理
单元或磁盘驱动器等多种计算资源的工作负载分布。负载平衡旨在优化资源使
用,最大化吞吐量,最小化响应时间并避免任何单一资源的过载。使用多个组件
进行负载平衡而不是单个组件可能会通过冗余来提高可靠性和可用性。负载平衡
通常涉及专用软件或硬件,例如多层交换机或域名系统服务器进程。
9 7 什么是Hystrix?它如何实现容错?(必会)……………………………………………………….
Hystrix是一个延迟和容错库,旨在隔离远程系统,服务和第三方库的访问 点,当出现故障是不可避免的故障时,停止级联故障并在复杂的分布式系统中实 现弹性。 通常对于使用微服务架构开发的系统,涉及到许多微服务。这些微服务彼此 协作。
思考以下微服务
假设如果上图中的微服务 9 失败了,那么使用传统方法我们将传播一个异
常。但这仍然会导致整个系统崩溃。
随着微服务数量的增加,这个问题变得更加复杂。微服务的数量可以高达
1000 .这是hystrix出现的地方 我们将使用Hystrix在这种情况下的Fallback方 法功能。我们有两个服务employee-consumer使用由employee-consumer 公开的服务。 现在假设由于某种原因,employee-producer公开的服务会抛出异常。我 们在这种情况下使用Hystrix定义了一个回退方法。这种后备方法应该具有与公 开服务相同的返回类型。如果暴露服务中出现异常,则回退方法将返回一些值。
9 8 什么是Hystrix断路器?我们需要它吗?(了解)………………………………………………..
由于某些原因,employee-consumer公开服务会引发异常。在这种情况下 使用Hystrix我们定义了一个回退方法。如果在公开服务中发生异常,则回退方 法返回一些默认值。 如果firstPagemethod() 中的异常继续发生,则Hystrix电路将中断,并 且员工使用者将一起跳过firtsPage方法,并直接调用回退方法。 断路器的目 的是给第一页方法或第一页方法可能调用的其他方法留出时间,并导致异常恢 复。可能发生的情况是,在负载较小的情况下,导致异常的问题有更好的恢复机 会 。
9 9 什么是NetflixFeign?它的优点是什么?(了解)………………………………………………
Feign是受到Retrofit,JAXRS- 2. 0 和WebSocket启发的java客户端联编 程序。Feign的第一个目标是将约束分母的复杂性统一到httpapis,而不考虑 其稳定性。在employee-consumer的例子中,我们使用了 employee-producer使用REST模板公开的REST服务。 但是我们必须编写大量代码才能执行以下步骤: 1 .使用功能区进行负载平衡。 2 .获取服务实例,然后获取基本URL。 3 .利用REST模板来使用服务。 前面的代码如下 @Controller p@uAbulictocwlairsesdConsumerControllerClient{ ppruivbalitcevLooidadgBeatlEamncpelorCyleieen()ttlhoraodwBsalRaenscteCrl;ientException,IOException{ ServiceInstanceserviceInstance=loadBalancer.choose(“employee-producer”); SSytrsitnegmb.oauset.Uprril=ntslenr(vsiecrevIincestIannstcaen.gceet.gUerti(U).rtio()S)t;ring(); bRaessetTUerml=pblaasteeUrersl+tT"e/emmpplaltoey=ee"n;ewRestTemplate(); ResponseEntityresponse=null; trreys{ponse=restTemplate.exchange(baseUrl, }catch(EHxctetppMtioentheoxd).GET,getHeaders(),String.class); { } System.out.println(ex); } System.out.println(response.getBody()); 之前的代码,有像NullPointer这样的例外的机会,并不是最优的。我们将 看到如何使用NetflixFeign使呼叫变得更加轻松和清洁。如果NetflixRibbon
依赖关系也在类路径中,那么Feign默认也会负责负载平衡。
9 10 什么是SpringCloudBus?我们需要它吗?(了解)…………………………………………
考虑以下情况:我们有多个应用程序使用SpringCloudConfig读取属性, 而SpringcloudConfig从GIT读取这些属性。 下面的例子中多个员工生产者模块从EmployeeConfigModule获取 Eureka注册的财产。 如果假设GIT中的Eureka注册属性更改为指向另一台Eureka服务器,会 发生什么情况。在这种情况下,我们将不得不重新启动服务以获取更新的属性。 还有另一种使用执行器端点/刷新的方式。但是我们将不得不为每个模块单 独调用这个url。例如,如果EmployeeProducer 1 部署在端口 8080 上,则调 用 http://localhost: 8080 /refresh。同样对于EmployeeProducer 2 http: //localhost: 8081 /refresh等等。这又很麻烦。这就是SpringCloudBus发 挥作用的地方。 SpringCloudBus提供了跨多个实例刷新配置的功能。因此,在上面的示 例中,如果我们刷新EmployeeProducer 1 ,则会自动刷新所有其他必需的模 块。如果我们有多个微服务启动并运行,这特别有用。这是通过将所有微服务连 接到单个消息代理来实现的。无论何时刷新实例,此事件都会订阅到侦听此代理 的所有微服务,并且它们也会刷新。可以通过使用端点/总线/刷新来实现对任何 单个实例的刷新。
9 11 Eureka和Zookeeper注册中心的区别(高新常问)………………………………………….
先看下CAP原则:C-数据一致性;A-服务可用性;P-服务对网络分区
故障的容错性,这三个特性在任何分布式系统中不能同时满足,最多同时满足两
个:
1 .Eureka满足AP,Zookeeper满足CP 2 .Zookeeper满足一致性、容错性。数据要在各个服务间同步完成后才 返回用户结果,而且如果服务出现网络波动,会立即从服务列表中剔除,服务不 可使用 3 .Eureka满足AP,可用性,容错性。当因网络故障时,Eureka的自我 保护机制不会立即剔除服务,虽然用户获取到的服务不一定时可用的,但是至少 能够获取到服务列表。用户访问服务列表时还可以利用重试机制,找到正确的服 务。更符合分布式服务的高可用需求 4 .Eureka集群各节点平等,Zookeeper中有主从之分 5. 如果Zookeeper集群中部分宕机,可能会导致整个集群因为选主而 阻塞,服务不可用 6 .eureka集群宕机部分,不会对其它机器产生影响 7 .Eureka的服务发现需要主动去拉取,Zookeeper服务发现是监听机 制 8 .eureka中获取服务列表后会缓存起来,每隔 30 秒重新拉取服务列表 9 .zookeeper则是监听节点信息变化,当服务节点信息变化时,客户端 立即就得到通知
十.乐优商城………………………………………………………………………………………………………………………..
10 1 项目介绍……………………………………………………………………………………………………………..
乐优商城是一个基于微服务架构的、全品类的 B 2 C电商购物网站,整个项目
分为后台管理和前台门户两个入口。用户可以在前台门户进行商品的浏览、搜索、
购物车、下单、支付和个人管理等操作。在后台管理中管理员可以对商品进行管
理、制定促销活动、监控商品销售状态与订单进展情况等。
乐优商城采用了微服务架构,微服务技术采用了SpringCloud技术栈,各个 微服务站点基于SpringBoot构建,并采用SpringCloudGateway将各个微服 务的功能串联起来,形成一套套系统,同时在微服务网关Gateway中采用过滤 和限流策略,实施对微服务进行保护和权限认证操作。项目采用了JWT技术解 决了各个微服务之间的单点登录和用户授权。项目中使用Atomikos来解决微服 务与微服务之间的分布式事务。采用了Elasticsearch解决了海量商品的实时检 索。数据存储采用了MySQL,并结合Canal实现数据同步操作,利用Redis做 数据缓存操作。各个微服务之间采用RabbitMQ实现异步通信。使用thymeleaf 做页面静态化进行性能提升。在实现购物车功能我们分为未登录和已登录,未登 录我们采取localstorage进行存储用户信息。
10 1 1 什么是微服务…………………………………………………………………………………………….
(MartinFowler提出的微服务)微服务架构就是将单一程序开发成一个微 服务,每个微服务运行在自己的进程中,并使用轻量级的机制通信,通常是HTTP RESTFULAPI。这些服务围绕业务能力来划分,并通过自动化部署机制来独立部
署。这些服务可以使用不同的编程语言,不同数据库,以保证最低限度的集中式
管理。
总结来说:微服务,又称微服务架构,是一种分布式的系统。就是将一个单
体架构的应用按业务划分为一个个独立运行的程序即服务,它们之间通过HTTP
协议进行通信,可以采用不同的编程语言,使用不同的存储技术,自动化部署减
少人为控制,降低出错概率。服务数量越多,管理起来越复杂,因此采用集中化
管理。
10 1 2 微服务有什么优势……………………………………………………………………………………..
独立开发:所有微服务都可以根据各自的功能轻松开发。
独立部署:基于其服务,可以在任何应用程序中单独部署它们。
故障隔离:即使应用程序的一项服务不起作用,系统仍可继续运行。
混合技术:可以使用不同的语言、技术来构建同一应用程序的不同服务。
粒度缩放:单个组件可根据需要进行缩放,无需将所有组件缩放在一起。
10 1 3 SOA与微服务的关系…………………………………………………………………………………
SOA即面向服务的架构,SOA是根据企业服务总线(ESB)模式来整合集
成大量单一庞大的系统。微服务可以说是SOA的一种实现,将复杂的业务组件
化,但它比ESB实现的SOA更加的轻便敏捷和简单。
10 1 4 什么是单体架构…………………………………………………………………………………………
在软件设计的时候经常提到和使用经典的 3 层模型,即表现层,业务逻辑层,
数据访问层。虽然在软件设计中划分了 3 层模型,但是对业务场景没有划分,一
个典型的单体架构就是将所有的业务场景的表现层,业务逻辑层,数据访问层放
在一个工程中最终经过编译,打包,部署在一台服务器上。
10 1 5 单体架构的不足…………………………………………………………………………………………
在小型应用的初期,访问量小的时候这种架构的性价比还是比较高的,开发
速度快,成本低。但是随着业务的发展,逻辑越来越复杂,代码量越来越大,代
码得可读性和可维护性越来越低。用户的增加,访问量的越来越多,单体架构的
应用并发能力十分有限。可能会有人想到将单体应用进行集群部署,并增加负载
均衡服务器,再来个缓存服务器和文件服务器,数据库再搞个读写分离。这种架
构如图:
这种架构虽然有一定的并发能力,以及应对一定的复杂业务,但是依然没有
改变系统为单体架构的事实。大量的业务必然会有大量的代码,代码得可读性和
可维护性依然很差。如果面对海量的用户,它的并发能力依然不够。
10 1 6 B 2 C……………………………………………………………………………………………………………
10. 1. 6. 1 什么是B 2 C
B 2 C企业对个人,是Business-to-Customer的缩写,中文简称“商对客”。 “商对客”是电子商务的一种模式,也就是通常说的直接面向消费者销售产品和 服务的商业零售模式。这种形式的电子商务一般以网络零售业为主,主要是借助 于互联网开展在线销售活动。B 2 C即企业通过互联网为消费者提供一个新型的 购物环境——网上商店,消费者通过网络在网上购物、网上支付等消费行为。 案例:唯品会、乐蜂网
10. 1. 6. 2 其它的电商模式有哪些?
1 .B 2 B—企业对企业
B 2 B( BusinesstoBusiness)是指进行电子商务交易的供需双方都是商 家(或企业、公司),她(他)们使用了互联网的技术或各种商务网络平台,完 成商务交易的过程。 案例:阿里巴巴、慧聪网
2 .C 2 C—个人对个人
C 2 C即 Customer(Consumer) toCustomer(Consumer),意思就 是消费者个人间的电子商务行为。比如一个消费者有一台电脑,通过网络进行交 易,把它出售给另外一个消费者,此种交易类型就称为C 2 C电子商务。 案例:淘宝、易趣、瓜子二手车
3 .B 2 B 2 C—企业对企业对个人
B 2 B 2 C是一种电子商务类型的网络购物商业模式,B是BUSINESS的简称, C是CUSTOMER的简称,第一个B指的是商品或服务的供应商,第二个B指 的是从事电子商务的企业,C则是表示消费者。 第一个BUSINESS,并不仅仅局限于品牌供应商、影视制作公司和图书出版 商,任何的商品供应商或服务供应商都能可以成为第一个BUSINESS;第二B 是B 2 B 2 C模式的电子商务企业,通过统一的经营管理对商品和服务、消费者终 端同时进行整合,是广大供应商和消费者之间的桥梁,为供应商和消费者提供优 质的服务,是互联网电子商务服务供应商。C表示消费者,在第二个B构建的统 一电子商务平台购物的消费者; B 2 B 2 C的来源于目前的B 2 B、B 2 C模式的演变和完善,把B 2 C和C 2 C完 美地结合起来,通过B 2 B 2 C模式的电子商务企业构建自己的物流供应链系统, 提供统一的服务。 案例:京东商城、天猫商城
4 .O 2 O—线上对线下
O 2 O即OnlineToOffline(在线离线/线上到线下),是指将线下的商务机 会与互联网结合,让互联网成为线下交易的平台,这个概念最早来源于美国。 O 2 O的概念非常广泛,既可涉及到线上,又可涉及到线下,可以通称为O 2 O。 主流商业管理课程均对O 2 O这种新型的商业模式有所介绍及关注。 案例:美团、饿了吗
10 2 项目架构……………………………………………………………………………………………………………..
10 2 1 传统架构……………………………………………………………………………………………………
存在的问题
1 、开发、维护代码比较困难
2 、系统内部的功能模块之间的耦合度太高了
3 、无法针对每个模块的特性做优化
4 、无法做服务器的水平扩展
5 、无法存储海量数据
10 2 2 SOA架构…………………………………………………………………………………………………..
SOA[组装服务/ESB企业服务总线](解决了传统架构的所有问题)
业务系统分解为多个组件,让每个组件都独立提供离散,自治,可复用的服
务能力。通过服务的组合和编排来实现上层的业务流程。
作用:简化维护,降低整体风险,伸缩灵活。
10 2 3 微服务架构………………………………………………………………………………………………..
微服务,又称微服务架构,是一种分布式的系统(解决了传统架构的所
有问题)
10 3 项目功能……………………………………………………………………………………………………………..
10 3 1 人员配置……………………………………………………………………………………………………
产品经理: 3 人( 1 个经理, 2 个产品),确定需求以及给出产品原型图。
项目经理: 1 人,项目管理。
前端团队: 2 人,根据产品经理给出的原型图制作静态页面。
后端团队: 5 人,根据项目经理分配的任务完成产品功能。
测试团队: 2 人,采用白盒测试以及黑盒测试对产品功能性能进行检测。
运维团队: 1 人,项目的发布以及维护。
10 3 2 开发流程……………………………………………………………………………………………………
10 3 3 开发技术……………………………………………………………………………………………………
前端
基础的HTML、CSS、JavaScript(基于ES 6 标准) JQuery Vue.js 2. 0 基于Vue的UI框架:Vuetify 前端构建工具:WebPack,项目编译、打包工具 前端安装包工具:NPM Vue脚手架:Vue-cli Vue路由:vue-router ajax框架:axios 基于Vue的富文本框架:quill-editor 后端 基础的SpringMVC、Spring 5. 0 和MyBatisPlus MySQL 5. 7
SpringBoot 2. 1. 3 版本
SpringCloud版本 Greenwich.Release
Redis- 4. 0
RabbitMQ- 3. 7
Elasticsearch- 6. 2. 4
nginx- 1. 10. 2
Thymeleaf 模板语言
JWT
10 3 4 数据库表结构…………………………………………………………………………………………….
表名称 含义
tb_application 服务信息表
tb_application_privilege 服务中间表
tb_brand 品牌表
tb_category 商品分类表
tb_category_brand 商品分类和品牌的中间表
tb_order 订单表
tb_order_detail 订单详情表
tb_order_logistics 订单物流表
tb_sku sku表
tb_spec_group 规格参数的分组表
tb_spec_param 规格参数组下的参数名表
10 4 模块业务……………………………………………………………………………………………………………..
10 4 1 业务思路……………………………………………………………………………………………………
首先描述自己所做项目有哪些功能模块
举例 :最近做了一个电商项目,我负责的模块包括前台系统,搜索系统,还有订
单系统。
描述其中单个模块有哪些功能
举例: 首先前台系统的大部分功能类似于淘宝京东的首页,主要的功能有左侧商
品类目的回显,广告位,楼层数据的回显,以及完成这些数据在后台的管理,包
括页面静态化。
拆分单独功能进行描述
举例: 其中左侧商品类目回显的功能类似于淘宝京东的左侧类目,在首页的左侧
有很多商品的一级目录,比如手机,电脑之类的。鼠标放在一级目录上会触发一
个事件弹出一个窗口显示二级目录,以此类推总共有三级目录。
描述功能中碰到的问题
举例: 在做这个商品类目回显的时候我们发现数据从后台抓取过来,前台页面解
析不了。
介绍技术,对比技术
举例: 对于商品类目数据解析不了的问题是因为跨域,对于跨域我们先是采用了
tb_spu spu表
tb_spu_detail Spu详情表
tb_user 用户表
jsonp来解决,它的优点是什么?缺点是什么?由于这个技术的缺点我们引入了 新的技术,httpclient,这个技术是什么?优点是什么?缺点是什么?介绍完技 术,再介绍功能,循环嵌套。
10 5 商品管理(CORS,MQ,OSS,Nginx)……………………………………………………………………….
10 5 1 表设计……………………………………………………………………………………………………….
一件商品的录入大致分为 6 个部分, 8 张表:
分类 tb_category
品牌 tb_brand,tb_category_brand
规格 tb_spec_group,tb_spec_param
SPUtb_spu
SKUtb_sku
商品描述 tb_spu_detail
项目中商品表分为spu商品表 和 sku商品表,比如spu 是 iphone 6 , sku 就是 iphone 6 金色 64 G ,sku表是一个具体的商品,可以影响库存的一 个商品。
spu这张表包含了商品的基础信息和html静态页面数据,比如详情页,售 后处理以及商品描述,这部分数据量过大, 所以应用了数据库垂直分表 ,将spu 中数据量大且增删操作不需要的数据保存到spu_detail表中,增加查询的效率。 商品录入是接收到前端包含spu和sku表数据的json对象,先进行spu商 品表保存,保存sku表指定录入的商品为下架状态同时维护与spu表的关系, 保存spu_detail表同时维护与spu商品表的关系,因为没有各表之间没有物理 关联,所以业务层要对表关系进行维护。 外键会严重影响数据库读写的效率,数据删除时会比较麻烦, 因此我们没有 设计外键. 在电商行业,性能是非常重要的。我们宁可在代码中通过逻辑来维护 表关系,也不设置外键。 举例说明: 商品的数据模型分析: 从两个功能:商品展示,新增商品 两个纬度:数 据库,业务需求 Spu:标准产品单元,具有相同属性商品集。举例:华为p 40 华为P 40 根据不同颜色,内存,机身存储分了很多版本 引入Sku概念— 不同的版本对应库存量不一样 Sku:库存量单元,最小库存量单元。根据影响库存量特殊属性有关系。各 个特殊属性之间乘积。 商品列表页中 展示是商品SPU,但选择小图片,选择的是SKU。 商品数据模型分析: 技巧:从页面效果出发 SPU应该有哪些字段:需要将整个商品详情页中所有关于商品的信息全部展 示
id(spuId) spuName(商 品名称)
brandId(品
牌ID)
categoryId(分
类ID)
subTitle(促
销标题)
desc(商品详
情)
afterServic e障(售)后保 1 华为P 40 华为 76 全系上市 txt,image,vi dwo
xxxx
在上面字段基础上 商品页面中还包括 商品规格参数值->不能采用列的形
式存储…以上字段 入网型号 产品名称 上市年份 机身长度(mm) 机 身厚度(mm) 在规格参数表中 存放规格参数Key 规格参数value 应该存 规格参数表—商品:多对多 方案一:(不使用) 提供中间表:商品规格参数值: id spu_id spec_param_id spec_param_val
110012 11 27 PA (^4) n (^0) droid 这种设计方案可以通过关联查询 将商品的规格参数key 参数val 一对一 对应。 弊端:电商系统考虑查询效率,需要进行多张表关联查询 效率低 方案二:不提供中间表,通过json表示多对多。展示规格参数值 直接将规 格参数转为json-map,操作是内存。执行效率会很高 规格参数表:存在generic字段:表示规格参数是否为普通 1 :普通规格 参数 0 :特殊规格参数(影响商品库存-价格) 在商品基础上提供字段 普通规格参数 特殊规格参数(影响库存) id 1 spuName brandId…. g(普en通e规ric格_p参ar数am) special_param(特殊规格参数)
1
1
华为P 40 200 {" 1 ":"华为
"," 3 ":" 2020 "," 9 ":"海思"}
{" 4 ":["白","黑
", 12 :[" 6 G"," 8 G"], 13 :[" 128 G", 256 G]}
Spu-Sku关系:一对多 一个spu根据不同版本产生多个sku ,一个sku 只能属于一个spu Sku表数据模型分析: id Title price(价格) image stock(库存) enable own_spec(当前sku特殊规格参数) 1001 华为 P 84 + 012 白 8
4000 a.png,b.p
ng
100 1 {" 4 ":"白"," 12 ":" 8 GB"," 13 ":" 128 GB"}
1001 华为 P 40 白 8 + 128
4000 a.png,b.p
ng
100 1 {" 4 ":"黑"," 12 ":" 8 GB"," 13 ":" 128 GB"}
10 5 2 什么是SPU和SKU……………………………………………………………………………………
SPU:StandardProductUnit (标准产品单位) ,一组具有共同属性的 商品集。 SKU:StockKeepingUnit(库存量单位),SPU商品集因具体特性不同而 细分的每个商品。
10 5 3 为什么不设置外键约束………………………………………………………………………………
外键会严重影响数据库读写的效率。
数据删除时会比较麻烦。
在电商行业,性能是非常重要的。我们宁可在代码中通过逻辑来维护表关系,
也不设置外键。
10 5 4 业务思路…………………………………………………………………………………………………..
商品管理下有四个小模块,分别是分类列表、品牌列表,规格列表和商品列
表。每个模块都分别具有列表、新增、修改和删除等基本功能,其中商品模块不
光具有这些功能,还包括商品的上架和下架。
在品牌、商品的新增和修改中值得说的是图片上传。图片上传我们最初采用
的是本地上传:将用户上传的图片保存到Nginx的静态资源文件夹下,并生成 该图片的访问路径保存到数据库,之后页面通过图片访问路径直接获取Nginx 下的图片。这种本地图片上传能够实现图片上传功能,但是考虑到单机器存储能 力有限,多台机器间无法共享资源,数据没有备份,并发能力差等问题,修改本 地图片上传为阿里云存储对象OSS。阿里的OSS是一个提供海量,安全,成本 低,高可靠的云存储服务,可以使用RESTFulAPI在互联网任何位置存储和访 问。用户每次上传图片都会带着后台生产的签名将图片保存到OSS中,成功后 OSS会返回图片的公共访问路径,页面通过此路径访问OSS上的图片。 一件商品只有在上架后才能进行销售,在下架后才能对商品的信息进行修 改。同时在商品的上架和下架时会通过RabbitMQ通知静态页面微服务和搜索 微服务进行静态页面的生产和删除,索引库的创建和删除。
10 5 5 什么是跨域……………………………………………………………………………………………….
跨域是指跨域名的访问,以下情况都属于跨域:
域名相同,端口不同:www.jd.com: 8080 与 http://www.jd.com: 8081 。
域名不同:www.jd.com 与 http://www.taobao.com。 二级域名不同:item.jd.com 与 miaosha.jd.com。 如果域名和端口都相同,但是请求路径不同,不属于跨域,如: http://www.jd.com/item 与 http://www.jd.com/goods。
10 5 6 为什么有跨域问题…………………………………………………………………………………….
跨域不一定会有跨域问题。因为跨域问题是浏览器对于ajax请求的一种安 全限制:一个页面发起的ajax请求,只能是从当前页同域名的路径,这能有效 的阻止跨站攻击。 因此:跨域问题是针对ajax的一种限制。 但是这却给我们的开发带来了不变,而且在实际生成环境中,肯定会有很多 台服务器之间交互,地址和端口都可能不同,怎么办?
10 5 7 解决跨域问题的方案…………………………………………………………………………………
目前比较常用的跨域解决方案有 3 种:
1 .Jsonp: 最早的解决方案,使利用script标签可以跨域的原理实现。 缺点:需要服务的支持,只能发起GET请求。 2 .nginx反向代理: 利用nginx反向代理把跨域置成不跨域,支持各种 请求方式。 缺点:需要在nginx进行额外配置,语义不清晰。 3 .CORS: 规范化的跨域请求解决方案,安全可靠。 优点:在服务端进行控制是否允许跨域,可自定义规则。支持各种请求
方式。
缺点:会产生额外的请求。
我们这里会采用cors的跨域方案。
10 5 8 CORS………………………………………………………………………………………………………..
5. 8. 1 什么使CORS
CORS是一个W 3 C标准,全称是"跨域资源共享”(Cross-originresource sharing)。它允许浏览器向跨源服务器,发出 XMLHttpRequest 请求,从而 克服了AJAX只能同源使用的限制。CORS需要浏览器和服务器同时支持。目前, 所有浏览器都支持该功能,IE浏览器不能低于IE 10 。 浏览器端 : 目前,所有浏览器都支持该功能(IE 10 以下不行)。整个CORS通信过 程,都是浏览器自动完成,不需要用户参与。 服务器端 : CORS通信与AJAX没有任何差别,因此你不需要改变以前的业务逻辑。 只不过,浏览器会在请求中携带一些头信息,我们需要以此判断是否运行其 跨域,然后在响应头中加入一些信息即可。这一般通过过滤器完成即可。
5. 8. 2 CORS原理
浏览器会将ajax请求分为两类,其处理方案略有差异:简单请求、特殊请 求。 简单请求
只要同时满足以下两大条件,就属于简单请求:
1. 请求方法是以下三种方法之一:
HEAD
GET
POST
2. HTTP的头信息不超出以下几种字段:
Accept Accept-Language Content-Language Last-Event-ID Content-Type:只限于三个值 application/x-www-form-urlencoded 、 multipart/form-data、text/plain 当浏览器发现发现的ajax请求是简单请求时,会在请求头中携带一个字段: Origin
Origin中会指出当前请求属于哪个域(协议+域名+端口)。服务会根据这个值 决 定是否允许其跨域。如果服务器允许跨域,需要在返回的响应头中携带下面 信息
Access-Control-Allow-Origin:可接受的域,是一个具体域名或者*,代表任 意。 Access-Control-Allow-Credentials:是否允许携带cookie,默认情况下,cors 不会携带cookie,除非这个值是 true。 注意: 如果跨域请求要想操作cookie,需要满足 3 个条件: 服务的响应头中需要携带Access-Control-Allow-Credentials并且为true。 浏览器发起ajax需要指定withCredentials为true。 响应头中的Access-Control-Allow-Origin一定不能为*,必须是指定的域名。 特殊请求 不符合简单请求的条件,会被浏览器判定为特殊请求,,例如请求方式为PUT。 预检请求 特殊请求会在正式通信之前,增加一次HTTP查询请求,称为"预检"请求 (preflight)。浏览器先询问服务器,当前网页所在的域名是否在服务器的许可 名单之中,以及可以使用哪些HTTP动词和头信息字段。只有得到肯定答复,浏 览器才会发出正式的 XMLHttpRequest 请求,否则就报错。一个“预检”请 求的样板:
与简单请求相比,除了Origin以外,多了两个头:
Access-Control-Request-Method:接下来会用到的请求方式,比如PUT。
Access-Control-Request-Headers:会额外用到的头信息。 预检请求的响应 服务的收到预检请求,如果许可跨域,会发出响应:
除了Access-Control-Allow-Origin 和 Access-Control-Allow-Credentials 以外,这里又额外多出 3 个头: Access-Control-Allow-Methods:允许访问的方式。 Access-Control-Allow-Headers:允许携带的头。 Access-Control-Max-Age:本次许可的有效时长,单位是秒,过期之 前的ajax请求就无需再次进行预检了。 如果浏览器得到上述响应,则认定为可以跨域,后续就跟简单请求的处理是 一样的了。
5. 8. 3 实现
虽然原理比较复杂,但是前面说过: 浏览器端都有浏览器自动完成,我们无需操心服务端可以通过拦截器统一实 现,不必每次都去进行跨域判定的编写。
在实现代码我们需要做的事情如下:
创建cors的配置信息 允许访问的域 是否允许发送cookie 允许的请求方式 允许的头信息 访问有效期 添加映射路径,我们拦截一切请求。 返回新的CORSFilter。 事实上,SpringMVC已经帮我们写好了CORS的跨域过滤器:CorsFilter, 内部已经实现了刚才所讲的判定逻辑,我们直接用就好了。
10 5 9 为什么图片地址需要使用另外的url?………………………………………………………
图片不能保存在服务器内部,这样会对服务器产生额外的加载负担。
一般静态资源都应该使用独立域名,这样访问静态资源时不会携带一些不必
要的cookie,减小请求的数据量。
10 5 10 消息中间件………………………………………………………………………………………………
10. 5. 10. 1 什么是消息中间件
消息队列已经逐渐成为企业IT系统内部通信的核心手段。它具有低耦合、 可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要
手段之一。当今市面上有很多主流的消息中间件,如老牌的ActiveMQ、 RabbitMQ,炙手可热的Kafka,阿里巴巴自主开发RocketMQ等。
10. 5. 10. 2 消息中间件的组成
Broker 消息服务器,作为server提供消息核心服务。
Producer 消息生产者,业务的发起方,负责生产消息传输给broker。
Consumer 消息消费者,业务的处理方,负责从broker获取消息并进行业务逻辑处理。
Topic 主题,发布订阅模式下的消息统一汇集地,不同生产者向topic发送消息, 由MQ服务器分发到不同的订阅者,实现消息的广播。
Queue 队列,PTP模式下,特定生产者向特定queue发送消息,消费者订阅特定 的queue完成指定消息的接收。
Message 消息体,根据不同通信协议定义的固定格式进行编码的数据包,来封装业务 数据,实现消息的传输。
10. 5. 10. 3 消息中间件模式分类
点对点
PTP点对点:使用queue作为通信载体。
说明:
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并 且消费消息。 消息被消费以后,queue中不再存储,所以消息消费者不可能消费到已 经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有 一个消费者可以消费。 发布/订阅 Pub/Sub发布订阅(广播):使用topic作为通信载体。
说明:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅) 消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。 queue实现了负载均衡,将producer生产的消息发送到消息队列中,由多 个消费者消费。但一个消息只能被一个消费者接受,当没有消费者可用时,这个 消息会被保存直到有一个可用的消费者。 topic实现了发布和订阅,当你发布一个消息,所有订阅这个topic的服务 都能得到这个消息,所以从 1 到N个订阅者都能得到一个消息的拷贝。
10. 5. 10. 4 消息中间件的优势
系统解耦 交互系统之间没有直接的调用关系,只是通过消息传输,故系统侵入性不强, 耦合度低。 提高系统响应时间 例如原来的一套逻辑,完成支付可能涉及先修改订单状态、计算会员积分、 通知物流配送几个逻辑才能完成;通过MQ架构设计,就可将紧急重要(需要
立刻响应)的业务放到该调用方法中,响应要求不高的使用消息队列,放到MQ
队列中,供消费者处理。
为大数据处理架构提供服务
通过消息作为整合,大数据的背景下,消息队列还与实时处理架构整合,为
数据处理提供性能支持。
Java消息服务——JMS Java消息服务(JavaMessageService,JMS)应用程序接口是一个Java 平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分 布式系统中发送消息,进行异步通信。 JMS中的P 2 P和Pub/Sub消息模式:点对点(pointtopoint, queue) 与发布订阅(publish/subscribe,topic)最初是由JMS定义的。这两种模式 主要区别或解决的问题就是发送到队列的消息能否重复消费(多订阅)。
10. 5. 10. 5 消息中间件常用协议
AMQP协议 AMQP即AdvancedMessageQueuingProtocol,一个提供统一消息服 务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息 的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/ 中间件不同产品,不同开发语言等条件的限制。 优点: 可靠、通用。 MQTT协议 MQTT(MessageQueuingTelemetryTransport,消息队列遥测传输)
是IBM开发的一个即时通讯协议,有可能成为物联网的重要组成部分。该协议
支持所有平台,几乎可以把所有联网物品和外部连接起来,被用来当做传感器和
致动器(比如通过Twitter让房屋联网)的通信协议。 优点: 格式简洁、占用带宽小、移动端通信、PUSH、嵌入式系统。 STOMP协议 STOMP(StreamingTextOrientatedMessageProtocol)是流文本定向 消息协议,是一种为MOM(MessageOrientedMiddleware,面向消息的中间 件)设计的简单文本协议。STOMP提供一个可互操作的连接格式,允许客户端与 任意STOMP消息代理(Broker)进行交互。 优点: 命令模式(非topic\queue模式)。 XMPP协议 XMPP(可扩展消息处理现场协议,ExtensibleMessagingandPresence Protocol)是基于可扩展标记语言(XML)的协议,多用于即时消息(IM)以 及在线现场探测。适用于服务器之间的准即时操作。核心是基于XML流传输, 这个协议可能最终允许因特网用户向因特网上的其他任何人发送即时消息,即使 其操作系统和浏览器不同。 优点: 通用公开、兼容性强、可扩展、安全性高,但XML编码格式占用带宽大。 其他基于TCP/IP自定义的协议 有些特殊框架(如:Redis、kafka、zeroMq等)根据自身需要未严格遵循 MQ规范,而是基于TCP\IP自行封装了一套协议,通过网络socket接口进行 传输,实现了MQ的功能。
10 5 11 RabbitMQ………………………………………………………………………………………………
10. 5. 11. 1 什么是RabbitMQ?
RabbitMQ是一款开源的,Erlang编写的,基于AMQP协议的,消息中间 件。
10. 5. 11. 2 为什么要使用RabbitMQ?Rabbit有什么优点?
解耦、异步、削峰。
10. 5. 11. 3 RabbitMQ有什么缺点?
降低了系统的稳定性:本来系统运行好好的,现在你非要加入个消息队列进 去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性会降低。
增加了系统的复杂性:加入了消息队列,要多考虑很多方面的问题,比如: 一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此, 需要考虑的东西更多,复杂性增大。
10. 5. 11. 4 RabbitMQ的工作模式?
7 种 , 1 .简单模式 2 .工作者模式 3 .广播模式 4 .路由模式 5 .通配符模式 6 .RPC 7 .消息确认模式
简单模式 一个生产者,一个消费者。 work模式(常用)
一个生产者,多个消费者,每个消费者获取到的消息唯一。
订阅模式
一个生产者发送的消息会被多个消费者获取。
路由模式
发送消息到交换机并且要指定路由key ,消费者将队列绑定到交换机时需 要指定路由key。 topic模式(常用) 将路由键和某模式进行匹配,此时队列需要绑定在一个模式上,“#”匹配 一个词或多个词,“*”只匹配一个词。
10. 5. 11. 5 如何保证RabbitMQ高可用?
搭建RabbitMQ集群。一般小型,中型项目搭建 3 台够用了。数据量在 500 万内。
10. 5. 11. 6 如何保证RabbitMQ消息不被重复消费?
先说为什么会重复消费:正常情况下,消费者在消费消息的时候,消费完毕 后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将 该消息从消息队列中删除。
但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列 不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
针对以上问题,一个解决思路是:保证消息的唯一性,就算是多次传输,不 要让消息的多次消费带来影响,保证消息等幂性。
比如:在写入消息队列的数据做唯一标示,消费消息时,根据唯一标识判断
是否消费过。
10. 5. 11. 7 如何保证RabbitMQ消息可靠传输?
消息不可靠的情况可能是消息丢失,劫持等原因。丢失又分为:生产者丢失 消息、消息列表丢失消息、消费者丢失消息。 生产者丢失消息 从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm 模式来确保生产者不丢消息。 transaction模式:发送消息前,开启事务(channel.txSelect()),然后发送 消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()), 如果发送成功则提交事务(channel.txCommit())。然而,这种方式有个缺点, 吞吐量下降。 confirm模式:一旦channel进入confirm模式,所有在该信道上发布的消 息都将会被指派一个唯一的ID(从 1 开始),一旦消息被投递到所有匹配的队 列之后。RabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就 使得生产者知道消息已经正确到达目的队列了.如果rabbitMQ没能处理该消 息,则会发送一个Nack消息给你,你可以进行重试操作。 消息队列丢数据 消息持久化。处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。 这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后, 再给生产者发送一个Ack信号。这样,如果消息持久化磁盘之前,rabbitMQ阵
亡了,那么生产者收不到Ack信号,生产者会自动重发。那么如何持久化呢? 这里顺便说一下吧,其实也很容易,就下面两步:
- 将queue的持久化标识durable设置为true,则代表是一个持久的队列。
- 发送消息的时候将deliveryMode= 2 。 这样设置以后,即使rabbitMQ挂了,重启后也能恢复数据。 消费者丢失消息 消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即 可!消费者在收到消息之后,处理消息之前,会自动回复RabbitMQ已收到消 息。如果这时处理消息失败,就会丢失该消息。 解决方案:处理消息成功后,手动回复确认消息。
10. 5. 11. 8 如何保证RabbitMQ消息的顺序性?
单线程消费保证消息的顺序性。对消息进行编号,消费者处理消息是根据编 号处理消息。 5. 11. 9 如何确保消息正确地发送至RabbitMQ?如何确保消息接收 方消费了消息? 发送方确认模式 将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消 息都会被指派一个唯一的ID。一旦消息被投递到目的队列后,或者消息被写入 磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。 如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(not acknowledged,未确认)消息。发送方确认模式是异步的,生产者应用程序在
等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者
应用程序的回调方法就会被触发来处理确认消息。
接收方确认机制
消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同
操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。 这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是 否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer 足够长的时间来处理消息。保证数据的最终一致性。 下面罗列几种特殊情况 如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ会 认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消息重 复消费的隐患,需要去重)。 如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认 为该消费者繁忙,将不会给该消费者分发更多的消息。
10. 5. 11. 10 RabbitMQ消息堆积处理
- 增加消费者的处理能力(例如优化代码),或减少发布频率。
- 考虑使用队列最大长度限制。
- 给消息设置年龄,超时就丢弃。
- 默认情况下,rabbitmq消费者为单线程串行消费,设置并发消费两个 关键属性concurrentConsumers和prefetchCountoncurrentConsumers设 置的是对每个listener在初始化的时候设置的并发消费者的个数,
prefetchCount是每次一次性从broker里面取的待消费的消息的个数。 11. 建立新的queue,消费者同时订阅新旧queue,采用订阅模式。 12. 生产者端缓存数据,在mq被消费完后再发送到mq,打破发送循环条 件,设置合适的qos值,当qos值被用光,而新的ack没有被mq接收时,就 可以跳出发送循环,去接收新的消息;消费者主动block接收进程,消费者感受 到接收消息过快时主动block,利用block和unblock方法调节接收速率,当 接收线程被block时,跳出发送循环。
10. 5. 11. 11 RabbitMQ消息丢失解决方案
消息持久化
Exchange 设置持久化:durable:true。
ueue设置持久化;Message持久化发送。
ACK确认机制
消息发送确认。
息接收手动确认ACK。
10. 5. 11. 12 RabbitMQ宕机了怎么处理
RabbitMQ提供了持久化的机制,将内存中的消息持久化到硬盘上,即使重 启RabbitMQ,消息也不会丢失。 持久化队列和非持久化队列的区别是,持久化队列会被保存在磁盘中,固定 并持久的存储,当Rabbit服务重启后,该队列会保持原来的状态在RabbitMQ 中被管理,而非持久化队列不会被保存在磁盘中,Rabbit服务重启后队列就会
消失。
非持久化比持久化的优势就是,由于非持久化不需要保存在磁盘中,所以使
用速度就比持久化队列快。即是非持久化的性能要高于持久化。
而持久化的优点就是会一直存在,不会随服务的重启或服务器的宕机而消
失。
10. 5. 11. 13 RabbitMQ的集群
Rabbitmq有 3 种模式,但集群模式有 2 中,详情如下: 单一模式 即单机情况不做集群,就单独运行一个rabbitmq而已。 普通模式 默认模式,以两个节点(rabbit 01 、rabbit 02 )为例来进行说明。对于Queue 来说,消息实体只存在于其中一个节点rabbit 01 (或者rabbit 02 ),rabbit 01 和rabbit 02 两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit 01 节点的Queue后,consumer从节点消费时,RabbitMQ会临时在rabbit 01 、 rabbit 02 间进行消息传输,把A中的消息实体取出并经过B发送给consumer。 所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列, 要在多个节点建立物理Queue。否则无论consumer连rabbit 01 或rabbit 02 , 出口总在rabbit 01 ,会产生瓶颈。当rabbit 01 节点故障后,rabbit 02 节点无法 取到rabbit 01 节点中还未消费的消息实体。如果做了消息持久化,那么得等 rabbit 01 节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢 失的现象。
镜像模式
把需要的队列做成镜像队列,存在与多个节点属于RabbitMQ的HA案。 该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会 主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作 用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进 入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求 较高的场合中适用。
10. 5. 11. 14 如何解决分布式事务问题?
- 2 PC:两阶段提交 执行阶段: 当创建订单时,向所有微服务发送消息,可以开始执行了,执行成功后,不直接 提交,而是返回一个消息告诉我,执行成功还是执行失败。 第二阶段: 如果所有人都执行成功,再发一个消息,你们可以提交了; 如果第一阶段有人执行失败,你就告诉所有人都回滚。 缺点:当锁定的表很多时,性能差。 3 .TCC:补偿性事务(一般采用)try-confirm-concel 每个服务执行完后都提交,集中返回给自己,如果都执行成功了那就不管 如果提交失败,就采用失败服务的补偿方法去补偿,但若补偿方法也失败,那你还 需要进行重试写重试方法或者人工介入。 优缺:解决了性能问题,但是业务复杂,写一个事务还需要写补偿方法。
异步确保:利用mq实现分布式事务。
10. 5. 10. 6 常见的消息中间
RocketMQ 阿里系下开源的一款分布式、队列模型的消息中间件,原名Metaq, 3. 0 版 本名称改为RocketMQ,是阿里参照kafka设计思想使用java实现的一套mq。 同时将阿里系内部多款mq产品(Notify、metaq)进行整合,只维护核心功 能,去除了所有其他运行时依赖,保证核心功能最简化,在此基础上配合阿里上 述其他开源产品实现不同场景下mq的架构,目前主要多用于订单交易系统。 RabbitMQ 使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP, XMPP,SMTP,STOMP,也正是如此,使的它变的非常重量级,更适合于企业级 的开发。同时实现了Broker架构,核心思想是生产者不会将消息直接发送给队 列,消息在发送给客户端时先在中心队列排队。对路由(Routing),负载均衡(Load balance)、数据持久化都有很好的支持。多用于进行企业级的ESB整合。 ActiveMQ Apache下的一个子项目。使用Java完全支持JMS 1. 1 和J 2 EE 1. 4 规范的 JMSProvider实现,少量代码就可以高效地实现高级应用场景。可插拔的传输 协议支持,比如:in-VM,TCP,SSL,NIO,UDP,multicast,JGroupsandJXTA transports。RabbitMQ、ZeroMQ、ActiveMQ均支持常用的多种语言客户端 C++、Java、.Net,、Python、 Php、 Ruby等。 Redis
使用C语言开发的一个Key-Value的NoSQL数据库,开发维护很活跃,虽 然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可 以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队 操作,各执行 100 万次,每 10 万次记录一次执行时间。测试数据分为 128 Bytes、 512 Bytes、 1 K和 10 K四个不同大小的数据。实验表明:入队时,当数据比较小 时Redis的性能要高于RabbitMQ,而如果数据大小超过了 10 K,Redis则慢的 无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ 的出队性能则远低于Redis。 Kafka Apache 下的一个子项目,使用 scala实现的一个高性能分布式 Publish/Subscribe消息队列系统。
10 5 12 图片上传…………………………………………………………………………………………………
本地存储-业务思路 用户在页面选择图片点击上传,到图片微服务,图片微服务解析请求,复制 图片并保存到Nginx静态资源下(html)。同时生成此图片的访问路径(url) 保存到数据库。页面通过url访问Nginx下的图片。
阿里云对象存储OSS-业务思路 用户在页面选择图片点击上传,首先访问后台,获取访问OSS的签名,请 求带着OSS的签名将图片上传到OSS。OSS成功保存图片后会返回该图片的公 共访问路径(url),将此路径保存到数据。 页面通过url访问OSS上的图片。 什么是分布式文件系统
分布式文件系统(DistributedFileSystem)是指文件系统管理的物理存储 资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。 通俗来讲 传统文件系统管理的文件就存储在本机。 分布式文件系统管理的文件存储在很多机器,这些机器通过网络连接,要被 统一管理。无论是上传或者访问文件,都需要通过管理中心来访问。 常见的分布式文件系统有谷歌的GFS、HDFS(Hadoop)、TFS(淘宝)、 FastDFS(淘宝)等。 不过,企业自己搭建分布式文件系统成本较高,对于一些中小型企业而言, 使用云上的文件存储,是性价比更高的选择。 OSS简介 阿里云对象存储服务(ObjectStorageService,简称 OSS),是阿里云提 供的海量、安全、低成本、高可靠的云存储服务。其数据设计持久性不低于 99. 999999999 %,服务设计可用性不低于 99. 99 %。具有与平台无关的RESTful API接口,您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。 您可以使用阿里云提供的API、SDK接口或者OSS迁移工具轻松地将海量 数据移入或移出阿里云OSS。数据存储到阿里云OSS以后,您可以选择标准类 型(Standard)的阿里云OSS服务作为移动应用、大型网站、图片分享或热点 音视频的主要存储方式,也可以选择成本更低、存储期限更长的低频访问类型 (InfrequentAccess)和归档类型(Archive)的阿里云OSS服务作为不经常 访问数据的备份和归档。 基本概念
存储类型(StorageClass) OSS提供标准、低频访问、归档三种存储类型,全面覆盖从热到冷的各种数 据存储场景。其中标准存储类型提供高可靠、高可用、高性能的对象存储服务, 能够支持频繁的数据访问;低频访问存储类型适合长期保存不经常访问的数据 (平均每月访问频率 1 到 2 次),存储单价低于标准类型;归档存储类型适合 需要长期保存(建议半年以上)的归档数据,在三种存储类型中单价最低。详情 请参见存储类型介绍。 存储空间(Bucket) 存储空间是您用于存储对象(Object)的容器,所有的对象都必须隶属于某 个存储空间。您可以设置和修改存储空间属性用来控制地域、访问权限、生命周 期等,这些属性设置直接作用于该存储空间内所有对象,因此您可以通过灵活创 建不同的存储空间来完成不同的管理功能。 对象/文件(Object) 对象是 OSS 存储数据的基本单元,也被称为OSS的文件。对象由元信息 (ObjectMeta),用户数据(Data)和文件名(Key)组成。对象由存储空间 内部唯一的Key来标识。对象元信息是一组键值对,表示了对象的一些属性, 比如最后修改时间、大小等信息。 地域(Region) 地域表示 OSS 的数据中心所在物理位置。您可以根据费用、请求来源等综 合选择数据存储的地域。详情请参见OSS已开通的Region。 访问域名(Endpoint ) Endpoint 表示OSS对外服务的访问域名。OSS以HTTPRESTfulAPI的形
式对外提供服务,当访问不同地域的时候,需要不同的域名。通过内网和外网访
问同一个地域所需要的域名也是不同的。具体的内容请参见各个Region对应的 Endpoint。 访问密钥(AccessKey) AccessKey,简称 AK,指的是访问身份验证中用到的AccessKeyId 和 AccessKeySecret。OSS通过使用AccessKeyId和AccessKeySecret对称加密 的方法来验证某个请求的发送者身份。AccessKeyId用于标识用户, AccessKeySecret是用户用于加密签名字符串和OSS用来验证签名字符串的密 钥,其中AccessKeySecret 必须保密。
10 5 13 FastDFS…………………………………………………………………………………………………..
FastDFS是一个开源的轻量级分布式文件系统,它可以对文件进行管理,功 能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大 容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、 视频网站等等。 **组成
- Storageserver(存储服务器)** Storageserver一般都是以组(group)为组织单位,一个组中有多个Storage server,数据互为备份(意味着每个Storageserver的内容是一致的,他们之间 没有主从之分),组的存储空间以组内最小的Storageserver为准,所以为了避 免浪费存储空间最好的话每个Storageserver的配置最好相同。 2. Trackerserver(调度服务器、追踪服务器)
Trackerserver主要负责管理所有的Storageserver和group,每个 storage在启动后会连接Tracker,告知自己所属的group等信息,并保持周期 性的心跳,tracker根据storage的心跳信息,建立group==>[storageserver list]的映射表。 流程
1 、选择trackerserver
当集群中不止一个trackerserver时,由于tracker之间是完全对等
的关系,客户端在upload文件时可以任意选择一个trakcer。
2 、选择存储的group
当tracker接收到uploadfile的请求时,会为该文件分配一个可以
存储该文件的group,支持如下选择group的规则:
1. Roundrobin,所有的group间轮询。
2. Specifiedgroup,指定某一个确定的group。
3. Loadbalance,剩余存储空间多多group优先。
4. 选择storageserver。
3 、选择storageserver
当选定group后,tracker会在group内选择一个storageserver 给客户端,支持如下选择storage的规则: 1 .Roundrobin,在group内的所有storage间轮询。 2 .Firstserverorderedbyip,按ip排序。 3 .First serverorderedbypriority,按优先级排序(优先级在 storage上配置)。 4 、选择storagepath 当分配好storageserver后,客户端将向storage发送写文件请求, storage将会为文件分配一个数据存储目录,支持如下规则:
- Roundrobin,多个存储目录间轮询。
- 剩余存储空间最多的优先。 5 、生成Fileid 选定存储目录之后,storage会为文件生一个Fileid,由storage serverip、文件创建时间、文件大小、文件crc 32 和一个随机数拼接而成, 然后将这个二进制串进行base 64 编码,转换为可打印的字符串。 6 、选择两级目录 当选定存储目录之后,storage会为文件分配一个fileid,每个存储 目录下有两级 256 * 256 的子目录,storage会按文件fileid进行两次hash (猜测),路由到其中一个子目录,然后将文件以fileid为文件名存储到该 子目录下。 7 、生成文件名 当文件存储到某个子目录后,即认为该文件存储成功,接下来会为
该文件生成一个文件名,文件名由group、存储目录、两级子目录、fileid、 文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。 FastDFS如何现在组内的多个storageserver的数据同步? 当客户端完成文件写至group内一个storageserver之后即认为文件上传 成功,storageserver上传完文件之后,会由后台线程将文件同步至同group 内其他的storageserver。后台线程同步参考的依据是每个 storageserver在 写完文件后,同时会写一份binlog,binlog中只包含文件名等元信息,storage 会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续 同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时 钟保持同步。
10 5 14 Nginx………………………………………………………………………………………………………
什么
Nginx是一个高性能的HTTP和反向代理服务器,及电子邮件代理服务器, 同时也是一个非常高效的反向代理、负载平衡。 作用 反向代理,将多台服务器代理成一台服务器。 负载均衡,将多个请求均匀的分配到多台服务器上,减轻每台服务器的压力, 提高服务的吞吐量。 动静分离,nginx可以用作静态文件的缓存服务器,提高访问速度。 优势 可以高并发连接( 5 万并发,实际也能支持 2 ~ 4 万并发)。
内存消耗少。
成本低廉。
配置文件非常简单。
支持Rewrite重写。 内置的健康检查功能。 节省带宽。 稳定性高。 支持热部署。 什么是反向代理 反向代理是指以代理服务器来接受internet上的连接请求,然后将请求,发 给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连 接的客户端,此时代理服务器对外就表现为一个反向代理服务器。 反向代理总结就一句话:代理端代理的是服务端。 什么是正向代理 一个位于客户端和原始服务器之间的服务器,为了从原始服务器取得内容, 客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转 交请求并将获得的内容返回给客户端。客户端才能使用正向代理。 正向代理总结就一句话:代理端代理的是客户端。 负载均衡 负载均衡即是代理服务器将接收的请求均衡的分发到各服务器中,负载均衡 主要解决网络拥塞问题,提高服务器响应速度,服务就近提供,达到更好的访问 质量,减少后台服务器大并发压力。
Nginx是如何处理一个请求的 首先,nginx在启动时,会解析配置文件,得到需要监听的端口与ip地址, 然后在nginx的master进程里面先初始化好这个监控的socket,再进行listen, 然后再fork出多个子进程出来, 子进程会竞争accept新的连接。此时,客户端 就可以向nginx发起连接了。当客户端与nginx进行三次握手,与nginx建立 好一个连接后,此时,某一个子进程会accept成功,然后创建nginx对连接的封 装,即ngx_connection_t结构体,接着,根据事件调用相应的事件处理模块,如 http模块与客户端进行数据的交换。最后,nginx或客户端来主动关掉连接, 到此,一个连接就寿终正寝了。 为什么Nginx性能这么高 得益于它的事件处理机制:异步非阻塞事件处理机制:运用了epoll模型, 提供了一个队列,排队解决。 对数据库只是采用了读写分离,并没有完全解决数据库的压力,那么有什么办法解 决? 如果数据库压力确实很大的情况下可以考虑数据库分片,就是将数据库 中表拆分到不同的数据库中保存。可以使用mycat中间件。 商品存入数据库怎么保证数据库数据安全? 对用户安全管理 用户操作数据库时,必须通过数据库访问的身份认证。删 除数据库中的默认用户,使用自定义的用户及高强度密码。 定义视图 为不同的用户定义不同的视图,可以限制用户的访问范围。通过视图机制把 需要保密的数据对无权存取这些数据的用户隐藏起来,可以对数据库提供一定程
度的安全保护。实际应用中常将视图机制与授权机制结合起来使用,首先用视图
机制屏蔽一部分保密数据,然后在视图上进一步进行授权。
数据加密 数据加密是保护数据在存储和传递过程中不被窃取或修改的
有效手段。
数据库定期备份
审计追踪机制
审计追踪机制是指系统设置相应的日志记录,特别是对数据更新、删除、修
改的记录,以便日后查证。日志记录的内容可以包括操作人员的名称、使用的密
码、用户的IP地址、登录时间、操作内容等。若发现系统的数据遭到破坏,可
以根据日志记录追究责任,或者从日志记录中判断密码是否被盗,以便修改密码,
重新分配权限,确保系统的安全。
10 6 商品搜索(ElasticSearch,MQ)………………………………………………………………………………
10 6 1 业务思路……………………………………………………………………………………………………
搜索模块在我们项目中也是比较重要的一个模块,因为商品的搜索是每个用
户在购物消费产生之前不可避免的行为,而且每个用户的搜索方式、需求也不一
样,比如有的用户在情人节想买个礼物给女朋友,但是他不知道买什么?这个时
候他就会按照“情人节礼物 女”这样的条件来进行搜索,系统会自动匹配符合
关键字条件的商品展示给用户;再比如有的用户想给长辈买一个手机,但是他不
知道具体哪些品牌会有老人机,所以当他输入“老人机”这个关键字时,系统会
自动匹配展示所有符合条件的商品,所以说了这么多,想要完成商品的搜索都离
不开非常关键的点,关键字。
中文跟英文不一样,他的组合方式有很多种,比如中国人,它可以拆分成“中、
国、中国、中国人、国人、人中”,如何合理的分词对我们的商品搜索至关重要。
另外搜索的请求如果都走数据库的话,很可能会将整个应用的性能给拖垮了,所
以我们单独搭建了一个搜索服务器来试下搜索服务,那至于采用什么搜索引擎.
在起初技术选型的时候我们考虑的是solr和elasticSearch,最终选择的是使用 ES来进行实现搜索的。 因为Solr在建立索引时,搜索效率下降,实时索引搜 索效率不高,当单纯的对已有数据进行搜索时,Solr更快,当实时建立索引时,Solr 会产生io阻塞,查询性能较差,ElasticSearch具有明显的优势,随着数据量的增 加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化,综上所述, Solr的架构不适合实时搜索的应用所以选在了ElasticSearch. 搜索功能这块儿分为三大部分, 一部分是索引库数据的封装数据, 另一部分 是用户搜索, 第三部分是要考虑动态同步索引库. 第一部分,Es索引库封装数据, 要考虑如下问题:
( 1 ) Es索引库存放哪些数据? 在从数据库中导入 es中,因为涉及到多张表,所以我们需要自定义一个商 品类实例,用来包含 此商品的 spu 的所有信息。
一共有两种,一种是用来页面渲染的数据,展示给用户看的;另一种是用来 搜索过滤的数据,方便用户搜索。(例如:用户可以直观能看到的:图片、价格、 标题(SKU数据(用来展示的数据))和 副标题(SPU);暗藏的数据有spu 的 id,sku 的 id(用来做商品详情页和用来显示商品的过滤条件), 过滤条 件的封装: 规格, 品牌等字段.)
①需要用户检索的信息(商品分类、品牌、规格、标题), 这里封装成一个
all字段作为全文检索字段. 用户输入关键字后先来all字段中匹配, 根据匹配到 的查询出用户想要的数据. 要是不封装成all字段, 需要从全文中进行匹配, 这样 会降低Es的性能, 降低用户体验感. ②spu的id(我们一般会将 id和 es 中的 _id 保持一致,方便以后业务 的处理。例如 商品的下架需要删除 es库中记录的数据) ③品牌的id, ④分类的id ⑤sku 的相关信息(是个 json 数组的字符串,包含 skuId、price、image、 title), 因为每一个 spu 对应多个 sku,所以 sku的数据需要存放到一个List 集合中,但是 es只支持 json 格式的数据,所以我们需要把这个 List 集合转 换为 json 数据字符串。每个 sku 包含 skuId、price、image、title。
⑥商品的价格, 价格也是一个数组,但是采用的是 set 接口,这样可以保证 price 的单一性. 首先价格显示就不正确,我们数据库中存放的是以分为单位,所以这里要格 式化。好在我们之前common.js中定义了工具类,可以帮我们转换。但是报错, 因为在Vue范围内使用任何变量,都会默认去Vue实例中寻找,我们使用ly(当 然这里说的时候要整理成自己的项目名缩写, 别就说是ly),但是Vue实例中没 有这个变量。所以解决办法就是自定义工具对象ly:把ly记录到Vue实例。 ⑦商品的规格参数, 对于每一类商品,都有不同的规格参数,所以我们要采 用的是 map结构来存取,在 es 中,存储时,会把 属性的名称 +”."+key 作 为 es中的列名.
⑧商品的上架时间
⑨商品的促销信息
我们不可能一次性查出所有数据添加到es中,所以就需要多次调用商品微 服务去分页查询出 spu 的相关信息。我们就可以写一个 死循环 不断的去远程 调用。 死循环的终止条件有两个:① 没有分页数据 ②取回的分页数据的大小 < 我们一次要取出的数据大小 第二部分,搜索数据, 搜索功能具体实现从以下三点考虑: 1 .关键字搜索: 将页面提交的关键字提交给后台,再使用springdataes 提供的模板类 esTempalte完成搜索。其中对商品的搜索是基于构建的all字段完成的匹配查 询。All字段中包含了商品的名称+品牌名称+三级分类。 2 .过滤条件查询: 关键字生成搜索结果后还提供了过滤条件的添加,过滤条件的生成是根据搜 索结果动态展示的,因为不同的商品因为分类的不同对应的参数也不同,过滤条 件是在关键字搜索的结果集中,通过聚合查询获取过滤查询条件。过滤条件包含 分类,品牌,以及商品的规格参数。其中规格名称和规格值都是动态变化的。规 格参数的展示是在用户点击某一个分类条件时,查询该分类对应用于搜索的规格 名称以及规格值。在关键字搜索的基础上再点击过滤条件进行进一步的筛选商品 数据。其中对商品的搜索是基于构建的all字段完成的匹配查询。All字段中包含 了商品的名称+品牌名称+三级分类。
es搜索商品时,使用的 匹配查询(match),会把查询条件进行分词,然后 进行查询,多个词条之间默认关系是OR,所以要设置多个词条之间的关系为 and。
①先创建原生 es查询器,bulider 各种查询条件。是由springDataElasticSearch 提供的.
②再有 spring 封装的 ElasticsearchTemplate 发送 builder条件到 es 服务器中,并将查询出的结果返回.
③过滤条件的显示需要根据用户的搜索条件进行过滤,要建立 bool 查询, 来构建过滤条件.
④页面上显示的过滤项,需要 term 词条精确匹配,进行聚合(相当于数据 库的分组),显示和用户搜索情况一致的过滤项。(在搜索条件基础上,对搜索 结果聚合).
⑤对于页面上会显示两部分数据,一部分是商品的信息,一部分是商品的过 滤条件信息。我们会发两次请求,第二次是 ajax 请求,去查询过滤项信息。
第三部分, 商品上下架时同步索引库: 商品在进行上下架操作之后需要对商品的展示数据和商品搜索的索引库进 行修改,有两种方案都能实现三个微服务的数据同步,方案一就是在商品微服务 完成上下架商品业务后,加入修改索引库和商品展示的静态页,方案二是搜索服 务和静态页服务对外提供操作索引库和静态页的接口,商品微服务在商品上下架 后调用接口。但是这两种方案有一个严重的问题就是代码的耦合性太高,违背了
微服务的独立原则,违背了开闭原则。所以我用到了消息队列。选用的MQ是
RabbitMQ(为什么选用Rabbit?还有其他的MQ产品吗?)。当商品微服务 做了商品上下架操作后,无需操作索引库和静态页面,只需要发送一条消息,也 不用关心消息被谁接受了,而搜索服务和静态页服务接受消息,分别处理索引库 和静态页面。而以后如果有其他微服务需要依赖商品微服务的数据是,同样监听 消息即可,商品微服务无需更改代码。
10 6 2 ElasticSearch…………………………………………………………………………………………….
10. 6. 2. 1 概念
ElasticSearch是一个分布式的RESTful风格的搜索和数据分析引擎。它是 基于Lucene的,提供了具有HTTPWeb界面和无架构JSON文档的分布式, 多租户能力的全文搜索引擎。Elasticsearch是用Java开发的,根据Apache许 可条款作为开源发布。
10. 6. 2. 2 作用
- 分布式的搜索引擎和数据分析引擎。 2 .全文检索,结构化检索,数据分析。 3 .对海量数据进行近实时的处理。
10. 6. 2. 3 优势
1 .自动维护数据的分布到多个节点的索引的建立,还有搜索请求分布到多个节点 的执行。
2 .自动维护数据的冗余副本,保证了一旦机器宕机,不会丢失数据。
3 .装了更多高级的功能,例如聚合分析的功能,基于地理位置的搜索。
10. 6. 2. 4 ElasticSearch中的倒排索引是什么?
倒排索引是搜索引擎的核心。搜索引擎的主要目标就是在查找发生搜索条件 的文档时提供快速搜索。倒排索引也常被称为反向索引、置入档案或反向档案, 是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中 的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可 以根据单词快速获取包含这个单词的文档列表。
10. 6. 2. 5 ElasticSearch中的集群、节点、索引、文档、类型是什么?
群集 是一个或多个节点(服务器)的集合,它们共同保存您的整个数,并 提供跨所有节点的联合索引和搜索功能。群集由唯一名称标识,默认情况下为 “elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该 节点只能是群集的一部分。
节点 是属于集群一部分的单个服务器。它存储数据并参与群集索引和搜索 功能。
索引 就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索 引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。 MySQL=> 数据库,ElasticSearch=>索引。
文档 类似于关系型数据库中的一行。不同之处在于索引中的每个文档可以
具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。MySQL =>Databases=>Tables=>Columns/RowsElasticSearch=>Indices =>Types=> 具有属性的文档。
类型 是索引的逻辑类别/分区,其语义完全取决于用户。
10. 6. 3. 6 ElasticSearch中的分片是什么?
在大多数环境中,每个节点都在单独的盒子或虚拟机上运行。 索引 - 在Elasticsearch中,索引是文档的集合。 分片 -因为Elasticsearch是一个分布式搜索引擎,所以索引通常被分割成 分布在多个节点上的被称为分片的元素。
10. 6. 3. 7 ElasticSearch中的副本是什么?
一个索引被分解成碎片以便于分发和扩展。副本是分片的副本。一个节点是 一个属于一个集群的ElasticSearch的运行实例。一个集群由一个或多个共享相 同集群名称的节点组成。
10. 6. 3. 8 ElasticSearch查询方式有哪几种?
1. 查询所有(match_all)
2. 匹配查询(match)
会把查询条件进行分词,然后进行查询,多个词条之间默认关系是OR。
1. 词条查询(term)
用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词
的字符串。
2. 布尔组合(bool)
各种其它查询通过 must (与)、 must_not(非)、should(或)
的方式进行组合。
3. 范围查询(range)
找出那些落在指定区间内的数字或者时间。
4. 模糊查询(fuzzy)
fuzzy 查询是 term` 查询的模糊等价。它允许用户搜索词条与实际词
条的拼写出现偏差,但是偏差的编辑距离不得超过 2 。
10 6 3 Solr……………………………………………………………………………………………………………
10. 6. 3. 1 概念
Solr是基于Lucene实现的搜索引擎,扩展性良好,并且提供了完整的集群 方案和索引库优化方案。
10. 6. 3. 2 优势
1 .solr是将整个索引操作功能封装好了的搜索引擎系统(企业级搜索引擎产 品)。 2 .solr可以部署到单独的服务器上(WEB服务),它可以提供服务,我们的业 务系统就只要发送请求,接收响应即可,降低了业务系统的负载。 3 .solr部署在专门的服务器上,它的索引库就不会受业务系统服务器存储空 间的限制。 4 .solr支持分布式集群,索引服务的容量和能力可以线性扩展。
10. 6. 3. 3 工作机制
Solr索引的实现方法很简单
-
用POST方法向Solr服务器发送一个描述Field及其内容的XML文档。
-
Solr根据xml文档添加、删除、更新索引。
-
Solr搜索只需要发送HTTPGET请求,然后对 Solr返回Xml、Json等 格式的查询结果进行解析,组织页面布局。
-
PS:Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理 界面可以查询Solr的配置和运行情况。
10 6 4 Ik分词器……………………………………………………………………………………………………
10. 6. 4. 1 什么是分词
把一段中文或者别的划分成一个个的关键字。搜索时候会将用户的搜索关键 字进行分词,会把数据库中或者索引库中的数据进行分词,然后对两者进行一一 匹配操作。
10. 6. 4. 2 为什么要使用Ik分词器?
默认的中文分词会将每个字看成一个词,比如"中国的花"会被分为"中”,” 国”,“的”,“花”,这显然是不符合要求的,所以我们需要安装中文分词器ik来 解决这个问题。
10. 6. 4. 3 Ik分词器的原理?
Ik分词器提供了两个分词算法:ik_smart 和 ik_max_word。其中 ik_smart 为最少切分,ik_max_word为最细粒度划分。 ik_smart
ik_max_word
10. 6. 4. 4 ElasticSearch集成Ik分词器
先将其解压,将解压后的文件夹重命名为ik。
将ik文件夹拷贝到elasticsearch/plugins目录下。
重新启动,即可加载Ik分词器。
10 6 6 ElasticSearch和Solr对比区别是什么?…………………………………………………….
1 .es基本是开箱即用,非常简单。而Solr安装略微复杂一些。 2 .es自身带有分布式协调管理功能。而Solr 需利用 Zookeeper 进行分布 式管理。 3 .Elasticsearch 只支持json文件格式。而Solr 支持更多格式的数据,比 如JSON、XML、CSV。 4 .es本身更注重于核心功能,高级功能多由第三方插件提供,例如图形化 界面需要kibana友好支持。而 Solr官方提供的功能更多。 5 .es建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜 索。Solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应 用。Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的 实时搜索应用。 6 .es相对开发维护者较少,更新太快,学习使用成本较高。Solr比较成熟, 有一个更大,更成熟的用户、开发和贡献者社区。
10 7 页面静态化(Thymeleaf,MQ)………………………………………………………………………………
10 7 1 业务思路……………………………………………………………………………………………………
在设计详情展示模块的时候,我们经过反复的推敲,选出了三种展示方案:
第一种: 随着滚动,发起异步请求,获取详情数据,这种方案一些大型的电
商网站都在使用,但这一般都需要大型的数据库。根据我们项目的实际情况,这
个方案不符合我们的要求。
第二种: 一次性把需要的数据全部查询出来,把查询到数据保存在redis中, 用户进行详情查看的时候,把商品信息全部展示,但是这种方案存在一个很大的 问题,就是以后随着上架的商品越来越多,Redis里面的数据就会变得非常庞大, Redis对海量数据的存储并不能很好地支持。所以这个方案也被pass掉了。 第三种: 把要展示的详情信息,放在静态html页面中,在商品上架的时候, 要把详细信息同步到索引库,同时生成静态页面,根据商品的id来区分静态页 面(id.html)我们再使用nginx的反向代理,当用户查看商品详情的时候,会 根据查看商品的id去寻找到nginx的html文件夹中对应商品的静态页面,实 现商品的详情展示。 结合我们项目的实际情况,我们选择了第三种方案,因为这对服务器,数据 库的要求也没那么大。 对于电商网站而言,必须要考虑的就是服务的高并发问题,因此要尽可能减 少服务端压力,提高服务响应速度。 页面静态化:顾名思义,就是把本来需要动态渲染的页面提前渲染完成,生 成静态的HTML,当用户访问时直接读取静态HTML,提高响应速度,减轻服
务端压力。我们使用模板引擎技术——Thymeleaf。类似的模板渲染技术: Freemarker、Velocity复制页面静态模板到当前项目resource目录下的 template中,我们需要提供Model数据,完成页面渲染。(可以详细讲 Thymeleaf技术) 使用 thymeleaf 静态化技术时,数据填充使用的是 ${} 。浏览器发送查看 商品详情页的信息的请求时,需要我们 进行远程调用商品微服务,查询到商品 的 spu,sku,商品分类,以及规格参数等信息动态渲染到 商品详情页,然后 在返回给浏览器。这就相当于以前的传统方式,页面在服务器端渲染成功后,返 回给浏览器,无形中增加了服务器的压力且响应时间长,用户体验查。所以我们 要提前动态的生成商品详情静态页,部署在 nginx 中,所以我们要使用 商品 详情页模板 和 thymeleaf 提供的模板语言,使用流的方式将静态页面生成到 一个目录中。(可以去讲nginx技术) 这个页面的静态化的生成依赖于商品的状态,上架还是下架。因为我们是微 服务,各个模块之间没有直接的联系。我们可以需要考虑在 商品微服务中 商品 如果下架或者上架时,我们这个静态页 和 es数据库同时也会进行删除或者新 增。因此我们需要一个消息中间件 RabbitMQ,让 静态页面微服务 和 搜索微 服务 监听 商品微服务 发送的消息。(可以去看MQ技术) (题外话: 静态页这个业务也不复杂, 但是涉及到了MQ,MQ就能背很挺长 时间的, 所以背会MQ凭着静态页拿offer也没问题.) 因为商品新增后需要上架用户才能看到,商品修改需要先下架,然后修改, 再上架。因此上述问题可以统一的设计成这样的逻辑处理:
- 商品上架时,生成静态页并新增索引库数据;
- 商品下架时,删除静态页,或者修改静态页并删除索引库数据。
这样保证数据库商品与索引库、静态页三者之间的数据同步【异步调用】如
下就是不同MQ的技术对比.
当商品服务对商品进行新增和上下架的时候,需要发送一条消息,通知其它
服务(搜索微服务、静态页微服务),对商品的增删改时其它服务可能需要新的
商品数据,但是如果消息内容中包含全部商品信息,数据量太大,而且并不是每
个服务都需要全部的信息。因此我们只发送商品id,其它服务可以根据id查询 自己需要的信息。 商品上架时:搜索微服务添加新的数据到索引库,静态页微服务创建新的静 态页。 商品下架时:搜索微服务删除索引库数据,静态页微服务删除原来的静态页。 我们编写了一个常量类,用来记录会用到的topic名称和tags名称。商品
微服务发送消息,搜索微服务和静态页微服务都需要两个不同的队列,编写两个
监听器,监听是上架还是下架两个不同类型的消息。
在静态页面微服务中提供了生产静态页面和删除静态页面的功能。当监听到
生产静态页的消息时,监听器会根据要生产静态页面的商品ID使用Feign组件 调用商品微服务用以获取该商品的详细信息,组织成事先协商好的格式数据,调 用Thymeleaf生产商品的静态页面并保存到Nginx静态资源文件夹下。当监听 到删除静态页面的消息时,监听器会根据商品ID直接删除Nginx静态资源文件 夹下的对应的静态页面。
10 7 2 什么是静态化…………………………………………………………………………………………….
静态化是指把动态生成的HTML页面变为静态内容保存,以后用户的请求到
来,直接访问静态页面,不再经过服务的渲染。
而静态的HTML页面可以部署在nginx中,从而大大提高并发能力,减小 tomcat压力。
10 7 3 常见的静态化技术及对比………………………………………………………………………….
名称 优点 缺点 使用场景
jsp………………………………………………………………………………………………………………………..
1 、功能强大,可以写java代码
2 、支持jsp标签(jsptag)
3 、支持表达式语言(el)
4 、官方标准,用户群广,丰富的第
三方jsp标签库
5 、性能良好。jsp编译成class文件
执行,有很好的性能表现
JSP性能太
致命了,前后端分离
基本都不用他了。JSP
动态资源和静态资源
全部耦合在一起,服
务器压力大,因为服
务器会收到各种http
请求,例如css的
http请求,js的,图
片的等等?
适合初学者
老项目
不推荐项目
使用
freemarker
1 、不能编写java代码,可
以实现严格的mvc分离
2 、在复杂页面上(包含大量判断、
日期金额格式化)的页面上,性能非
常不错
3 、对jsp标签支持良好
4 、内置大量常用功能,使用非常方
便
5 、宏定义(类似jsp标签)非常方
便
6 、使用表达式语言
7 、FreeMarker是一个用Java语言
1 、不是官方标准
2 、用户群体和第三方
标签库没有jsp多
企业项目使
用最多
10 8 用户注册(阿里大于+Redis+MQ)………………………………………………………………………..
10 8 1 业务思路……………………………………………………………………………………………………
( 1 )技术分析
编写的模板引擎,它基于模板来生成
文本输出。FreeMarker与Web容
器无关
velocity………………………………………………………………………………………………………………..
1 、不能编写java代码,可以实现严
格的mvc分离
2 、性能良好,据说比jsp性能还要
好些
3 、使用表达式语言,据说jsp的表
达式语言就是学velocity的
4 、性能,velocity应该是最好的。
在大量的判断上不如freemarker
1 、不是官方标准
2 、用户群体和第三方
标签库没有jsp多。
3 、对jsp标签支持不
够好
4 、文件名必须为vm,
配置麻烦
离线的使用
Velocity,
企业项目有
使用
thymeleaf…………………………………………………………………………………………………………….
1 、静态html嵌入标签属性,浏览器
可以直接打开模板文件,便于前后端
联调。 springboot官方推荐方案 。
1 、模板必须符合xml
规范,就这一点就可
以判死刑!太不方便
了!js脚本必须加入/
使用项目不
多
因为我们这个项目是微服务的架构, 一切都是面向服务的思想, 所以注册和
发短信我们可以拆分成两个微服务, 因为发短信这个动作不一定用户注册的时
候采用用到, 其他模块像是绑定邮箱啊, 忘记密码这些也要用到发短信, 所以拆
分成了两个微服务. 这也是提高了代码的复用性.
短信微服务是拆分出来了,但是一个是注册微服务,一个是短信微服务, 这两
个微服务之间是可以通过feign组件进行调用. 但是, 如果同一段时间有大量用 户来注册我这个平台, 只用feign组件会造成调用阿里云组件的时候发生阻塞, 也就是会有可能遇到用不迟迟收不到短信验证码, 所以我们为了让两个解耦合 的微服务进行消息同步, 我们加入了消息中间件, 注册微服务生产消息(获取到 的用户手机号)将消息发送到中间件中, 短信微服务消费消息发送验证码, 中间 件的作用就是消息队列, 给用户排队的作用, 这样就解决了阻塞问题了. 那么市面上有的消息中间件有什么呢?RabbtiMQ,ActiveMq–>这里对比 下二者优缺点, 着重说RabbitMq优点, 所以我们选择了它. 那涉及到 RabbitMQ消息中间件我私下里对他也做了研究, 它常用的 5 种发消息模式啊, 消息丢失解决方案, 消息堆积解决方案啊, 这个我先把注册业务跟您介绍完您如 果感兴趣我稍后跟您介绍.(详细介绍就是单独的RabbitMq那个技术点了.) 咱们继续说, 刚才说的加入中间件给用户排队, 这样我们就能正常发送短信 了, 刚才有跟您提到发短信的流程, 我们调用了阿里云获得的短信, 要告诉用户 让他知道, 所以这个验证码肯定要存到一个地方, 存到哪里呢?我们考虑到两种 方案, 而且这个验证码是有时效性质的, 我们设定的是 10 分钟后过期. 所以第 一种方案存到本地, 但要设置个定时任务, 每 10 分钟清除一次, 这样功能可以 实现, 但又加大了开发人员的开发效率, 有没有一种方法或借助外传的组件就能
清除呢?这是有了第二种方案,Redis. 首先Redis是一个非关系型数据库, 数据 存在内存当中读写效率很高, 这样也能提高用户的体验率,Redis中自带key的 有效期,我们可以设置key的有效期 10 分钟,这样就能自动清除验证码了, 既然提 到Redis, 您如果感兴趣我也可以跟您详细介绍下?(详细介绍就是单独的Redis 那个技术点了.) (题外话==>注册这个业务就涉及到两个技术点, 虽然业务挺简单的, 但是 Redis和RabbtiMq这么出彩的技术点能背全了,每个技术点背会了, 就这个注 册功能就能说 1 个小时,offer就能拿到了,其他的业务也是这样的, 业务中有技 术, 涉及到技术就往全力深了说.) ( 2 )如何实现的 用户搜索到自己心仪的商品后可能会发生购买,但在购买前必须先登录,所 以在此之前需要先注册用户,在用户注册时需要先进行数据校验和获取验证码。 当用户填写完用户名或手机号后,会向后台发送异步请求,后台获取用户名 或手机号码会对数据进行唯一校验,若是未注册过就会返回可用,反之返回不可 用。 正确填写手机号码后可以点击发送验证码,后台接收到页面发送过来手机 号,确认无误后,随机生成 6 位验证码,保存到Redis中 5 分钟。调用短信微 服务将手机号和验证码发送过去,短信微服务监听到发送验证码消息后,会使用 阿里大于发送验证码到指定手机号码。 当用户填写完所有个人信息并且数据校验无误,验证码填写完成后可以进行 最后的用户注册。 注册当时我们考虑到两种方案,第一种是给用户发送邮件通知用户, 第二种
给获取用户手机号给用户发送短信验证码,因为现在还是手机注册比较方便所以
采用了手机注册, 发短信的话直接采用了第三方组件, 调用阿里云给用户发送短
信, 具体业务如下:
- 校验用户名或手机号唯一;
- 发送验证码;
- 注册
- 校验短信验证码;
- 加密用户输入的密码;
- 保存到数据库中。
用户发生购买行为之前必须先有用户,所以用户注册是必不可少的一个环
节。用户注册主要是收集用户的信息。①用户在用户页面填写用户信息,用户名
或手机号,这时要进行唯一校验。②手机号填写完毕后需要点击发送验证码,并
填写收到的验证码。③用户数据收集齐全后进行注册,注册时需要进行验证码校
验,校验无误后需要对用户的密码进行加密处理,最后保存用户信息到数据库。
10 8 2 阿里大于……………………………………………………………………………………………………
阿里大于(原阿里大鱼)是阿里通信旗下产品,融合了三大运营商的通信能
力,通+过将传统通信业务和能力与互联网相结合,创新融合阿里巴巴生态内容,
全力为中小企业和开发者提供优质服务。阿里大于提供包括短信、语音、流量直
充、私密专线、店铺手机号等个性化服务。通过阿里大于,用淘宝帐户打通三大
运营商通信能力,通过这个平台,中小企业及开发者可以在最短的时间内实现短
信验证码发送、短信服务提醒、语音验证码、语音服务通知、IVR及呼叫中心、
码号、后向流量、隐私保护相关的能力,实现互联网电信化。
10 9 用户登录(JWT+Redis)………………………………………………………………………………………..
10 9 1 授权业务思路(登录)……………………………………………………………………………..
目前市面上流行的有 有状态登录和无状态登录两种方式.
( 1 )有状态登录
有状态服务,即服务端需要记录每次会话的客户端信息,从而识别客户
端身份,根据用户身份进行请求的处理,典型的设计如tomcat中的session。
例如登录:用户登录后,我们把登录者的信息保存在服务端session中,
并且给用户一个cookie值,记录对应的session。然后下次请求,用户携
带cookie值来,我们就能识别到对应session,从而找到用户的信息。
有状态登录的缺点是什么?
服务端保存大量数据,增加服务端压力
服务端保存用户状态,无法进行水平扩展.
客户端请求依赖服务端,多次请求必须访问同一台服务器
( 2 ) 那什么是无状态登录呢?
微服务集群中的每个服务,对外提供的都是Rest风格的接口。而Rest
风格的一个最重要的规范就是:服务的无状态性,即:
服务端不保存任何客户端请求者信息
客户端的每次请求必须具备自描述信息,通过这些信息识别客户端
身份.
带来的好处是什么呢?
客户端请求不依赖服务端的信息,任何多次请求不需要必须访问到
同一台服务.
服务端的集群和状态对客户端透明.
服务端可以任意的迁移和伸缩.
减小服务端存储压力.
无状态登录的流程:
当客户端第一次请求服务时,服务端对用户进行信息认证(登录)
认证通过,将用户信息进行加密形成token,返回给客户端,作为
登录凭证.
以后每次请求,客户端都携带认证的token
服务的对token进行解密,判断是否有效。
整个登录过程中,最关键的点是什么?
token的安全性 token是识别客户端身份的唯一标示,如果加密不够严密,被人伪造那 就完蛋了。
采用何种方式加密才是安全可靠的呢?
我们将采用 JWT+RSA非对称加密.
( 3 )我们怎么做的?
用户在登录页面正确填写用户名和密码后,点击登录,请求会携带用户名和
密码到授权中心微服务,授权中心微服务使用Feign组件访问用户微服务根据 用户名和密码查询用户信息,判断返回的用户是否为NULL,不为NULL根据私 钥生产JWT并写入cookie到浏览器。
1 、用户请求登录,携带用户名密码到授权中心 2 、授权中心携带用户名密码,到用户中心查询用户 3 、查询如果正确,生成JWT凭证,查询错误则返回 400 , 4 、返回JWT给用户 用户登录,采用的是 JWT 的无状态登录。①当客户端第一次请求服务时, 服务端会对用户进行信息认证(去调用用户微服务去根据用户名和密码进行查询 验证)。②如果认证通过,授权中心会将用户信息进行加密形成token(cookie), 返回给客户端,作为登录凭证。③以后每次请求,客户端都携带认证的token, 由每一个微服务进行解密,判断是否有效。 加密技术有哪些? ①对称加密,如AES; ②非对称加密,如RSA;(这也是我们采用的一种方式, 私钥加密, 公钥解密) ③不可逆加密,如MD 5 。 怎么才能提高JWT验证方式? 修改后的 JWTtoken 使用私钥加密,把公钥下发到每一个微服务,每一个 微 服 务 可 以 使 用公 钥 进 行 验 证 签 名 ( application.yml 使 用 springCloudConfig 组件 和 springCloudBus可以完成统一配置)。
( 4 ) 授权中心的主要职责:
4. 1 用户登录:
接收用户的登录请求,
通过用户中心的接口校验用户名密码
使用私钥生成JWT并返回
上面介绍的就是用户登录功能的实现, 除了登录功能还有如下功能.
4. 2 用户登录状态校验
判断用户是否登录,其实就是token的校验 4. 3 用户登出->用户选择退出登录后,要让token失效 第一种方案: 用户点击退出,发起请求到服务端 服务端删除用户session即可 我们现在登录是无状态的,也就没有session,那该怎么办呢? 是不是直接删除cookie就可以了。别忘了,我们设置了httponly,JS无法 操作cookie。因此,删除cookie也必须发起请求到服务端,由服务端来删除 cookie。
那么,是不是删除了cookie,用户就完成了退出登录呢?
设想一下,删除了cookie,只是让用户在当前浏览器上的token删除 了,但是这个 token依然是有效的 !这就是JWT的另外一个缺点了,无法控制 TOKEN让其失效。如果用户提前备份了token,那么重新填写到cookie后, 登录状态依然有效。
所以,我们 不仅仅要让浏览器端清除cookie,而且要让这个cookie中的 token失效 !
第二种方案: 失效token黑名单
怎样才能实现这样的效果呢? 有很多办法,但是无论哪种思路,都绕不可一点:JWT的无法修改特性。因 此 我们不能修改token来标记token无效,而是在服务端记录token状态 , 于是就违背了无状态性的特性。
如果要记录每一个token状态,会造成极大的服务端压力,我提供一种
思路,可以在轻量级数据量下,解决这个问题:
用户进行注销类型操作时(比如退出、修改密码),校验token有效性,
并解析token信息
把token的id存入redis,并设置有效期为token的剩余有效期
校验用户登录状态的接口,除了要正常逻辑外,还必须判断token的id
是否存在于redis
如果存在,则证明token无效;如果不存在,则证明有效
等于是在Redis中记录失效token的黑名单,黑名单的时间不用太长,最
长也就是token的有效期: 30 分钟,因此服务端数据存储压力会减少。 用户登录状态刷新–> token怎么进行刷新(续签问题)? 用户登录一段时间后,JWT可能过期,需要刷新有效期 JWT内部设置了token的有效期,默认是 30 分钟, 30 分钟后用户的登 录信息就无效了,用户需要重新登录,用户体验不好。而且JWT还有一个 非常明显的缺点:JWT生成后无法更改。因此我们无法修改token中的有 效期,也就是无法续签。解决方式:每次请求我们需要在token即将到期时, 重新生成一个token。这就需要设置一个最小刷新时间。用户在请求时,我 们要根据请求来的token中的过期时间 -(减) 最小刷新时间的值 和 当 前系统的时间进行比较。如果大于当前系统时间(在当前系统时间之前), 我们就重新生成一个token添加到cookie返回给客户端。
10 9 2 鉴权业务思路(每个微服务验证是否登录)……………………………………………..
登录成功后用户每次访问微服务都会获取cookie中的JWT,利用公钥验证 token。若是JWT无效就会返回 401 ,有效就会返回用户目标资源。
鉴权流程:
①用户请求某一个微服务功能,会携带JWT;
①用户请求某一个微服务功能,携带 JWT;
②微服务工具公钥进行鉴权;
③如果鉴权成功,返回结果;
④如果鉴权失败,返回 401 (没有权限)。
大部分的微服务都必须做这样的权限判断,但是如果在每个微服务单独做权
限控制,每个微服务上的权限代码就会有重复,如何更优雅的完成权限控制呢?
我们可以在整个服务的入口完成服务的权限控制,这样微服务中就无需再做
了,如图:
接下来,我们在Zuul编写拦截器,对用户的token进行校验,完成初步的 权限判断.
限控制,一般有粗粒度、细粒度控制之分,但不管哪种,前提是用户必须先 登录。知道访问者是谁,才能知道这个人具备怎样的权限,可以访问那些服务资 源(也就是微服务接口)。
因此,权限控制的基本流程是这样:
1 )获取用户的登录凭证jwt.
2 )解析jwt,获取用户身份.
如果解析失败,证明没有登录,返回 401
如果解析成功,继续向下
3 )根据身份,查询用户权限信息.
4 )获取当前请求资源(微服务接口路径).
5 )判断是否有访问资源的权限
一般权限信息会存储到数据库,会对应角色表和权限表:
角色:就是身份,例如普通用户,金钻用户,黑钻用户,商品管理
员
权限:就是可访问的访问资源,如果是URL级别的权限控制,包含
请求方式、请求路径、等信息
一个角色一般会有多个权限,一个权限也可以属于多个用户,属于多对多关
系。根据角色可以查询到对应的所有权限,再根据权限判断是否可以访问当前资
源即可。
10 9 3 什么是有状态登录?…………………………………………………………………………………
有状态服务,即服务端需要记录每次会话的客户端信息,从而识别客户端身
份,根据用户身份进行请求的处理,典型的设计如tomcat中的session。 缺点 服务端保存大量数据,增加服务端压力。 服务端保存用户状态,无法进行水平扩展。 客户端请求依赖服务端,多次请求必须访问同一台服务器。
10 9 4 什么是无状态登录?…………………………………………………………………………………
微服务集群中的每个服务,对外提供的都是Rest风格的接口。而Rest风格 的一个最重要的规范就是:服务的无状态 性,即: 服务端不保存任何客户端请求者信息。 客户端的每次请求必须具备自描述信息,通过这些信息识别客户端身份。 优点 客户端请求不依赖服务端的信息,任何多次请求不需要必须访问到同一台服 务。 服务端的集群和状态对客户端透明。 服务端可以任意的迁移和伸缩。 减小服务端存储压力。
10 9 5 JWT……………………………………………………………………..
JSONWebToken(JWT)是一个非常轻巧的规范。这个规范允许我们使用 JWT在用户和服务器之间传递安全可靠的信息。
10. 9. 5. 1 组成
一个JWT实际上就是一个字符串,它由三部分组成,头部、载荷与签名。 头部(Header) 头部用于描述关于该JWT的最基本的信息,例如其类型以及签名所用的算 法等。这也可以被表示成一个JSON对象。 {“typ”:“JWT”,“alg”:“HS 256 “} 在头部指明了签名算法是 HS 256 算法。 我们进行 BASE 64 编码 ( http://base 64 .xpcha.com/ ) , 编 码 后 的 字 符 串 如 下 : eyJ 0 eXAiOiJKV 1 QiLCJhbGciOiJIUzI 1 NiJ 9 载荷(playload) 载荷就是存放有效信息的地方。这个名字像是特指飞机上承载的货品,这些 有效信息包含三个部分: 1. 标准中注册的声明(建议但不强制使用) iss:jwt签发者 sub:jwt所面向的用户 aud: 接收jwt的一方 exp:jwt的过期时间,这个过期时间必须要大于签发时间 nbf: 定义在什么时间之前,该jwt都是不可用的. iat:jwt的签发时间 jti:jwt的唯一身份标识,主要用来作为一次性token 2 .公共的声明 公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务
需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密。
3. 私有的声明
私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信
息,因为base 64 是对称解密的,意味着该部分信息可以归类为明文信息。 这个指的就是自定义的claim。比如前面那个结构举例中的admin和name 都属于自定的claim。这些claim跟JWT标准规定的claim区别在于:JWT 规定的claim,JWT的接收方在拿到JWT之后,都知道怎么对这些标准的 claim进行验证(还不知道是否能够验证);而privateclaims不会验证,除 非明确告诉接收方要对这些claim进行验证以及规则才行。定义一个 payload: {“sub”:” 1234567890 “,“name”:“JohnDoe”,“admin”:true} 然后将其进行base 64 加密,得到Jwt的第二部分。 eyJzdWIiOiIxMjM 0 NTY 3 ODkwIiwibmFtZSI 6 IkpvaG 4 gRG 9 lIiwiYW RtaW 4 iOnRydWV 9 签证(signature) jwt的第三部分是一个签证信息,这个签证信息由三部分组成: header(base 64 后的) payload(base 64 后的) secret 这个部分需要base 64 加密后的header和base 64 加密后的payload使用. 连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合 加密,然后就构成了jwt的第三部分。
eyJhbGciOiJIUzI 1 NiIsInR 5 cCI 6 IkpXVCJ 9 .eyJzdWIiOiIxMjM 0 NTY 3 ODk wIiwibmFtZSI 6 IkpvaG 4 gRG 9 lIiwiYWRtaW 4 iOnRydWV 9 .TJVA 95 OrM 7 E 2 cB ab 30 RMHrHDcEfxjoYZgeFONFh 7 HgQ 注意 secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就 是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场 景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自 我签发jwt了。 **使用场景
- 一次性验证** 比如用户注册后需要发一封邮件让其激活账户,通常邮件中需要有一个链 接,这个链接需要具备以下的特性:能够标识用户,该链接具有时效性(通常只 允许几小时之内激活),不能被篡改以激活其它可能的账户……这种场景就和 jwt 的特性非常贴近,jwt 的 payload中固定的参数:iss 签发者和 exp 过期时间 正是为其做准备的。 2 .restfulapi的无状态认证 使用 jwt 来做 restfulapi 的身份认证也是值得推崇的一种使用方案。客户 端和服务端共享 secret;过期时间由服务端校验,客户端定时刷新;签名信息 不可被修改……springsecurityoauthjwt 提供了一套完整的 jwt 认证体系, 以笔者的经验来看:使用 oauth 2 或 jwt 来做 restfulapi 的认证都没有大问 题,oauth 2 功能更多,支持的场景更丰富,后者实现简单。 3 .使用 jwt 做单点登录+会话管理(不推荐)
10. 9. 5. 2 面试问题:
10. 9. 5. 2. 1 JWTtoken 泄露了怎么办?(常问)
使用 https 加密你的应用,返回 jwt 给客户端时设置 httpOnly=true 并 且使用 cookie 而不是 LocalStorage 存储 jwt,这样可以防止 XSS 攻击和 CSRF攻击。
10. 9. 5. 2. 2 Secret如何设计?
jwt 唯一存储在服务端的只有一个 secret,个人认为这个 secret 应该设计 成和用户相关的属性,而不是一个所有用户公用的统一值。这样可以有效的避免 一些注销和修改密码时遇到的窘境。
10. 9. 5. 2. 3 注销和修改密码?
传统的 session+cookie方案用户点击注销,服务端清空 session 即可, 因为状态保存在服务端。但 jwt 的方案就比较难办了,因为 jwt 是无状态的, 服务端通过计算来校验有效性。没有存储起来,所以即使客户端删除了 jwt,但 是该 jwt 还是在有效期内,只不过处于一个游离状态。分析下痛点:注销变得 复杂的原因在于 jwt 的无状态。提供几个方案,视具体的业务来决定能不能接 受: 仅仅清空客户端的 cookie,这样用户访问时就不会携带 jwt,服务端就认 为用户需要重新登录。这是一个典型的假注销,对于用户表现出退出的行为,实 际上这个时候携带对应的 jwt 依旧可以访问系统。
清空或修改服务端的用户对应的 secret,这样在用户注销后,jwt 本身不变, 但是由于 secret 不存在或改变,则无法完成校验。这也是为什么将 secret 设 计成和用户相关的原因。 借助第三方存储自己管理 jwt 的状态,可以以 jwt 为 key,实现去 Redis 一类的缓存中间件中去校验存在性。方案设计并不难,但是引入 Redis之后, 就把无状态的 jwt 硬生生变成了有状态了,违背了 jwt 的初衷。实际上这个方 案和 session 都差不多了。 修改密码则略微有些不同,假设号被到了,修改密码(是用户密码,不是 jwt 的 secret)之后,盗号者在原 jwt 有效期之内依旧可以继续访问系统,所以仅 仅清空 cookie 自然是不够的,这时,需要强制性的修改 secret。
10. 9. 5. 2. 4 如何解决续签问题
传统的 cookie 续签方案一般都是框架自带的,session 有效期 30 分钟, 30 分钟内如果有访问,session 有效期被刷新至 30 分钟。而 jwt 本身的 payload之中也有一个 exp 过期时间参数,来代表一个 jwt 的时效性,而 jwt 想延期这个 exp 就有点身不由己了,因为 payload 是参与签名的,一旦过期 时间被修改,整个 jwt 串就变了,jwt 的特性天然不支持续签。 **解决方案
- 每次请求刷新 jwt。** jwt 修改 payload 中的 exp后整个 jwt 串就会发生改变,那就让它变好 了,每次请求都返回一个新的 jwt 给客户端。只是这种方案太暴力了,会带来 的性能问题。
2 .只要快要过期的时候刷新 jwt 此方案是基于上个方案的改造版,只在前一个jwt的最后几分钟返回给客户 端一个新的 jwt。这样做,触发刷新 jwt 基本就要看运气了,如果用户恰巧在 最后几分钟访问了服务器,触发了刷新,万事大吉。如果用户连续操作了 27 分 钟,只有最后的 3 分钟没有操作,导致未刷新 jwt,无疑会令用户抓狂。 3. 完善 refreshToken 借鉴 oauth 2 的设计,返回给客户端一个 refreshToken,允许客户端主动 刷新 jwt。一般而言,jwt 的过期时间可以设置为数小时,而 refreshToken 的 过期时间设置为数天。 4. 使用 Redis 记录独立的过期时间 在 Redis 中单独为每个 jwt 设置了过期时间,每次访问时刷新 jwt 的过期时 间,若 jwt 不存在与 Redis 中则认为过期。
10. 9. 5. 2. 5 如何防止令牌被盗用?
令牌:
eyJhbGciOiJIUzI 1 NiJ 9 .eyJqdGkiOiJObzAwMDEiLCJpYXQiOjE 1 Njk xNTg 4 MDgsInN 1 YiI 6 IuS 4 u-mimCIsImlzcyI 6 Ind 3 dy 5 pdGhlaW 1 hLmNvbSI sImV 4 cCI 6 MTU 2 OTE 1 ODgyMywiYWRkcmVzcyI 6 IuS 4 reWbvSIsIm 1 vbmV 5 IjoxMDAsImFnZSI 6 MjV 9 .lkaOahBKcQ-c 8 sBPp 1 Op-siL 2 k 6 RiwcEiR 17 JsZ Dw 98
如果令牌被盗,只要该令牌不过期,任何服务都可以使用该令牌,有可
能引起不安全操作。我们可以在每次生成令牌的时候,将用户的客户端信息获取,
同时获取用户的IP信息,然后将IP和客户端信息以MD 5 的方式进行加密,放
到令牌中作为载荷的一部分,用户每次访问微服务的时候,要先经过微服务网关,
此时我们也获取用户客户端信息,同时获取用户的IP,然后将IP和客户端信息
拼接到一起再进行MD 5 加密,如果MD 5 值和载荷不一致,说明用户的IP发生
了变化或者终端发生了变化,有被盗的嫌疑,此时不让访问即可。这种解决方案
比较有效。
当然,还有一些别的方法也能减少令牌被盗用的概率,例如设置令牌超
时时间不要太长。
10 9 6 加密技术…………………………………………………………………………………………………..
加密技术是对信息进行编码和解码的技术,编码是把原来可读信息(又称明文)
译成代码形式(又称密文),其逆过程就是解码(解密),加密技术的要点是加
密算法,加密算法可以分为三类:
对称加密,如AES 基本原理:将明文分成N个组,然后使用密钥对各个组进行加密,形成各自 的密文,最后把所有的分组密文进行合并,形成最终的密文。 优势:算法公开、计算量小、加密速度快、加密效率高 缺陷:双方都使用同样密钥,安全性得不到保证 非对称加密,如RSA 基本原理:同时生成两把密钥:私钥和公钥,私钥隐秘保存,公钥可以下发
给信任客户端私钥加密,持有私钥或公钥才可以解密公钥加密,持有私钥才可解
密
优点:安全,难以破解
缺点:算法比较耗时
不可逆加密,如MD 5 ,SHA 基本原理:加密过程中不需要使用密钥,输入明文后由系统直接经过加密算 法处理成密文,这种加密后的数据是无法被解密的,无法根据密文推算出明文。 RSA 1977 年,三位数学家Rivest、Shamir 和 Adleman 设计的一种算法,可 以实现非对称加密。这种算法用他们三个人的名字缩写:RSA。 为什么要使用RSA 非对称加密 使用非对称加密的特性,不用担心公钥泄漏问题,因为公钥是无法伪造签名的。
10 10 购物车(localstorage+Redis)……………………………………………………………………………
10 10 1 业务思路…………………………………………………………………………………………………
购物车数据结构 —>对象的数组 [{…},{…},{…}]
不管用户是否登录,都需要实现购物车功能,那么已登录和未登录情况下,购物
车数据应该存放在哪里呢
( 1 )未登录购物车:
用户如果未登录,将数据保存在与服务端存在一些问题:
①无法确定用户身份,需要借助于客户端存储识别身份
②服务端数据存储压力增加,而且可能是无效数据
那么我们应该把数据保存在客户端,这样每个用户保存自己的数据,就不存在
身份识别的问题了,而且也解决了服务端数据库存储压力的问题
Web本地存储主要有两种方式: ①LocalStorage:localStorage 方法存储的数据没有时间限制。第二天、 第二周或下一年之后,数据依然可用(我们使用这个实现本地存储) ②SessionStorage:sessionStorage 方法针对一个 session 进行数据存 储。当用户关闭浏览器窗口后,数据会被删除 注意:localStorage和SessionStorage都只能保存字符串,因此在使用时要 注意 localStorage语法: localStorage.setItem(“key”,“value”);// 存储数据 localStorage.getItem(“key”);// 获取数据 localStorage.removeItem(“key”);// 删除数据 ( 2 )已登录购物车: 首先想到的是数据库,不够购物车数据比较特殊,读和写都比较频繁,存储数据 库压力会比较大.因此我们必须考虑存入redis中,考虑到redis存储空间问题,我 们可以限制购物车最大添加商品数 第一步:要想办法获取登录的用户信息,获取登录用户信息的方式: 方式一:页面直接把用户作为请求参数传递 优点:简单,方便,代码量为 0 缺点:不安全,因为调用购物车CRUD的请求是从页面发过来的,我 们不能确定这个传递来的id是不是真的是用户的id
方拾二:自己从cookie的token中解析JWT 优点:安全 缺点:需要重复校验JWT,已经在网关中做过了,代码麻烦 方式三:在网关校验用户的时候,把用户信息传递到后面的微服务 优点:安全,并且微服务不需要自己解析 缺点:需要在网关加入新的逻辑 微服务也要写回去用户的逻辑,代码麻烦 我们选择方式二,但是方式二中的需要解析JWT,性能太差,因为token 中的载荷是BASE 64 编码,可以不用验证jwt,直接解析载荷即可 第二步:购物车中的每个业务都需要获取当前登录的用户信息,如果在每个接 口中都写这样一段逻辑,显然是冗余的。我们是不是可以利用AOP的思想,拦 截每一个进入controller的请求,统一完成登录用户的获取呢 ①编写AOP拦截,统一获取登录用户:这个可以使用SpringMVC的通 用拦截器:HandlerInterceptor来实现 ②把用户保存起来,方便后面的controller使用,每次请求都有不同的用 户信息,在并发请求情况下,必须保证每次请求保存的用户信息互不干扰,线程 独立 问题?用户信息保存到哪? 第三步:在并发请求情况下,因为每次请求都有不同的用户信息,我们必须保 证每次请求保存的用户信息互不干扰,线程独立。注意:这里不是解决多线程资 源共享问题,而是要保证每个线程都有自己的用户资源,互不干扰。而JDK中 提供的ThreadLocal恰好满足这个需求
ThreadLocal关键点: 接口方法: publicvoidset(Tvalue)设置当前线程的线程局部变量的值 PublicTget() 该方法返回当前线程所对应的线程局部变量 Publicvoidremove() 将当前线程局部变量的值删除,目的是为了减少 内存的占用,该方法是JDK 5. 0 新增的方法 ProtectedTinitialValue() 返回该线程局部变量的初始值
第四步:购物车的数据结构
Redis数据结构的选择 首先不同用户应该有独立的购物车,因此购物车应该以用户的作为key来存 储,Value是用户的所有购物车信息。这样看来基本的k-v结构就可以了 但是,我们对购物车中的商品进行增、删、改操作,基本都需要根据商品id 进行判断,为了方便后期处理,我们的购物车也应该是k-v结构,key是商品id, value才是这个商品的购物车信息 综上所述,我们的购物车结构是一个双层map: Map<String,Map<String,String» 第一层Map,Key是用户id 第二层Map,Key是购物车中商品id,值是购物车数据
10 10 2 Html 5 web存储……………………………………………………………………………………..
Html 5 提供了两种在客户端存储数据的新方法: localStorage:没有时间限制的数据存储 SessionStorage:针对一个session的数据存储(关闭浏览器) 之前这些都是由cookie完成的。但是cookie不适合大量数据的存储,因为 它们由每个对服务器的请求来传递,这使得cookie速度很慢而且效率也不高。 在Html 5 中,数据不是由每个服务器请求传递的,而是只有在请求时使用 数据。它使在不影响网站性能的情况下存储大量数据成为可能。 对于不同的网站,数据存储于不同的区域,并且一个网站只能访问其自身的 数据。 Html 5 使用JavaScript来存储和访问数据。 注意 :localStorage和SessionStorage都只能保存字符串。
10 10 3 Redis……………………………………………………………………………………………………….
10. 10. 3. 1 什么是Redis
是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的 日志型、高性能的Key-Value数据库,并提供多种语言的API。
10. 10. 3. 2 Redis的存储结构有哪些
String ,字符串,是 Redis的最基本的类型,一个 key 对应一个 value。 是二进制安全的,最大能存储 512 MB。
Hash ,散列,是一个键值(key=>value)对集合。string 类型的 field 和 value 的映射表,特别适合用于存储对象。每个 hash 可以存储 232 - 1 键值 对( 40 多亿) List ,列表,是简单的字符串列表,按照插入顺序排序。你可以添加一个元 素到列表的头部(左边)或者尾部(右边)。最多可存储 232 - 1 元素 ( 4294967295 , 每个列表可存储 40 多亿)。 Set ,集合, 是 string 类型的无序集合,最大的成员数为 232 - 1 ( 4294967295 , 每个集合可存储 40 多亿个成员)。 Sortedset ,有序集合,和 set 一样也是string类型元素的集合,且不允许 重复的成员。不同的是每个元素都会关联一个double类型的分数。Redis正是 通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数 (score)却可以重复。
10. 10. 3. 3 Redis的优点
- 纯内存操作。
- 单线程操作,避免了频繁的上下文切换。
- 采用了非阻塞I/O多路复用机制。 I/O多路复用机制 I/O多路复用就是只有单个线程,通过跟踪每个I/O流的状态,来管理多个 I/O流。
10. 10. 3. 4 Redis的缺点
缓存和数据库双写一致性问题 一致性的问题很常见,因为加入了缓存之后,请求是先从Redis中查询,如 果Redis中存在数据就不会走数据库了,如果不能保证缓存跟数据库的一致性就 会导致请求获取到的数据不是最新的数据。 解决方案: 1 、编写删除缓存的接口,在更新数据库的同时,调用删除缓存的接口删除 缓存中的数据。这么做会有耦合高以及调用接口失败的情况。 2 、消息队列:ActiveMQ,消息通知。 缓存的并发竞争问题 并发竞争,指的是同时有多个子系统去set同一个key值。 解决方案:最简单的方式就是准备一个分布式锁,大家去抢锁,抢到锁就做 set操作即可 缓存雪崩问题 缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果 请求都怼到数据库上,从而导致数据库连接异常。 解决方案:
- 给缓存的失效时间,加上一个随机值,避免集体失效。
- 使用互斥锁,但是该方案吞吐量明显下降了。
- 搭建Redis集群。 缓存击穿问题 缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到
数据库上,从而数据库连接异常。
解决方案:
1 、利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据
库。没得到锁,则休眠一段时间重试。
2 、采用异步更新策略,无论key是否取到值,都直接返回,value值中维 护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。
10. 10. 3. 5 Redis的持久化
Redis提供了两种持久化的方式,分别是RDB(RedisDataBase)和AOF (AppendOnlyFile)。 RDB ,简而言之,就是在不同的时间点,将Redis存储的数据生成快照并存 储到磁盘等介质上。 AOF ,则是换了一个角度来实现持久化,那就是将Redis执行过的所有写指 令记录下来,在下次Redis重新启动时,只要把这些写指令从前到后再重复执行 一遍,就可以实现数据恢复了。 RDB和AOF两种方式也可以同时使用,在这种情况下,如果Redis重启的 话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完 整度更高。
10. 10. 3. 6 RDB
RDB持久化方式,是将Redis某一时刻的数据持久化到磁盘中,是一种快照 式的持久化方法。
RDB持久化方式:Redis在进行数据持久化的过程中,会先将数据写入到一 个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好 的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可 用的。 对于RDB方式,Redis会单独创建一个子进程来进行持久化,而主进程是不 会进行任何IO操作的,这样就确保了Redis极高的性能。 RDB优点 :如果需要进行大规模数据的恢复,且对于数据恢复的完整性不 是非常敏感,那RDB方式要比AOF方式更加的高效。 RDB缺点 :如果你对数据的完整性非常敏感,那么RDB方式就不太适合你, 因为即使你每 5 分钟都持久化一次,当Redis故障时,仍然会有近 5 分钟的数 据丢失。所以,Redis还提供了另一种持久化方式,那就是AOF。
10. 10. 3. 7 AOF
AOF方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序 再将指令都执行一遍。 实现方式:我们通过配置Redis.conf中的appendonlyyes就可以打开AOF 功能。如果有写操作(如SET等),Redis就会被追加到AOF文件的末尾。 AOF持久化的方式:默认的AOF持久化策略是每秒钟fsync一次(fsync 是指把缓存中的写指令记录到磁盘中),因为在这种情况下,Redis仍然可以保 持很好的处理性能,即使Redis故障,也只会丢失最近 1 秒钟的数据。 如果在追加日志时,恰好遇到磁盘空间满或断电等情况导致日志写入不完 整,也没有关系,Redis提供了Redis-check-aof工具,可以用来进行日志修复。
因为采用了追加方式,如果不做任何处理的话,AOF文件会变得越来越大,
为此,Redis提供了AOF文件重写(rewrite)机制,即当AOF文件的大小超 过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数 据的最小指令集。举个例子或许更形象,假如我们调用了 100 次INCR指令, 在AOF文件中就要存储 100 条指令,但这明显是很低效的,完全可以把这 100 条指令合并成一条SET指令,这就是重写机制的原理。 AOF优点 :我们通过一个场景再现来说明。某同学在操作Redis时,不小 心执行了FLUSHALL,导致Redis内存中的数据全部被清空了,这是很悲剧的 事情。不过这也不是世界末日,只要Redis配置了AOF持久化方式,且AOF 文件还没有被重写(rewrite),我们就可以用最快的速度暂停Redis并编辑AOF 文件,将最后一行的FLUSHALL命令删除,然后重启Redis,就可以恢复Redis 的所有数据到FLUSHALL之前的状态了。是不是很神奇,这就是AOF持久化方 式的好处之一。但是如果AOF文件已经被重写了,那就无法通过这种方法来恢 复数据了。 AOF缺点 :比如在同样数据规模的情况下,AOF文件要比RDB文件的体积 大。而且,AOF方式的恢复速度也要慢于RDB方式。 如果你直接执行BGREWRITEAOF命令,那么Redis会生成一个全新的AOF 文件,其中便包括了可以恢复现有数据的最少的命令集。 如果运气比较差,AOF文件出现了被写坏的情况,也不必过分担忧,Redis 并不会贸然加载这个有问题的AOF文件,而是报错退出。这时可以通过以下步 骤来修复出错的文件:
- 备份被写坏的AOF文件。
2. 运行Redis-check-aof –fix进行修复。
3. 用diff-u来看下两个文件的差异,确认问题点。
4 .重启Redis,加载修复后的AOF文件。
10. 10. 3. 8 Redis集群
从复制 主从复制原理 从服务器连接主服务器,发送SYNC命令。 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使 用缓冲区记录此后执行的所有写命令。 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间 继续记录被执行的写命令。 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照。 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令。 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲 区的写命令(从服务器初始化完成)。 主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接 收并执行收到的写命令(从服务器初始化完成后的操作)。 优点 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。 为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作 的服务,写服务仍然必须由Master来完成。
Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载 Master的同步压力。 MasterServer是以非阻塞的方式为Slaves提供服务。所以在Master-Slave 同步期间,客户端仍然可以提交查询或修改请求。 SlaveServer同样是以非阻塞的方式完成数据同步。在同步期间,如果有客 户端提交查询请求,Redis则返回同步之前的数据。 缺点 Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写 请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数 据不一致的问题,降低了系统的可用性。 Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。 哨兵模式 当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提 供服务,但是这个过程需要人工手动来操作。为此,Redis 2. 8 中提供了哨兵工 具来实现自动化的系统监控和故障恢复功能。 哨兵的作用就是监控Redis系统的运行状况,它的功能包括以下两个。 1 、监控主服务器和从服务器是否正常运行。 2 、主服务器出现故障时自动将从服务器转换为主服务器。 哨兵的工作方式 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主 服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds选项所指定的值,则这个实例会被 Sentine(l 哨兵) 进程标记为主观下线(SDOWN)。 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这 个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认 Master主服务器的确进入了主观下线状态。 当有足够数量的Sentinel(哨兵)进程(大于等于配置文件指定的值)在指 定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则 Master主服务器会被标记为客观下线(ODOWN)。 在一般情况下,每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集 群中的所有Master主服务器、Slave从服务器发送 INFO 命令。 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN) 时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器 发送 INFO命令的频率会从 10 秒一次改为每秒一次。 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观 下线状态就会被移除。 优点 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。 主从可以自动切换,系统更健壮,可用性更高。 缺点
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。 Redis-Cluster集群 Redis的哨兵模式基本已经可以实现高可用,读写分离,但是在这种模式下 每台Redis服务器都存储相同的数据,很浪费内存,所以在Redis 3. 0 上加入了 cluster模式,实现的Redis的分布式存储,也就是说每台Redis节点上存储不 同的内容。 Redis-Cluster采用无中心结构,它的特点如下: 所有的Redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传 输速度和带宽。 节点的fail是通过集群中超过半数的节点检测失效时才生效。 客户端与Redis节点直连,不需要中间代理层.客户端不需要连接集群所有节 点,连接集群中任何一个可用节点即可。 工作方式 在Redis的每一个节点上,都有这么两个东西,一个是插槽(slot),它的 取值范围是: 0 - 16383 。还有一个就是cluster,可以理解为是一个集群管理的 插件。当我们的存取的key到达的时候,Redis会根据crc 16 的算法得出一个结 果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0 - 16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后 直接自动跳转到这个对应的节点上进行存取操作。 为了保证高可用,Redis-cluster集群引入了主从模式,一个主节点对应一 个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点ping 一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕
机了。如果主节点A和它的从节点A 1 都宕机了,那么该集群就无法再提供服务
了。
10. 10. 4 购物车存cookie里边 可以实现不登录就可以使用购物车 那么现在没有登录把商品存购物车了登录了然后换台电脑并且登录 了还能不能看见购物车的信息?如果看不到怎么做到cookie同步, 就是在另外一台电脑上可以看到购物车信息
乐优商城现阶段使用的仅仅是把购物车的商品写入cookie中,这样服务端 基本上没有存储的压力。但是弊端就是用户更换电脑后购物车不能同步。 我们的乐优商城项目是把购物车信息保存在了客户端localStorage本地存储, 未登录时可以查询到购物车(通过SpuID查询所有Sku) 打算下一步这么实现:当用户没有登录时向购物车添加商品是添加到 cookie中,当用户登录后购物车的信息是存储在Redis中的并且是跟用户id 向关联的,此时你更换电脑后使用同一账号登录购物车的信息就会展示出来。
10. 10. 5 如果用户一直添加购物车添加商品怎么办?并且他添加一 次你查询一次数据库?互联网上用户那么多,这样会对数据库造成很 大压力怎么办?
当前我们使用cookie的方式来保存购物车的数据,所以当用户往购物车中 添加商品时,并不对数据库进行操作。将来把购物车商品放入Redis中,Redis 是可以持久化的可以永久保存,此时就算是频繁的往购物车中添加数据也没用什 么问题。
10. 10. 6 Redis为什么可以做缓存?项目中使用Redis的目的是什 么?Redis什么时候使用?
1 .Redis是key-value形式的nosql数据库。可以快速的定位到所查找的 key,并把其中的value取出来。并且Redis的所有的数据都是放到内存中,存 取的速度非常快,一般都是用来做缓存使用。 2 .项目中使用Redis一般都是作为缓存来使用的,缓存的目的就是为了减轻 数据库的压力提高存取的效率。 3 .在互联网项目中只要是涉及高并发或者是存在大量读数据的情况下都可以 使用Redis作为缓存。当然Redis提供丰富的数据类型,除了缓存还可以根据 实际的业务场景来决定Redis的作用。例如使用Redis保存用户的购物车信息、 生成订单号、访问量计数器、任务队列、排行榜等。
10 10 7 对Redis和Memcache有没有了解,为什么选择Redis?…………………………
Memcache无持久化: Memecache把数据全部存在内存之中,断电 后会挂掉且数据不能超过内存大小。 而Redis有部份存在硬盘上,这样能保证 数据的持久性(默认RDB模式) Memcache只支持K-V结构,Redis有复杂的数据类型。 Memcache是多线程,性能比Redis(单线程)差 在这里可能会有人问:多线程不是应该比单线程性能要更好吗? 这是因为Memcache大多数时间用在了切换线程上。
10 10 8 Redis面试经常会问到的问题…………………………………………………………………..
10. 10. 8. 1 redis的过期策略以及内存淘汰机制
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释 放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求, 而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个 100 ms检查,是否有过期的key,有过期key则 删除。需要说明的是,redis不是每个 100 ms将所有的key检查一次,而是随 机抽取进行检查(如果每隔 100 ms,全部key进行检查,redis岂不是卡死)。因此, 如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检 查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会 删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说 惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰
机制。在redis.conf中有一行配置#maxmemory-policyvolatile-lru该配置就 是配内存淘汰策略的.
1 )noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。 应该没人用吧。
2 )allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最 近最少使用的key。推荐使用,目前项目在用这种。
3 )allkeys-random:当内存不足以容纳新写入数据时,在键空间中, 随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4 )volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间 的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又 做持久化存储的时候才用。不推荐
5 )volatile-random:当内存不足以容纳新写入数据时,在设置了过期 时间的键空间中,随机移除某个key。依然不推荐
6 )volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的 键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire的key, 不满足先决条件(prerequisites); 那么 volatile-lru,volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不 删除) 基本上一致。
10. 10. 8. 2 redis和数据库双写一致性问题
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。 数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。 就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终 一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概 率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在 删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
10. 10. 8. 3 如何应对缓存穿透和缓存雪崩问题
分析:这两个问题,说句实在话,一般中小型传统软件企业,很难碰到这个问题。 如果有大并发的项目,流量有几百万左右。这两个问题一定要深刻考虑。
回答:如下所示:
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据 库上,从而数据库连接异常。
解决方案:
(一) 利用互斥锁 ,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。 没得到锁,则休眠一段时间重试
(二) 采用异步更新策略 ,无论key是否取到值,都直接返回。value值中维护一 个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要 做缓存预热(项目启动前,先加载缓存)操作。
(三) 提供一个能迅速判断请求是否有效的拦截机制 ,比如,利用布隆过滤器,内 部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。 如果不合法,则直接返回。
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求 都怼到数据库上,从而导致数据库连接异常。
解决方案:
(一) 给缓存的失效时间 ,加上一个随机值,避免集体失效。
(二) 使用互斥锁 ,但是该方案吞吐量明显下降了。
(三) 双缓存 。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为 20 分钟, 缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点:
I从缓存A读数据库,有则直接返回。
IIA没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
III 更新线程同时更新缓存A和缓存B。
10. 10. 8. 4 如何解决redis的并发竞争key问题
分析: 这个问题大致就是,同时有多个子系统去set一个key。这个时候要注意什 么呢?
( 1 )如果对这个key操作,不要求顺序 这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即 可,比较简单。
( 2 )如果对这个key操作,要求顺序 假设有一个key 1 ,系统A需要将key 1 设置为valueA,系统B需要将key 1 设置为valueB,系统C需要将key 1 设置为valueC.
期望按照key 1 的value值按照 valueA–>valueB–>valueC的顺序变 化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳 如下
系统Akey 1 {valueA 3 : 00 } 系统Bkey 1 {valueB 3 : 05 } 系统Ckey 1 {valueC 3 : 10 } 那么,假设这会系统B先抢到锁,将key 1 设置为{valueB 3 : 05 }。接下 来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做 set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵 活变通。
10. 10. 8. 5 mySQL里有 2000 w数据,redis中只存 20 w的数据, 如何保证redis中的数据都是热点数据
通过配置Redis的淘汰策略。 redis 内存数据集大小上升到一定大小的 时候,就会施行数据淘汰策略(回收策略)。
10. 10. 8. 6 redis事物的了解CAS(check-and-set 操作实现乐观 锁 )?
和众多其它数据库一样,Redis作为NoSQL数据库也同样提供了事务机制。在 Redis中,MULTI/EXEC/DISCARD/WATCH这四个命令是我们实现事务的基 石。相信对有关系型数据库开发经验的开发者而言这一概念并不陌生,即便如此, 我们还是会简要的列出Redis中事务的实现特征:
1 ). 在事务中的所有命令都将会被串行化的顺序执行,事务执行期间, Redis不会再为其它客户端的请求提供任何服务,从而保证了事物中的所有命令 被原子的执行。
2 ). 和关系型数据库中的事务相比,在Redis事务中如果有某一条命令 执行失败,其后的命令仍然会被继续执行。
3 ). 我们可以通过MULTI命令开启一个事务,有关系型数据库开发经验 的人可以将其理解为"BEGINTRANSACTION"语句。在该语句之后执行的命令都
将被视为事务之内的操作,最后我们可以通过执行EXEC/DISCARD命令来提交
/回滚该事务内的所有操作。这两个Redis命令可被视为等同于关系型数据库中 的COMMIT/ROLLBACK语句。
4 ). 在事务开启之前,如果客户端与服务器之间出现通讯故障并导致网 络断开,其后所有待执行的语句都将不会被服务器执行。然而如果网络中断事件 是发生在客户端执行EXEC命令之后,那么该事务中的所有命令都会被服务器执 行。
5 ). 当使用Append-Only模式时,Redis会通过调用系统函数write将 该事务内的所有写操作在本次调用中全部写入磁盘。然而如果在写入的过程中出 现系统崩溃,如电源故障导致的宕机,那么此时也许只有部分数据被写入到磁盘, 而另外一部分数据却已经丢失。 Redis服务器会在重新启动时执行一系列必要的一致性检测,一旦发现类似问 题,就会立即退出并给出相应的错误提示。此时,我们就要充分利用Redis工具 包中提供的redis-check-aof工具,该工具可以帮助我们定位到数据不一致的错 误,并将已经写入的部分数据进行回滚。修复之后我们就可以再次重新启动 Redis服务器了。
10. 10. 8. 7 WATCH命令和基于CAS的乐观锁:
在Redis的事务中,WATCH命令可用于提供CAS(check-and-set)功 能。假设我们通过WATCH命令在事务执行之前监控了多个Keys,倘若在 WATCH之后有任何Key的值发生了变化,EXEC命令执行的事务都将被放弃,
同时返回Nullmulti-bulk应答以通知调用者事务执行失败。例如,我们再次假 设Redis中并未提供incr命令来完成键值的原子性递增,如果要实现该功能, 我们只能自行编写相应的代码。其伪码如下:
val=GETmykey val=val+ 1 SETmykey$val 以上代码只有在单连接的情况下才可以保证执行结果是正确的,因为如 果在同一时刻有多个客户端在同时执行该段代码,那么就会出现多线程程序中经 常出现的一种错误场景–竞态争用(racecondition)。比如,客户端A和B都在 同一时刻读取了mykey的原有值,假设该值为 10 ,此后两个客户端又均将该值 加一后set回Redis服务器,这样就会导致mykey的结果为 11 ,而不是我们认 为的 12 。为了解决类似的问题,我们需要借助WATCH命令的帮助,见如下代 码:
WATCHmykey val=GETmykey val=val+ 1 MULTI SETmykey$val EXEC 和此前代码不同的是,新代码在获取mykey的值之前先通过WATCH命令监控 了该键,此后又将set命令包围在事务中,这样就可以有效的保证每个连接在执
行EXEC之前,如果当前连接获取的mykey的值被其它连接的客户端修改,那 么当前连接的EXEC命令将执行失败。这样调用者在判断返回值后就可以获悉 val是否被重新设置成功。 10. 10. 8. 9 redis的缓存失效策略和主键失效机制 作为缓存系统都要定期清理无效数据,就需要一个主键失效和淘汰策略. 在Redis当中,有生存期的key被称为volatile。在创建缓存时,要为给定的 key设置生存期,当key过期的时候(生存期为 0 ),它可能会被删除。 1 、影响生存时间的一些操作 生存时间可以通过使用 DEL 命令来删除整个 key 来移除,或者被 SET和 GETSET 命令覆盖原来的数据,也就是说,修改key对应的value和使用另外相同的 key和value来覆盖以后,当前数据的生存时间不同。
比如说,对一个 key 执行INCR命令,对一个列表进行LPUSH命令,或者对 一个哈希表执行HSET命令,这类操作都不会修改 key 本身的生存时间。另一方面, 如果使用RENAME对一个 key 进行改名,那么改名后的 key的生存时间和改名前 一样。
RENAME命令的另一种可能是,尝试将一个带生存时间的 key 改名成另一个 带生存时间的 another_key ,这时旧的 another_key(以及它的生存时间)会被删除, 然后旧的 key 会改名为 another_key ,因此,新的 another_key 的生存时间也和
原本的 key 一样。使用PERSIST命令可以在不删除 key 的情况下,移除 key 的生 存时间,让 key 重新成为一个persistentkey 。
2 、如何更新生存时间 可以对一个已经带有生存时间的 key 执行EXPIRE命令,新指定的生存时间会 取代旧的生存时间。过期时间的精度已经被控制在 1 ms之内,主键失效的时间复杂度 是O( 1 ),EXPIRE和TTL命令搭配使用,TTL可以查看key的当前生存时间。设置 成功返回 1 ;当 key 不存在或者不能为 key 设置生存时间时,返回 0 。
最大缓存配置 在 redis中,允许用户设置最大使用内存大小server.maxmemory默认为 0 , 没有指定最大缓存,如果有新的数据添加,超过最大内存,则会使redis崩溃,所以 一定要设置。redis内存数据集大小上升到一定大小的时候,就会实行数据淘汰策略。 redis 提供 6 种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑
选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑
选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)
中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据
淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰 no-enviction(驱逐):禁止驱逐数据 注意这里的 6 种机制,volatile和allkeys规定了是对已设置过期时间的 数据集淘汰数据还是从全部数据集淘汰数据,后面的lru、ttl以及random是三 种不同的淘汰策略,再加上一种no-enviction永不回收的策略。
使用策略规则: 1 、如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据 访问频率低,则使用allkeys-lru
2 、如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用 allkeys-random
三种数据淘汰策略: ttl和random比较容易理解,实现也会比较简单。主要是Lru最近最少使用淘 汰策略,设计上会对key按失效时间排序,然后取最先失效的key进行淘汰。
10. 10. 8. 10 读写分离模型
通过增加SlaveDB的数量,读的性能可以线性增长。为了避免MasterDB 的单点故障,集群一般都会采用两台MasterDB做双机热备,所以整个集群的 读和写的可用性都非常高。
读写分离架构的缺陷在于,不管是Master还是Slave,每个节点都必须保 存完整的数据,如果在数据量很大的情况下,集群的扩展能力还是受限于单个节 点的存储能力,而且对于Write-intensive类型的应用,读写分离架构并不适合。
10. 10. 8. 11 使用过Redis分布式锁么,它是什么回事?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止 锁忘记了释放。
10. 10. 8. 12 如果有大量的key需要设置同一时间过期,一般需要注 意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会 出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
10. 10. 8. 13 Redis的同步机制了解么?
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave, 并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复 制节点,复制节点接受完成后将rdb镜像加载到内存。加载完成后,再通知主 节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
10. 10. 8. 13 是否使用过Redis集群,集群的原理是什么?
RedisSentinal着眼于高可用,在master宕机时会自动将slave提升为master, 继续提供服务。
RedisCluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分 片存储。
10 11 订单系统……………………………………………………………………………………………………………
10 11 1 业务思路………………………………………………………………………………………………….
当我们提交订单时,会设置半小时的支付时间,如果这半小时之内为支付的
话,我们会将该订单取消,同时将购物车的商品删除。如果半小时之内支付成功
的话会生成一个订单信息,订单的状态显示为待发货。我们会根据订单的收件人
去调用物流的接口生成物流单,通知物流人员取货。当快递人员提取商品以后,
订单的状态更改为已发货,同时买家可以在订单信息页面的物流状态查看物流信
息。物流信息我们采用的定时任务,没两个小时通过物流给的接口中获取物流信
息,如果查询出来的物流信息没做改变的话我们不更新数据,如果信息改变我们
会在之前的物流信息下增加一个新的物流节点信息。当快递工作人员将商品送到
用户手中以后,我们的订单状态会改变成已收货。用户可以在这个订单下评价这
个商品。
当用户订单下完以后发现购买有误或者收到商品时发现有问题可以申请退
货或者换货的流程,点击申请退货按钮以后我们会根据这笔订单去生成一笔退货
单申请,退货单申请由商家负责审核,如果审核通过买家将商品寄回,当商家收
到商品以后根据退货单的退货信息根据商品比较确认正确的时候关闭退货单,货
款会退回到买家。
10 12 支付系统……………………………………………………………………………………………………………
10 12 1 业务思路(微信支付)……………………………………………………………………..
1 .商户系统根据用户选择的商品生成订单。
2. 用户确认支付后根据微信【统一下单API】,向微信支付系统发出请求(我
们通过httpclient方式请求的)。 3. 微信支付系统收到请求后,先生成预支付订单,然后给商户系统返回二维码 连接。 4. 商户系统拿到返回值字符串,转换成对象,然后取出二维码连接生成二维码。 5. 用户通过微信“扫一扫”功能扫描二维码,微信客户端将扫码内容发送到微
信支付系统。
6. 微信支付系统接收到支付请求,验证链接有效性后发起支付,请求客户确认,
然后我们的微信端就会弹出需要确认支付的页面。
7. 用户输入密码,确认支付并提交授权。
8. 微信支付系统根据用户授权完成交易。
9. 微信支付系统支付成功后向微信客户端返回交易结果,并将交易结果通过短
信、微信提示用户。
10. 微信支付系统通过发送异步消息通知商户系统后台支付结果,商户系统需回
复接收情况,通知微信支付系统不再发送该单的通知。
11. 未收到支付通知的情况,商户系统可调用【查询订单APP】。
12. 商户确认订单已经支付后给用户发货。
10 12 2 支付接口是怎么做的?…………………………………………………………………………….
面试中可以说支付这部分不是我们做的,我们项目中并没有涉及支付部分的
处理。如果想了解支付是如何实现可以参考之前学过的易宝支付相关处理以及支
付宝、微信支付相关文档。
10 12 3 第一个是当两个客户同时买一件商品时库存只有一个了,怎么控制?………….
可以使用MySQL的行锁机制,实现乐观锁,在更新商品之前将商品锁定, 其他用户无法读取,当此用户操作完毕后释放锁。当并发量高的情况下,需要使 用缓存工具例如Redis来管理库存。
十一.十次方项目(了解)………………………………………………………………………………………………………
11 1 十次方背景…………………………………………………………………………………………………………..
11 1 1 需求分析……………………………………………………………………………………………………
首先,该项目工程采用的是前后端分离的开发形式。为什么要采用前后端分
离的开发形式呢?
《十次方》是程序员的专属社交平台,包括头条.问答.活动.交友.吐槽.招聘
六大频道。
十次方名称的由来: 2 的 10 次方为 1024 ,程序员都懂的。
11 1 2 前后端分离的优点和必要性………………………………………………………………………
前端JS做大部分的数据处理工作,减少对服务器的压力;
后端错误不会直接反映到前台,提高用户体验度;
不同终端(pad/mobile/pc)的兴起,单一浏览器端的访问已经不能满足 用户的需求; JS能够很好的适应前端的效果但是很难做到与服务器的通讯,后端又无法 很好的去调整前端页面; 提高开发效率,后端负责业务/数据接口,前端负责展现/交互逻辑,同一份 数据接口,可以定制开发多个版本。(一般项目后期会针对性的整理开发接口 API方便内外部的调用访问)
11 1 3 什么是前后端分离…………………………………………………………………………………….
经由分析讨论以及资料的收集,我们所一致认同的概念是SPA(single-page application),所有用到的展现数据都是后端通过异步接口(ajax.json)的方 式实现的,前端直管展现。 从某种意义上来说,SPA确实做到了前后端分离,但这种方式存在两个问题: ( 1 ) WEB服务中,SPA类占的比例很少。很多场景下还有同步/同步+异 步混合的模式,SPA不能作为一种通用的解决方案;现阶段的SPA开发模式, 接口通常是按照展现逻辑来提供的,有时候为了提高效率,后端会帮我们处理一 些展现逻辑,这就意味着后端还是涉足了View层的工作,不是真正的前后端分 离。 ( 2 )SPA式的前后端分离,是从物理层做区分(认为只要是客户端的就是 前端,服务器端的就是后端),这种分法已经无法满足我们前后端分离的需求, 我们认为从职责上划分才能满足目前我们的使用场景: 前端:负责View和Controller层;只负责Model层,业务处理/数据等。
11 1 4 为什么要前后端分离…………………………………………………………………………………
项目背景:随着互联网的发展,在一定程度上极大的拉近了人与人之间的距
离却又在某种程度上增加了人与人之间的隔膜。我们迫切的想要更多人的关注却
往往陷入社交平台泛滥的漩涡,基于这种情况我们开发了《十次方》应用于IT
方面同学的沟通.交流。让同样的人,说同样的话,得到更多的共鸣与理解。
页面原型的介绍.展示:
以上,是首页的原型展示。其余界面原型在后面功能实现过程中逐步进
行展示。
除此之外,项目开发过程中一般还会有项目需求文档(一般由产品方面
来撰写)有的公司可能为了加快开发进度往往先将这部分工作放一放以导致于后
期进行项目调整的时候带来诸多屏障。所以,在这一块我还是建议无论项目紧张
与否这方面还是要有的。
11 1 5 十次方项目背景………………………………………………………………………………………..
-
-
- 1 系统架构
-
《十次方》采用前后端分离的系统架构,后端架构为:
SpringBoot+SpringCloud+SpringMVC+SpringData
我们把这种架构也称之为全家桶。
-
-
- 2 特色
-
十次方采用了当前主流的前后端分离的开发模式,后端使用Spring全家桶 框架(即SpringBoot+SpringCloud+SpringData+SpringMVC)开发微 服务;前端使用以Node.js为核心的Vue全套生态解决方案。项目中涵盖了微
服务认证.微服务网关.微服务熔断.微服务集中配置.微服务持续集成.第三方登陆.
云存储.爬虫.人工智能.单页面(SPA).服务端渲染(SSR)等 30 余种解决方案。
采用前后端分离的方式进行系统开发
采用模块化的课程设计,分为微服务开发,前端系统开发,爬虫与人工智能
开发三个模块
打造Java全栈式工程师,让学员站在Java软件开发的金字塔顶端
-
-
- 3 模块划分
-
十次方工程共分为 18 个子模块(其中 17 个是微服务)。
如下:
模块名称 模块中文名称
tensquare_common 公共模块 tensquare_article 文章微服务 tensquare_base 基础微服务 tensquare_friend 交友微服务 tensquare_gatherinng 活动微服务 tensquare_qa 问答微服务 tensquare_recruit 招聘微服务 tensquare_user 用户微服务 tensquare_spit 吐槽微服务 tensquare_search 搜索微服务 tensquare_web 前台微服务网关
tensquare_manager 后台微服务网关
tensquare_eureka 注册中心
tensquare_config 配置中心
tensquare_sms 短信微服务
tensquare_article_crawler 文章爬虫微服务
tensquare_user_crawler 用户爬虫微服务
tensquare_ai 人工智能微服务
-
-
- 4 表结构分析
-
文件名 数据库说明
tensquare_article.sql 文章
tensquare_base.sql 基础
tensquare_friend.sql 交友
tensquare_gatherinng.sql 活动
tensquare_qa.sql 问答
tensquare_recruit.sql 招聘
tensquare_user.sql 用户
-
-
- 5 API文档
-
前后端约定返回码列表:
状态码 说明
20000 成功
20001 失败
20002 用户名或密码错误
20003 权限不足
20004 远程调用失败
20005 重复操作
-
-
- 6 开发环境
-
软件 版本
JDK^1.^8
数据库 MySQL 5. 7
开发工具 IDEA 2017. 1
maven 3. 3. 9
docker 1. 13. 1
操作系统 centos 7
-
-
- 7 项目主要技术以及功能实现
-
-
-
-
- 1 前端环境搭建 章节内容:十次方需求.技术架构,理解前后端分离开发模式,Node.js基本 使用方法,理解模块化编程, 包资源管理器NPM的使用,webpack的作用,vs code开发工具的基本使用方法,ES 6 常用的新特性语法
-
-
11. 1. 5. 7. 2 API文档与模拟数据接口
章节内容:RESTful架构, 运用Swagger编写API文档,Mock.js基本语法,
easyMock实现模拟接口的编写
-
-
-
- 3 使用ElementUI开发管理后台 章节内容:elementUI提供的脚手架搭建管理后台的方法,elementUI的 table组件的使用和实现列表功能,elementUI的pagination组件的使用和实现 分页功能,elementUI的form相关组件的使用和实现条件查询功能,elementUI 的dialog组件和$message的使用和实现弹出窗口和消息提示功能,elementUI 的select组件的使用和实现下拉列表功能, 新增数据和修改数据的功能, confirm的使用和实现询问与删除功能
-
-
-
-
-
- 4 网站前台 章节内容:NUXT框架的基本使用方法, 十次方网站前台的搭建, 十次方网 站前台活动模块的功能, 十次方网站前台招聘模块的功能, 用户注册功能, js-cookie的使用, 微信扫码登陆的功能,nuxt嵌套路由的使用, 吐槽列表与详 细页, 发吐槽与评论功能, 问答频道功能,DataURL和阿里云OSS
-
-
-
-
-
- 5 系统设计与工程搭建 章节内容:十次方的需求分析, 十次方的系统设计,项目的前期准备工作(配 置JDK与 本地仓库), 十次方父模块与公共模块的搭建, 基础微服务-标签 CRUD的功能,掌握公共异常处理类
-
-
-
-
-
- 6 微服务功能开发 章节内容:基础微服务的开发, 招聘微服务的开发, 问答微服务的开发, 文 章微服务的开发,SpringCache与SpringDataRedis的使用
-
-
-
-
-
- 7 文档型数据库MongoDB 章节内容:MongoDb的特点和体系结构, 常用的MongoDB命令,使用运 用Java操作MongoDB, 使用SpringDataMongoDB完成吐槽微服务的开发, 使用SpringDataMongoDB完成评论系统的开发
-
-
-
-
-
- 8 消息中间件RabbitMQ与搜索微服务 章节内容:消息队列的应用场景以及RabbitMQ的主要概念,RabbitMQ安 装以及RabbitMQ三种模式的入门案例, 用户注册,能够将消息发送给 RabbitMQ, 短信微服务,能够接收消息并调用阿里云通信完成短信发送, 搜索 微服务
-
-
-
-
-
- 9 密码加密与微服务鉴权JWT 章节内容: BCrypt密码加密算法实现注册与登陆功能,常见的认证机制,JWT的组成 部分以及使用JWT的优点,使用JJWT创建和解析token,使用JJWT完成微服务鉴权
-
-
-
-
-
- 10 SpringCloud初入江湖&SpringCloud一统天下 章节内容: SpringCloud包含的主要框架,SpringCloud包含的主要框架,使用服务 发现组件Eureka,使用Feign实现服务间的调用,交友微服务开发,在项目中使用Hystrix 实现微服务熔断,在项目中使用Zuul实现微服务网关,在项目中使用SpringCloudConfig 实现配置集中管理,在项目中使用SpringCloudBus实现配置的在线更新
-
-
-
-
-
- 11 爬虫 章节内容:什么是网络爬虫,网络爬虫可以做什么,网络爬虫常用的技术,爬虫框架 Webmagic,十次方文章数据爬取,十次方用户数据爬取。
-
-
11. 1. 5. 7. 12 人工智能
章节内容:学习目标,人工智能与机器学习,智能分类,IK分词器,Deeplearning 4 j之
Word 2 VEC,构建卷积神经网络模型,实现智能分类。
11 2 十次方项目技术架构……………………………………………………………………………………………
11 3 十次方项目面试常问问题…………………………………………………………………………………….
11 3 1 对微服务有何了解?(了解)……………………………………………………………………
微服务,又称微服务 架构,是一种架构风格,它将应用程序构建为以业务
领域为模型的小型自治服务集合 。
通俗的来说就是将业务模块区分,不受编程语言限制,提供更好的可扩展性,独
立开发部署。一个业务模块的改动不会影响到其他业务。可以单独处理每个服务
组件的问题,而对整个应用程序没有影响或影响最小。
11 3 2 微服务架构有哪些优势?(了解)…………………………………………………………….
独立开发 – 所有微服务都可以根据各自的功能轻松开发
独立部署 – 基于其服务,可以在任何应用程序中单独部署它们
故障隔离 – 即使应用程序的一项服务不起作用,系统仍可继续运行
混合技术堆栈 – 可以使用不同的语言和技术来构建同一应用程序的不同
服务
粒度缩放 – 单个组件可根据需要进行缩放,无需将所有组件缩放在一起
11 3 3 微服务有哪些特点?(必会)……………………………………………………………………
解耦 – 系统内的服务很大程度上是分离的。因此,整个应用程序可以轻
松构建,更改和扩展
组件化 – 微服务被视为可以轻松更换和升级的独立组件
业务能力 – 微服务非常简单,专注于单一功能
自治 – 开发人员和团队可以彼此独立工作,从而提高速度
持续交付 – 通过软件创建,测试和批准的系统自动化,允许频繁发布软
件
责任 – 微服务不关注应用程序作为项目。相反,他们将应用程序视为他
们负责的产品
分散治理 – 重点是使用正确的工具来做正确的工作。这意味着没有标准
化模式或任何技术模式。开发人员可 以自由选择最有用的工具来解决他们的问
题
敏捷 – 微服务支持敏捷开发。任何新功能都可以快速开发并再次丢弃
11 3 4 微服务架构如何运作?(必会)……………………………………………………………….
客户端 – 来自不同设备的不同用户发送请求。
身份提供商 – 验证用户或客户身份并颁发安全令牌。
API网关 – 处理客户端请求。
静态内容 – 容纳系统的所有内容。
管理 – 在节点上平衡服务并识别故障。
服务发现 – 查找微服务之间通信路径的指南。
内容交付网络 – 代理服务器及其数据中心的分布式网络。
远程服务 – 启用驻留在IT设备网络上的远程访问信息。
11 3 5 微服务架构的优缺点是什么?(必会)…………………………………………………….
微服务架构的优点 微服务架构的缺点
自由使用不同的技术 增加故障排除挑战
每个微服务都侧重于单一功能 由于远程呼叫而增加延迟
支持单个可部署单元 增加了配置和其他操作的工作量
允许经常发布软件 难以保持交易安全
确保每项服务的安全性 艰难地跨越各种边界跟踪数据
微服务架构的优点 微服务架构的缺点
多个服务是并行开发和部署的 难以在服务之间进行编码
11. 3. 6 单片,SOA和微服务架构有什么区别?( 必会 )
单片架构 类似于大容器,其中应用程序的所有软件组件组装在一起并紧密
封装。
一个 面向服务 的架构是一种相互通信服务的集合。通信可以涉及简单的数
据传递,也可以涉及两个或多个协调某些活动的服务。
微服务 架构是一种架构风格,它将应用程序构建为以业务域为模型的小型
自治服务集合。
-
- 7 在使用微服务架构时,您面临哪些挑战?(必会)
开发一些较小的微服务听起来很容易,但开发它们时经常遇到的挑战如 下。 自动化组件 :难以自动化,因为有许多较小的组件。因此,对于每个组件, 我们必须遵循Build,Deploy和Monitor的各个阶段。 易感性 :将大量组件维护在一起变得难以部署,维护,监控和识别问题。 它需要在所有组件周围具有很好的感知能力。 配置管理 :有时在各种环境中维护组件的配置变得困难。 调试 :很难找到错误的每一项服务。维护集中式日志记录和仪表板以调试 问题至关重要。
11 3 8 SOA和微服务架构之间的主要区别是什么?(必会)…………………………….
SOA 微服务
11 3 9 什么是耦合?(了解)……………………………………………………………………………..
组件之间依赖关系强度的度量被认为是 耦合 。一个好的设计总是被认为具有
高内聚力 和 低耦合性 。
11 3 10 什么是Rest/Restful架构以及它的用途是什么?(了解)……………………..
Rest/RestfulWeb服务是一种帮助计算机系统通过Internet进行通信的
架构风格。这使得微服务更容易理解和实现。
微服务可以使用或不使用RESTfulAPI实现,但使用RESTfulAPI构建松散耦合
的微服务总是更容易。
遵循“ 尽可能多的共享 ”架构方法 遵循“尽可能少分享 ”的架构方法
重要性在于 业务功能重用 重要性在于“ 有界背景 ” 的概念
他们有 共同的 治理 和标准 他们专注于人们的 合作和其他选择的自由
使用 企业服务总线(ESB) 进行通信 简单的消息系统
它们支持 多种消息协议 他们使用 轻量级协议 ,如 HTTP/REST等。
多线程, 有更多的开销来处理I/O.
单线程通常使用EventLoop功能进行非锁定I/ O处理 最大化应用程序服务可重用性 专注于解耦 传统的关系数据库 更常用 现代 关系数据库 更常用 系统的变化需要修改整体 系统的变化是创造一种新的服务 DevOps/ContinuousDelivery正在 变得流行,但还不是主流
专注于DevOps/持续交付
Restful架构,就是目前最流行的一种互联网软件架构。它结构清晰.符合标 准.易 于理解.扩展方便,所以正得到越来越多网站的采用。REST这个词,是Roy ThomasFielding在他 2000 年的博士论文中提出的。 Rest是RepresentationalStateTransfer的缩写,翻译是”表现层状态转 化”。 可以 总结为一句话:REST是所有Web应用都应该遵守的架构设计指导原 则。 面向资源是Rest最明显的特征,对于同一个资源的一组不同的操作。资源 是服务器 上一个可命名的抽象概念,资源是以名词为核心来组织的,首先关注 的是名词。REST要求,必须通过统一的接口来对资源执行各种操作。对于每个 资源只能执行一组有限的操 作。 7 个HTTP方法:GET/POST/PUT/DELETE/PATCH/HEAD/OPTIONS。
11 3 11 你对SpringBoot有什么了解?(必会)………………………………………………..
事实上,随着新功能的增加,弹簧变得越来越复杂。如果必须启动新的
spring项目,则必须添加构建路径或添加maven依赖项,配置应用程序服务器, 添加spring配置。所以一切都必须从头开始。 SpringBoot是解决这个问题的方法。使用SpringBoot可以避免所有样板代码 和XML配置。快速构建项目。感觉是SpringMVC精简版。
11 3 12 什么是Spring引导的执行器?(必会)…………………………………………………
SpringBoot执行程序提供了restfulWeb服务,以访问生产环境中运行应 用程序的当前状态。在执行器的帮助下,您可以检查各种指标并监控您的应用程 序。
11 3 13 什么是SpringCloud?(必会)…………………………………………………………….
根据SpringCloud的官方网站,SpringCloud为开发人员提供了快速构建 分布式系统中一些常见模式的工具(例如配置管理,服务发现,断路器,智能路 由,领导选举,分布式会话,集群状态)。
11 3 14 SpringCloud解决了哪些问题?(必会)…………………………………………….
在使用SpringBoot开发分布式微服务时,我们面临的问题很少由 SpringCloud解决。 与分布式系统相关的复杂性 – 包括网络问题,延迟开销,带宽问题,安全问题。 处理服务发现的能力 – 服务发现允许集群中的进程和服务找到彼此并进行通 信。 解决冗余问题 – 冗余问题经常发生在分布式系统中。 负载平衡 – 改进跨多个计算资源(例如计算机集群,网络链接,中央处理单元) 的工作负载分布。 减少性能问题 – 减少因各种操作开销导致的性能问题。
11 3 15 在SpringMVC应用程序中使用WebMvcTest注释有什么用处?(必会)
在测试目标只关注SpringMVC组件的情况下, WebMvcTest 注释用于单元测 试SpringMVC应用程序。在上面显示的快照中,我们只想启动 ToTestController。执行此单元测试时,不会启动所有其他控制器和映射。
11 3 16 你能否给出关于休息和微服务的要点?(必会)…………………………………….
休息
虽然您可以通过多种方式实现微服务,但RESToverHTTP是实现微服务的 一种方式。REST还可用于其他应用程序,如Web应用程序,API设计和MVC 应用程序,以提供业务数据。 微服务 微服务是一种体系结构,其中系统的所有组件都被放入单独的组件中,这些 组件可以单独构建,部署和扩展。微服务的某些原则和最佳实践有助于构建弹性 应用程序。 简而言之,您可以说REST是构建微服务的媒介。
11 3 17 什么是不同类型的微服务测试?(必会)……………………………………………….
在使用微服务时,由于有多个微服务协同工作,测试变得非常复杂。因此,
测试分为不同的级别。
在 底层 ,我们有面向技术的测试,如单元测试和性能测试。这些是完全自
动化的。
在 中间层面 ,我们进行了诸如压力测试和可用性测试之类的探索性测试。
在 顶层 ,我们的 验收测试数量很少。这些验收测试有助于利益相关者理
解和验证软件功能。
11 3 18 您对DistributedTransaction有何了解?(必会)………………………………
分布式事务 是指单个事件导致两个或多个不能以原子方式提交的单独数据
源的突变的任何情况。在微服务的世界中,它变得更加复杂,因为每个服务都是
一个工作单元,并且大多数时候多个服务必须协同工作才能使业务成功。
11 3 19 什么是Idempotence以及它在哪里使用?(必会)………………………………
幂等 性是能够以这样的方式做两次事情的特性,即最终结果将保持不变,即
好像它只做了一次。
用法 :在远程服务或数据源中使用 Idempotence,这样当它多次接收指令 时,它只处理指令一次。
11 3 20 什么是有界上下文?(必会)…………………………………………………………………
有界上下文是域驱动设计的核心模式。DDD战略设计部门的重点是处理大
型模型和团队。DDD通过将大型模型划分为不同的有界上下文并明确其相互关
系来处理大型模型。
11 3 21 什么是双因素身份验证?(必会)…………………………………………………………..
双因素身份验证为帐户登录过程启用第二级身份验证。
因此,假设用户必须只输入用户名和密码,那么这被认为是单因素身份验证。
11 3 22 双因素身份验证的凭据类型有哪些?(了解)………………………………………..
11 3 23 什么是客户证书?(了解)…………………………………………………………………….
客户端系统用于向远程服务器发出经过身份验证的请求的一种数字证书称
为 客户端证书 。客户端证书在许多相互认证设计中起着非常重要的作用,为请求
者的身份提供了强有力的保证。比如JWT鉴权等。
11 4 十次方技术点………………………………………………………………………………………………………
11 4 1 MongoDB(高薪常问)……………………………………………………………………………
-
-
- 1 什么是MongoDB
-
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在 为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个介于关 系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关 系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可
以存储比较复杂的数据类型。
-
-
- 2 MongoDB特点
-
Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向 对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且 还支持对数据建立索引。 它的特点是高性能.易部署.易使用,存储数据非常方便。主要功能特性有:
-
面向集合存储,易存储对象类型的数据。
-
模式自由。
-
支持动态查询。
-
支持完全索引,包含内部对象。
-
支持复制和故障恢复。
-
使用高效的二进制数据存储,包括大型对象(如视频等)。
-
自动处理碎片,以支持云计算层次的扩展性。
-
支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
-
文件存储格式为BSON(一种JSON的扩展)。
-
-
- 3 MongoDB体系结构
-
MongoDB 的逻辑结构是一种层次结构。主要由:文档(document).集合 (collection).数据库(database)这三部分组成的。逻辑结构是面向用户的,用户 使用 MongoDB 开发应用程序使用的就是逻辑结构。
1. MongoDB 的文档(document),相当于关系数据库中的一
行记录。
2. 多个文档组成一个集合(collection),相当于关系数据库的表。
3. 多个集合(collection),逻辑上组织在一起,就是数据库
(database)。
4. 一个 MongoDB 实例支持多个数据库(database)。
-
-
- 4 MongoDB数据类型
-
11 4 2 即时通讯(高薪常问)……………………………………………………………………………..
-
-
- 1 什么是即时通信?
-
即时通信(InstantMessaging,简称IM)是一个允许两人或多人使用网 络实时的传递文字消息.文件.语音与视频交流。即时通讯技术应用于需要 实时 收 发消息的业务场景。即时通讯使用的是长连接。
-
-
- 2 什么是短连接?
-
客户端和服务器每进行一次通讯,就建立一次连接,通讯结束就中断连接。 HTTP是一个简单的请求-响应协议,它通常运行在TCP之上。HTTP/ 1. 0 使用 的TCP默认是短连接。
-
-
- 3 什么是长连接?
-
是指在建立连接后可以连续多次发送数据,直到双方断开连接。
-
- 4 短连接和长连接的区别?
-
-
- 1 通讯流程
-
短连接:创建连接 -> 传输数据 -> 关闭连接 长连接:创建连接 -> 传输数据 -> 保持连接 -> 传输数据 -> …… -> 关闭连接
-
-
- 2 适用场景
-
短连接:并发量大,数据交互不频繁情况
长连接:数据交互频繁,点对点的通讯
-
-
- 3 通讯方式
-
方式 说明
短连接 我跟你发信息,必须等到你回复我或者等了一会等不下去了,就结束通讯了
方式 说明
长连接
我跟你发信息,一直保持通讯,在保持通讯这个时段,我去做其他事情的当中你回复我了,我能立刻你回复了我什么,然后可以回应或者不回应,继
续做事
11 4 3 websocket协议(了解)………………………………………………………………………….
-
- 3. 1 何为websocket协议?
WebSocket 是 HTML 5 开始提供的一种在单个 TCP 连接上进行全双工通讯 的协议。 何谓全双工:全双工(FullDuplex)是通讯传输的一个术语。双方在通信时允 许数据在两个方向上同时传输,它在能力上相当于两个单工通信方式的结合。全 双工指可以同时进行信号的双向传输。指A→B的同时B→A,就像是双向车道。 单工就就像是汽车的单行道,是在只允许甲方向乙方传送信息,而乙方不能向甲 方传送 。 在 WebSocket中,浏览器和服务器只需要完成一次握手,就可以创建持久性 的连接,并进行双向数据传输。 在推送功能的实现技术上,相比使用Ajax 定时轮询的方式(setInterval), WebSocket 更节省服务器资源和带宽。 服务器向客户端发送数据的功能是websocket协议的典型使用场景
-
-
- 2 websocket常用事件方法?
-
11 4 4 接口加密&加密方式(高薪常问)…………………………………………………………….
-
-
- 1 摘要算法
-
消息摘要是把任意长度的输入揉和而产生长度固定的信息。 消息摘要算法的主要特征是加密过程不需要密钥,并且经过加密的数据 无法被解密,只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的 密文。消息摘要算法不存在密钥的管理与分发问题,适合于分布式网络上使用。 消息摘要的主要特点有: 无论输入的消息有多长,计算出来的消息摘要的长度总是固定的。 消息摘要看起来是“随机的”。这些数据看上去是胡乱的杂凑在一起的。 只要输入的消息不同,对其进行摘要后产生的摘要消息也必不相同;但相同 的输入必会产生相同的输出。 只能进行正向的消息摘要,而无法从摘要中恢复出任何消息,甚至根本就找 不到任何与原信息相关的信息。
虽然“碰撞”是肯定存在的,但好的摘要算法很难能从中找到“碰撞”。
即无法找到两条不同消息,但是它们的摘要相同。
常见的摘要算法:CRC.MD 5 .SHA等
-
-
- 2 对称加密
-
加密和解密使用相同密钥的加密算法。 对称加密的特点: 速度快,通常在消息发送方需要加密大量数据时使用。 密钥是控制加密及解密过程的指令。 算法是一组规则,规定如何进行加密和解密。 典型应用场景:离线的大量数据加密(用于存储的) 常用的加密算法: DES. 3 DES. AES .TDEA.Blowfish.RC 2 .RC 4 .RC 5 .IDEA.SKIPJACK等。 加密的安全性不仅取决于加密算法本身,密钥管理的安全性更是重要。如何 把密钥安全地传递到解密者手上就成了必须要解决的问题。
-
-
- 3 非对称加密
-
非对称加密算法是一种 密钥 的保密方法,加密和解密使用两个不同的密 钥,公开密钥(publickey:简称公钥)和私有密钥(privatekey:简称私钥)。公 钥与私钥是一对,如果用公钥对数据进行加密,只有用对应的私钥才能解密。 非对称加密算法的特点: 算法强度复杂
加密解密速度没有对称密钥算法的速度快
经典应用场景:数字签名(公钥加密,私钥验证)
常用的算法: RSA .Elgamal.背包算法.Rabin.D-H.ECC(椭圆曲线加密算法)。
-
-
- 4 数字签名
-
数字签名(又称公钥数字签名)是一种类似写在纸上的普通的物理签名, 是使用了公钥加密领域的技术实现,用于鉴别数字信息的方法。 数字签名通常使用私钥生成签名,使用公钥验证签名。 签名及验证过程:
- 发送方用一个哈希函数(例如MD 5 )从报文文本中生成报文摘 要,然后用自己的私钥对这个摘要进行加密
- 将加密后的摘要作为报文的数字签名和报文一起发送给接收方
- 接收方用与发送方一样的哈希函数从接收到的原始报文中计算 出报文摘要,
- 接收方再用发送方的公用密钥来对报文附加的数字签名进行解 密
- 如果这两个摘要相同.接收方就能确认该数字签名是发送方的。 数字签名验证的两个作用: 确定消息确实是由发送方签名并发出来的 确定消息的完整性
11 4 5 消息通知(必会)…………………………………………………………………………………….
-
-
- 1 消息通知的业务场景
-
消息通知微服务的定位是“平台内”的“消息”功能,分为全员消息,订阅 类消息,点对点消息。例如系统通知,私信,@类消息 全员消息 系统通知,活动通知,管理员公告等全部用户都会收到的消息 订阅类消息 关注某一类数据的用户,该类数据有更新时向用户发送的消息。例如关注某 位大v的微博,公众号,订阅某位知名作家的专栏 点对点消息 某位用户对另外一位用户进行操作后,系统向被操作的用户发送的消息。例 如点赞,发红包。
-
-
- 2 消息通知与即时通讯的区别
-
-
-
- 3 消息通知存在的问题
-
-
-
-
- 1 数据库访问压力大
-
-
用户的通知消息和新通知提醒数据都放在数据库中,数据库的读写操作频 繁,尤其是tb_notice_refresh表,访问压力大。
-
-
-
- 2 服务器性能压力大
-
-
采用页面轮询调接口的方式实现服务器向用户推送消息通知,服务器的接口 访问压力大。
-
-
-
- 3 改进的方法
-
-
使用 rabbitmq 实现新消息提醒数据的缓存功能,替代tb_notice_refresh表 使用全双工长连接的方式实现服务器向用户推送最新的消息通知,替换轮询
- 页面使用websocket
- 微服务端使用异步高性能框架netty
11 4 6 Redis分布式缓存(必会、高薪常问)………………………………………………………
-
-
- 1 Redis读写分离
-
单机Redis的读写速度非常快,能够支持大量用户的访问。虽然Redis的 性能很高,但是对于大型网站来说,每秒需要获取的数据远远超过单台Redis 服务所能承受的压力,所以我们迫切需要一种方案能够解决单台Redis服务性能 不足的问题。
-
-
- 2 Redis性能测试
-
-
-
-
- 1 Redis-benchmark
-
-
Redis-benchmark是官方自带的Redis性能测试工具,用来测试Redis在 当前环境下的读写性能。我们在使用Redis的时候,服务器的硬件配置.网络状 况.测试环境都会对Redis的性能有所影响,我们需要对Redis实时测试以确定 Redis的实际性能。
-
-
-
- 2 TPS.QPS.RT
-
-
响应时间(RT) 响应时间是指系统对请求作出响应的时间。 直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整 地记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能, 而不同功能的业务逻辑也千差万别,因而不同功能的响应时间也不尽相同。 在讨论一个系统的响应时间时,通常是指该系统所有功能的平均时间或者所 有功能的最大响应时间。吞吐量TPS吞吐量是指系统在单位时间内处理请求的 数量。 对于一个多用户的系统,如果只有一个用户使用时系统的平均响应时间是t, 当有你n个用户使用时,每个用户看到的响应时间通常并不是n×t,而往往比n ×t小很多。这是因为在处理单个请求时,在每个时间点都可能有许多资源被闲 置,当处理多个请求时,如果资源配置合理,每个用户看到的平均响应时间并不 随用户数的增加而线性增加。
实际上,不同系统的平均响应时间随用户数增加而增长的速度也不大相同,
这也是采用吞吐量来度量并发系统的性能的主要原因。一般而言,吞吐量是一个
比较通用的指标,两个具有不同用户数和用户使用模式的系统,如果其最大吞吐
量基本一致,则可以判断两个系统的处理能力基本一致。
举例来说系统能处理的
并发数 100
响应时间(RT) 100 ms 每秒的TPS 一个并发, 1 秒就是 1000 / 100 = 10 TPS 十个并发, 1 秒就是 1000 / 100 * 10 = 100 TPS 百个并发, 1 秒就是 1000 / 100 * 100 = 1000 TPS 以上是资源配置合理的情况 如果系统能处理 100 并发,却有 200 个并发请求 1 秒就是 1000 /( 100 之前的响应时间+系统处理多出的并发消耗掉的时间 100 )* 100 = 500 TPS 总结:吞吐量必然和当前系统是否配置合理有关,超过最大承受后,吞吐量 会下降,生活中想想颐和园的售票处 每秒查询率QPS 每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量 多少的衡量标准,在互联网中,经常用每秒查询率来衡量服务器的性能。对应 fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
TPS和QPS区别:
TPS牵扯到系统的整体性能,如果只是想了解Redis的性能就会询问QPS不牵 扯,系统架构,业务性能等因素
-
-
- 3 Redis同步原理
-
Redis的主从复制,主服务器执行写操作命令,从服务器会通过主服务器的 数据的变化,同步数据到从服务器。但是如果主服务器下线,从服务器无法连接 主服务器,那么数据同步该如何拿到不能连接主服务器这段时间的命令呢? 主从复制中的主从服务器双方的数据库将保存相同的数据,概念上将这种现 象称作数据库状态一致。 Redis数据库持久化有两种方式:RDB全量持久化和AOF增量持久化。 通过上面的例子,我们知道Redis的主从复制,主服务器执行写操作命 令,从服务器会通过主服务器的数据的变化,同步数据到从服务器。但是如果主 服务器下线,从服务器无法连接主服务器,那么数据同步该如何拿到不能连接主 服务器这段时间的命令呢? 主从复制中的主从服务器双方的数据库将保存相同的数据,概念上将这 种现象称作 数据库状态一致 。 Redis数据库持久化有两种方式:RDB全量持久化和AOF增量持久化。
-
-
- 4 Redis的高可用Sentinel
-
高可用是分布式系统架构设计中必须考虑的因素之一,它是通过架构设计减 少系统不能提供服务的时间。保证高可用通常遵循下面几点:
1. 单点是系统高可用的大敌,应该尽量在系统设计的过程中避免单点。
2. 通过架构设计而保证系统高可用的,其核心准则是:冗余。
3. 每次出现故障需要人工介入恢复,会增加系统不可用的时间,实现自
动故障转移。
11 4 7 JUC多线程(了解)………………………………………………………………………………….
-
-
- 1 认识多线程
-
一个采用了多线程技术的应用程序可以更好地利用系统资源。其主要优势在 于充分利用了CPU的空闲时间片,可以用尽可能少的时间来对用户的要求做出 响应,使得进程的整体运行效率得到较大提高,同时增强了应用程序的灵活性。 更为重要的是,由于同一进程的所有线程是共享同一内存,所以不需要特殊 的数据传送机制,不需要建立共享存储区或共享文件,从而使得不同任务之间的 协调操作与运行.数据的交互.资源的分配等问题更加易于解决。
-
-
- 2 什么是线程?
-
进程内部的一个独立执行单元;一个进程可以同时并发的运行多个线程,可 以理解为一个进程便相当于一个单 CPU 操作系统,而线程便是这个系统中运行 的多个任务。
-
-
- 3 什么是进程?
-
是指一个内存中运行的应用程序,每个进程都有一个独立的内存空间,一个 应用程序可以同时运行多个进程;进程也是程序的一次执行过程,是系统运行程 序的基本单位;系统运行一个程序即是一个进程从创建.运行到消亡的过程。
-
-
- 4 进程与线程的区别?
-
进程:有独立的内存空间,进程中的数据存放空间(堆空间和栈空间)是独 立的,至少有一个线程。 线程:堆空间是共享的,栈空间是独立的,线程消耗的资源比进程小的多。 注意:
-
因为一个进程中的多个线程是并发运行的,那么从微观角度看也 是有先后顺序的,哪个线程执行完全取决于 CPU 的调度,程序员是不能 完全控制的(可以设置线程优先级,有限度的控制顺序)。而这也就造成 的多线程的随机性。
-
Java程序的进程里面至少包含两个线程,主线程也就是 main() 方法线程,另外一个是垃圾回收机制线程。每 当使用 java 命令执行一 个类时,实际上都会启动一个 JVM,每一个 JVM 实际上就是在操作系 统中启动了一个 线程,java 本身具备了垃圾的收集机制,所以在 Java 运行时至少会启动两个线程。
-
由于创建一个线程的开销比创建一个进程的开销小的多,那么我 们在开发多任务运行的时候,通常考虑创建 多线程,而不是创建多进程。
-
-
- 4 什么是线程安全?
-
线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量. 静态变量只有读操作,而无写 操作,一般来说,这个全局变量是线程安全的; 若有多个线程同时执行写操作,一般都需要考虑线程同步, 否则的话就可能影 响线程安全。
-
-
- 5 什么时候使用线程同步?
-
当我们使用多个线程访问同一资源的时候,且多个线程中对资源有写的操 作,就容易出现线程安全问题。 要解决上述多线程并发访问一个资源的安全问 题,Java中提供了同步机制(synchronized)来解决。
-
-
- 6 线程同步机制有哪些?
-
同步代码块.同步方法.lock锁等。
-
-
- 7 对死锁的理解?
-
多线程死锁:同步中嵌套同步,导致锁无法释放。
死锁解决办法:不要在同步中嵌套同步
-
-
- 8 多线程并发的 3 个特性?
-
原子性,可见性和有序性。 原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任 何因素打断,要么就都不执行
可见性:当多个线程访问同一个变量时,一个线程修改了这个变量的值,其
他线程能够立即看得到修改的值
有序性:程序执行的顺序按照代码的先后顺序执行
-
-
- 9 锁优化
-
synchronized是重量级锁,效率不高。但在JDK 1. 6 中对synchronize的 实现进行了各种优化,使得它显得不是那么重了。JDK 1. 6 对锁的实现引入了大 量的优化,如自旋锁.适应性自旋锁.锁消除.锁粗化.偏向锁.轻量级锁等技术来减 少锁操作的开销。 锁主要存在四种状态,依次是:无锁状态.偏向锁状态.轻量级锁状态.重 量级锁状态,他们会随着竞争的激烈而逐渐升级。 注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-
-
- 10 自旋锁
-
线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对 CPU来说是一件负担很重的工作,势必会给系统的并发性能带来很大的压力。 同时我们发现在许多应用上面,对象锁的锁状态只会持续很短一段时间,为了这 一段很短的时间频繁地阻塞和唤醒线程是非常不值得的。所以引入自旋锁。 所谓自旋锁,就是让该线程等待一段时间,不会被立即挂起,看持有锁 的线程是否会很快释放锁。怎么等待呢?执行一段无意义的循环即可(自旋)。 自旋等待不能替代阻塞,虽然它可以避免线程切换带来的开销,但是它 占用了处理器的时间。如果持有锁的线程很快就释放了锁,那么自旋的效率就非
常好,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工
作,典型的占着茅坑不拉屎,这样反而会带来性能上的浪费。所以说,自旋等待
的时间(自旋的次数)必须要有一个限度,如果自旋超过了定义的时间仍然没有
获取到锁,则应该被挂起。
自旋锁在JDK 1. 4. 2 中引入,默认关闭,但是可以使用
- XX:+UseSpinning开开启,在JDK 1. 6 中默认开启。同时自旋的默认次数为 10 次,可以通过参数-XX:PreBlockSpin来调整; 如果通过参数-XX:preBlockSpin来调整自旋锁的自旋次数,会带来诸多 不便。假如我将参数调整为 10 ,但是系统很多线程都是等你刚刚退出的时候就 释放了锁(假如你多自旋一两次就可以获取锁),你是不是很尴尬。于是JDK 1. 6 引入自适应的自旋锁,让虚拟机会变得越来越聪明。
-
-
- 11 适应自旋锁
-
JDK 1. 6 引入了更加聪明的自旋锁,即自适应自旋锁。所谓自适应就意 味着自旋的次数不再是固定的,它是由前一次在同一个锁上的自旋时间及锁的拥 有者的状态来决定。它怎么做呢?线程如果自旋成功了,那么下次自旋的次数会 更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功, 那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋 能够成功的,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋 过程,以免浪费处理器资源。 有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程 序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
-
-
- 12 锁消除
-
为了保证数据的完整性,我们在进行操作时需要对这部分操作进行同步 控制,但是在有些情况下,JVM检测到不可能存在共享数据竞争,这是JVM会 对这些同步锁进行锁消除。锁消除的依据是逃逸分析的数据支持。 如果不存在竞争,为什么还需要加锁呢?所以锁消除可以节省毫无意义 的请求锁的时间。变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定, 但是对于我们程序员来说这还不清楚么?我们会在明明知道不存在数据竞争的 代码块前加上同步吗?但是有时候程序并不是我们所想的那样?我们虽然没有 显示使用锁,但是我们在使用一些JDK的内置API时,如 StringBuffer.Vector.HashTable等,这个时候会存在隐形的加锁操作。比如 StringBuffer的append()方法,Vector的add()方法:
-
-
- 13 锁粗化
-
在使用同步锁的时候,需要让同步块的作用范围尽可能小,仅在共享数 据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作量尽可能 缩小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。 在大多数的情况下,上述观点是正确的。但是如果一系列的连续加锁解 锁操作,可能会导致不必要的性能损耗,所以引入锁粗化的概念。 锁粗话概念比较好理解,就是将多个连续的加锁.解锁操作连接在一起, 扩展成一个范围更大的锁。如上面实例:vector每次add的时候都需要加锁操 作,JVM检测到对同一个对象(vector)连续加锁.解锁操作,会合并一个更大 范围的加锁.解锁操作,即加锁解锁操作会移到for循环之外。
-
-
- 14 偏向锁 轻量级锁的加锁解锁操作是需要依赖多次CAS原子指令的。而偏向锁只 需要检查是否为偏向锁.锁标识为以及ThreadID即可,可以减少不必要的CAS 操作。
-
-
-
- 15 轻量级锁 引入轻量级锁的主要目的是在没有多线程竞争的前提下,减少传统的重 量级锁使用操作系统互斥量产生的性能消耗。当关闭偏向锁功能或者多个线程竞 争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁。轻量级锁主要使 用CAS进行原子操作。 但是对于轻量级锁,其性能提升的依据是“对于绝大部分的锁,在整个 生命周期内都是不会存在竞争的”,如果打破这个依据则除了互斥的开销外,还 有额外的CAS操作,因此在有多线程竞争的情况下,轻量级锁比重量级锁更慢。
-
-
-
- 16 重量锁 重量级锁通过对象内部的监视器(monitor)实现,其中monitor的本 质是依赖于底层操作系统的MutexLock(互斥锁)实现,操作系统实现线程之 间的切换需要从用户态到内核态的切换,切换成本非常高。
-